 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual Embeddings via Multi-Way Parallel Text Alignment
Feb 25, 2026Multilingual pretraining typically lacks explicit alignment signals, leading to suboptimal cross-lingual alignment in the representation space. In this work, we show that training standard pretrained models for cross-lingual alignment with a multi-way parallel corpus in a diverse pool of languages can substantially improve multilingual and cross-lingual representations for NLU tasks. We construct a multi-way parallel dataset using translations of English text from an off-the-shelf NMT model for a pool of six target languages and achieve strong cross-lingual alignment through contrastive learning. This leads to substantial performance gains across both seen and unseen languages for multiple tasks from the MTEB benchmark evaluated for XLM-Roberta and multilingual BERT base models. Using a multi-way parallel corpus for contrastive training yields substantial gains on bitext mining (21.3%), semantic similarity (5.3%), and classification (28.4%) compared to English-centric (En-X) bilingually parallel data, where X is sampled from a pool of multiple target languages. Furthermore, finetuning mE5 model on a small dataset with multi-way parallelism significantly improves bitext mining compared to one without, underscoring the importance of multi-way cross-lingual supervision even for models already pretrained for high-quality sentence embeddings.
Human-Aligned MLLM Judges for Fine-Grained Image Editing Evaluation: A Benchmark, Framework, and Analysis
Feb 13, 2026Evaluating image editing models remains challenging due to the coarse granularity and limited interpretability of traditional metrics, which often fail to capture aspects important to human perception and intent. Such metrics frequently reward visually plausible outputs while overlooking controllability, edit localization, and faithfulness to user instructions. In this work, we introduce a fine-grained Multimodal Large Language Model (MLLM)-as-a-Judge framework for image editing that decomposes common evaluation notions into twelve fine-grained interpretable factors spanning image preservation, edit quality, and instruction fidelity. Building on this formulation, we present a new human-validated benchmark that integrates human judgments, MLLM-based evaluations, model outputs, and traditional metrics across diverse image editing tasks. Through extensive human studies, we show that the proposed MLLM judges align closely with human evaluations at a fine granularity, supporting their use as reliable and scalable evaluators. We further demonstrate that traditional image editing metrics are often poor proxies for these factors, failing to distinguish over-edited or semantically imprecise outputs, whereas our judges provide more intuitive and informative assessments in both offline and online settings. Together, this work introduces a benchmark, a principled factorization, and empirical evidence positioning fine-grained MLLM judges as a practical foundation for studying, comparing, and improving image editing approaches.
Crossing Borders: A Multimodal Challenge for Indian Poetry Translation and Image Generation
Nov 18, 2025Indian poetry, known for its linguistic complexity and deep cultural resonance, has a rich and varied heritage spanning thousands of years. However, its layered meanings, cultural allusions, and sophisticated grammatical constructions often pose challenges for comprehension, especially for non-native speakers or readers unfamiliar with its context and language. Despite its cultural significance, existing works on poetry have largely overlooked Indian language poems. In this paper, we propose the Translation and Image Generation (TAI) framework, leveraging Large Language Models (LLMs) and Latent Diffusion Models through appropriate prompt tuning. Our framework supports the United Nations Sustainable Development Goals of Quality Education (SDG 4) and Reduced Inequalities (SDG 10) by enhancing the accessibility of culturally rich Indian-language poetry to a global audience. It includes (1) a translation module that uses an Odds Ratio Preference Alignment Algorithm to accurately translate morphologically rich poetry into English, and (2) an image generation module that employs a semantic graph to capture tokens, dependencies, and semantic relationships between metaphors and their meanings, to create visually meaningful representations of Indian poems. Our comprehensive experimental evaluation, including both human and quantitative assessments, demonstrates the superiority of TAI Diffusion in poem image generation tasks, outperforming strong baselines. To further address the scarcity of resources for Indian-language poetry, we introduce the Morphologically Rich Indian Language Poems MorphoVerse Dataset, comprising 1,570 poems across 21 low-resource Indian languages. By addressing the gap in poetry translation and visual comprehension, this work aims to broaden accessibility and enrich the reader's experience.
