 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongitudinal Study on Social and Emotional Use of AI Conversational Agent
Apr 19, 2025Development in digital technologies has continuously reshaped how individuals seek and receive social and emotional support. While online platforms and communities have long served this need, the increased integration of general-purpose conversational AI into daily lives has introduced new dynamics in how support is provided and experienced. Existing research has highlighted both benefits (e.g., wider access to well-being resources) and potential risks (e.g., over-reliance) of using AI for support seeking. In this five-week, exploratory study, we recruited 149 participants divided into two usage groups: a baseline usage group (BU, n=60) that used the internet and AI as usual, and an active usage group (AU, n=89) encouraged to use one of four commercially available AI tools (Microsoft Copilot, Google Gemini, PI AI, ChatGPT) for social and emotional interactions. Our analysis revealed significant increases in perceived attachment towards AI (32.99 percentage points), perceived AI empathy (25.8 p.p.), and motivation to use AI for entertainment (22.90 p.p.) among the AU group. We also observed that individual differences (e.g., gender identity, prior AI usage) influenced perceptions of AI empathy and attachment. Lastly, the AU group expressed higher comfort in seeking personal help, managing stress, obtaining social support, and talking about health with AI, indicating potential for broader emotional support while highlighting the need for safeguards against problematic usage. Overall, our exploratory findings underscore the importance of developing consumer-facing AI tools that support emotional well-being responsibly, while empowering users to understand the limitations of these tools.
From Lived Experience to Insight: Unpacking the Psychological Risks of Using AI Conversational Agents
Dec 12, 2024Recent gain in popularity of AI conversational agents has led to their increased use for improving productivity and supporting well-being. While previous research has aimed to understand the risks associated with interactions with AI conversational agents, these studies often fall short in capturing the lived experiences. Additionally, psychological risks have often been presented as a sub-category within broader AI-related risks in past taxonomy works, leading to under-representation of the impact of psychological risks of AI use. To address these challenges, our work presents a novel risk taxonomy focusing on psychological risks of using AI gathered through lived experience of individuals. We employed a mixed-method approach, involving a comprehensive survey with 283 individuals with lived mental health experience and workshops involving lived experience experts to develop a psychological risk taxonomy. Our taxonomy features 19 AI behaviors, 21 negative psychological impacts, and 15 contexts related to individuals. Additionally, we propose a novel multi-path vignette based framework for understanding the complex interplay between AI behaviors, psychological impacts, and individual user contexts. Finally, based on the feedback obtained from the workshop sessions, we present design recommendations for developing safer and more robust AI agents. Our work offers an in-depth understanding of the psychological risks associated with AI conversational agents and provides actionable recommendations for policymakers, researchers, and developers.
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Jul 18, 2024


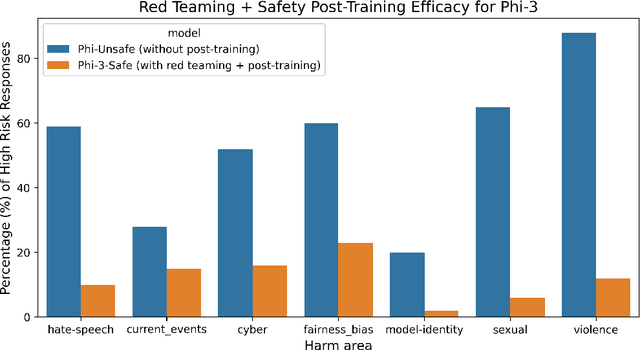
Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.