Decomposition-Enhanced Training for Post-Hoc Attributions In Language Models
Oct 29, 2025Large language models (LLMs) are increasingly used for long-document question answering, where reliable attribution to sources is critical for trust. Existing post-hoc attribution methods work well for extractive QA but struggle in multi-hop, abstractive, and semi-extractive settings, where answers synthesize information across passages. To address these challenges, we argue that post-hoc attribution can be reframed as a reasoning problem, where answers are decomposed into constituent units, each tied to specific context. We first show that prompting models to generate such decompositions alongside attributions improves performance. Building on this, we introduce DecompTune, a post-training method that teaches models to produce answer decompositions as intermediate reasoning steps. We curate a diverse dataset of complex QA tasks, annotated with decompositions by a strong LLM, and post-train Qwen-2.5 (7B and 14B) using a two-stage SFT + GRPO pipeline with task-specific curated rewards. Across extensive experiments and ablations, DecompTune substantially improves attribution quality, outperforming prior methods and matching or exceeding state-of-the-art frontier models.
Poetry in Pixels: Prompt Tuning for Poem Image Generation via Diffusion Models
Jan 10, 2025



The task of text-to-image generation has encountered significant challenges when applied to literary works, especially poetry. Poems are a distinct form of literature, with meanings that frequently transcend beyond the literal words. To address this shortcoming, we propose a PoemToPixel framework designed to generate images that visually represent the inherent meanings of poems. Our approach incorporates the concept of prompt tuning in our image generation framework to ensure that the resulting images closely align with the poetic content. In addition, we propose the PoeKey algorithm, which extracts three key elements in the form of emotions, visual elements, and themes from poems to form instructions which are subsequently provided to a diffusion model for generating corresponding images. Furthermore, to expand the diversity of the poetry dataset across different genres and ages, we introduce MiniPo, a novel multimodal dataset comprising 1001 children's poems and images. Leveraging this dataset alongside PoemSum, we conducted both quantitative and qualitative evaluations of image generation using our PoemToPixel framework. This paper demonstrates the effectiveness of our approach and offers a fresh perspective on generating images from literary sources.
Beyond Logit Lens: Contextual Embeddings for Robust Hallucination Detection & Grounding in VLMs
Nov 28, 2024The rapid development of Large Multimodal Models (LMMs) has significantly advanced multimodal understanding by harnessing the language abilities of Large Language Models (LLMs) and integrating modality-specific encoders. However, LMMs are plagued by hallucinations that limit their reliability and adoption. While traditional methods to detect and mitigate these hallucinations often involve costly training or rely heavily on external models, recent approaches utilizing internal model features present a promising alternative. In this paper, we critically assess the limitations of the state-of-the-art training-free technique, the logit lens, in handling generalized visual hallucinations. We introduce a refined method that leverages contextual token embeddings from middle layers of LMMs. This approach significantly improves hallucination detection and grounding across diverse categories, including actions and OCR, while also excelling in tasks requiring contextual understanding, such as spatial relations and attribute comparison. Our novel grounding technique yields highly precise bounding boxes, facilitating a transition from Zero-Shot Object Segmentation to Grounded Visual Question Answering. Our contributions pave the way for more reliable and interpretable multimodal models.
Enhancing Post-Hoc Attributions in Long Document Comprehension via Coarse Grained Answer Decomposition
Sep 25, 2024
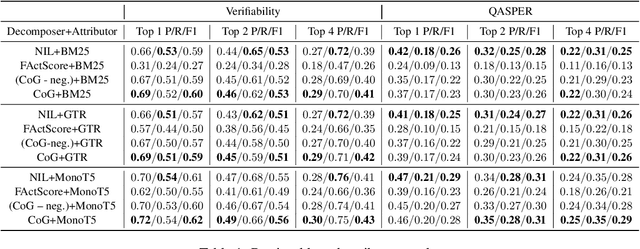
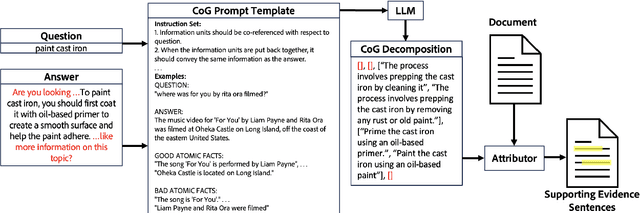
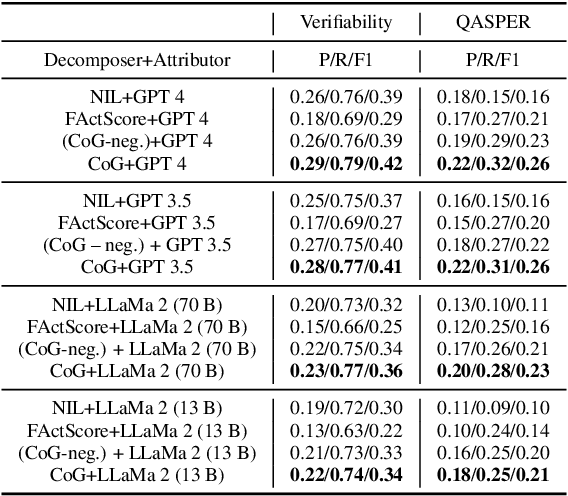
Accurately attributing answer text to its source document is crucial for developing a reliable question-answering system. However, attribution for long documents remains largely unexplored. Post-hoc attribution systems are designed to map answer text back to the source document, yet the granularity of this mapping has not been addressed. Furthermore, a critical question arises: What precisely should be attributed, with an emphasis on identifying the information units within an answer that necessitate grounding? In this paper, we propose and investigate a novel approach to the factual decomposition of generated answers for attribution, employing template-based in-context learning. To accomplish this, we utilize the question and integrate negative sampling during few-shot in-context learning for decomposition. This approach enhances the semantic understanding of both abstractive and extractive answers. We examine the impact of answer decomposition by providing a thorough examination of various attribution approaches, ranging from retrieval-based techniques to LLM-based attributors.
GenSco: Can Question Decomposition based Passage Alignment improve Question Answering?
Jul 14, 2024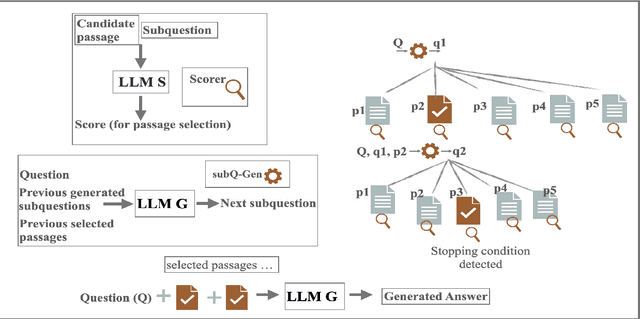
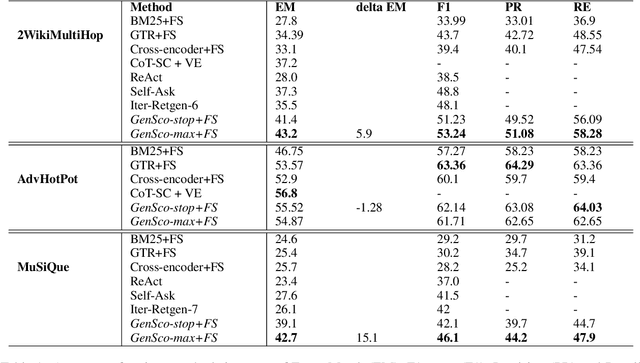
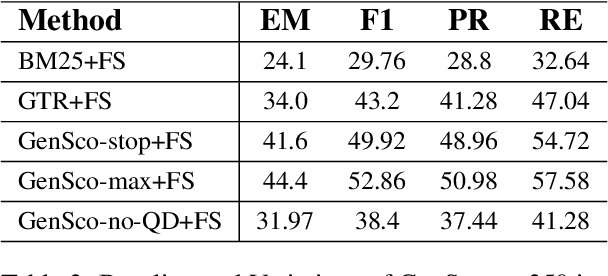
Retrieval augmented generation (RAG) with large language models (LLMs) for Question Answering (QA) entails furnishing relevant context within the prompt to facilitate the LLM in answer generation. During the generation, inaccuracies or hallucinations frequently occur due to two primary factors: inadequate or distracting context in the prompts, and the inability of LLMs to effectively reason through the facts. In this paper, we investigate whether providing aligned context via a carefully selected passage sequence leads to better answer generation by the LLM for multi-hop QA. We introduce, "GenSco", a novel approach of selecting passages based on the predicted decomposition of the multi-hop questions}. The framework consists of two distinct LLMs: (i) Generator LLM, which is used for question decomposition and final answer generation; (ii) an auxiliary open-sourced LLM, used as the scorer, to semantically guide the Generator for passage selection. The generator is invoked only once for the answer generation, resulting in a cost-effective and efficient approach. We evaluate on three broadly established multi-hop question answering datasets: 2WikiMultiHop, Adversarial HotPotQA and MuSiQue and achieve an absolute gain of $15.1$ and $5.9$ points in Exact Match score with respect to the best performing baselines over MuSiQue and 2WikiMultiHop respectively.
SafaRi:Adaptive Sequence Transformer for Weakly Supervised Referring Expression Segmentation
Jul 02, 2024
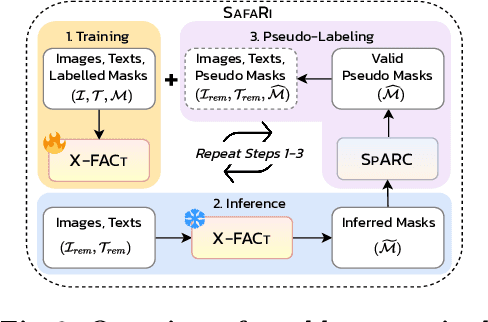
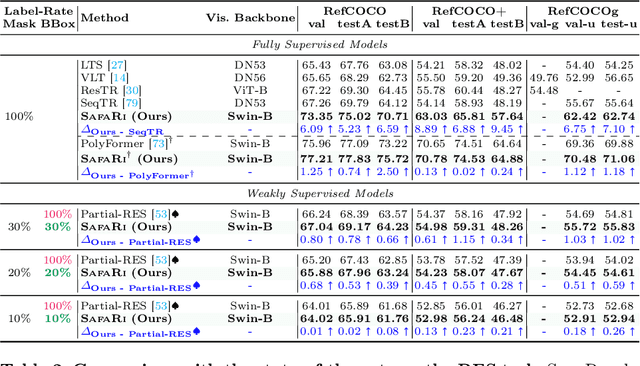
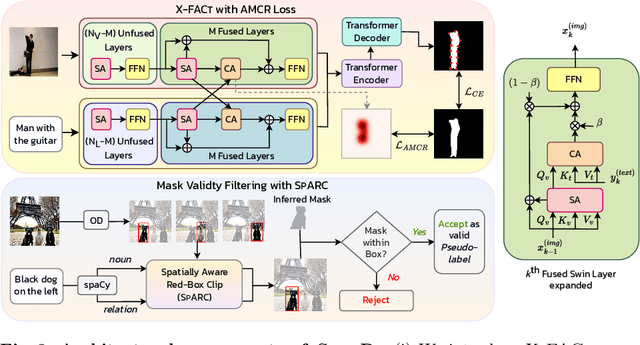
Referring Expression Segmentation (RES) aims to provide a segmentation mask of the target object in an image referred to by the text (i.e., referring expression). Existing methods require large-scale mask annotations. Moreover, such approaches do not generalize well to unseen/zero-shot scenarios. To address the aforementioned issues, we propose a weakly-supervised bootstrapping architecture for RES with several new algorithmic innovations. To the best of our knowledge, ours is the first approach that considers only a fraction of both mask and box annotations (shown in Figure 1 and Table 1) for training. To enable principled training of models in such low-annotation settings, improve image-text region-level alignment, and further enhance spatial localization of the target object in the image, we propose Cross-modal Fusion with Attention Consistency module. For automatic pseudo-labeling of unlabeled samples, we introduce a novel Mask Validity Filtering routine based on a spatially aware zero-shot proposal scoring approach. Extensive experiments show that with just 30% annotations, our model SafaRi achieves 59.31 and 48.26 mIoUs as compared to 58.93 and 48.19 mIoUs obtained by the fully-supervised SOTA method SeqTR respectively on RefCOCO+@testA and RefCOCO+testB datasets. SafaRi also outperforms SeqTR by 11.7% (on RefCOCO+testA) and 19.6% (on RefCOCO+testB) in a fully-supervised setting and demonstrates strong generalization capabilities in unseen/zero-shot tasks.
Post-Hoc Answer Attribution for Grounded and Trustworthy Long Document Comprehension: Task, Insights, and Challenges
Jun 11, 2024Attributing answer text to its source document for information-seeking questions is crucial for building trustworthy, reliable, and accountable systems. We formulate a new task of post-hoc answer attribution for long document comprehension (LDC). Owing to the lack of long-form abstractive and information-seeking LDC datasets, we refactor existing datasets to assess the strengths and weaknesses of existing retrieval-based and proposed answer decomposition and textual entailment-based optimal selection attribution systems for this task. We throw light on the limitations of existing datasets and the need for datasets to assess the actual performance of systems on this task.