 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfogen: Generating Complex Statistical Infographics from Documents
Jul 26, 2025Statistical infographics are powerful tools that simplify complex data into visually engaging and easy-to-understand formats. Despite advancements in AI, particularly with LLMs, existing efforts have been limited to generating simple charts, with no prior work addressing the creation of complex infographics from text-heavy documents that demand a deep understanding of the content. We address this gap by introducing the task of generating statistical infographics composed of multiple sub-charts (e.g., line, bar, pie) that are contextually accurate, insightful, and visually aligned. To achieve this, we define infographic metadata that includes its title and textual insights, along with sub-chart-specific details such as their corresponding data and alignment. We also present Infodat, the first benchmark dataset for text-to-infographic metadata generation, where each sample links a document to its metadata. We propose Infogen, a two-stage framework where fine-tuned LLMs first generate metadata, which is then converted into infographic code. Extensive evaluations on Infodat demonstrate that Infogen achieves state-of-the-art performance, outperforming both closed and open-source LLMs in text-to-statistical infographic generation.
Enhancing Post-Hoc Attributions in Long Document Comprehension via Coarse Grained Answer Decomposition
Sep 25, 2024
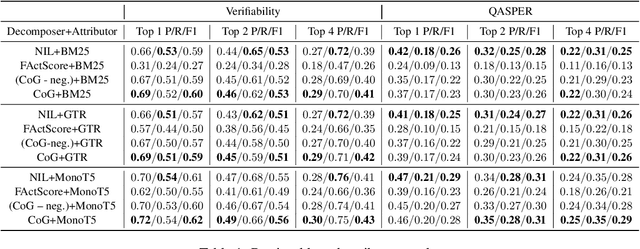
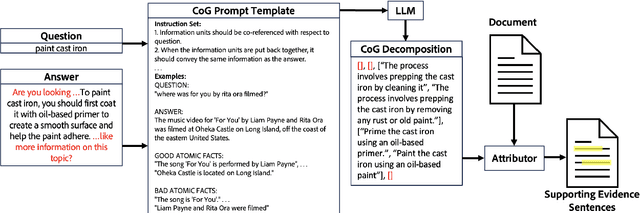
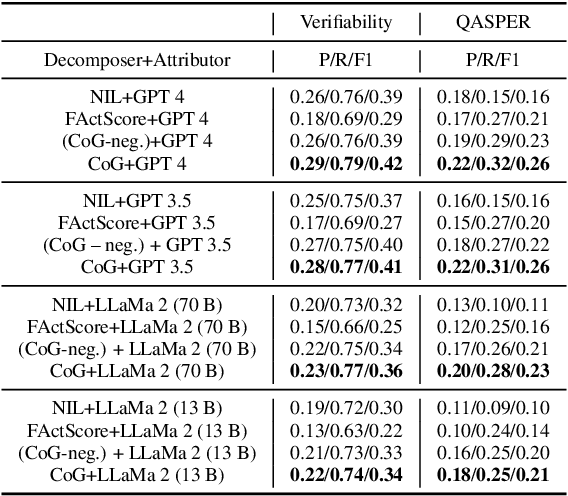
Accurately attributing answer text to its source document is crucial for developing a reliable question-answering system. However, attribution for long documents remains largely unexplored. Post-hoc attribution systems are designed to map answer text back to the source document, yet the granularity of this mapping has not been addressed. Furthermore, a critical question arises: What precisely should be attributed, with an emphasis on identifying the information units within an answer that necessitate grounding? In this paper, we propose and investigate a novel approach to the factual decomposition of generated answers for attribution, employing template-based in-context learning. To accomplish this, we utilize the question and integrate negative sampling during few-shot in-context learning for decomposition. This approach enhances the semantic understanding of both abstractive and extractive answers. We examine the impact of answer decomposition by providing a thorough examination of various attribution approaches, ranging from retrieval-based techniques to LLM-based attributors.
Unraveling the Truth: Do LLMs really Understand Charts? A Deep Dive into Consistency and Robustness
Jul 15, 2024



Chart question answering (CQA) is a crucial area of Visual Language Understanding. However, the robustness and consistency of current Visual Language Models (VLMs) in this field remain under-explored. This paper evaluates state-of-the-art VLMs on comprehensive datasets, developed specifically for this study, encompassing diverse question categories and chart formats. We investigate two key aspects: 1) the models' ability to handle varying levels of chart and question complexity, and 2) their robustness across different visual representations of the same underlying data. Our analysis reveals significant performance variations based on question and chart types, highlighting both strengths and weaknesses of current models. Additionally, we identify areas for improvement and propose future research directions to build more robust and reliable CQA systems. This study sheds light on the limitations of current models and paves the way for future advancements in the field.
Is this a bad table? A Closer Look at the Evaluation of Table Generation from Text
Jun 21, 2024



Understanding whether a generated table is of good quality is important to be able to use it in creating or editing documents using automatic methods. In this work, we underline that existing measures for table quality evaluation fail to capture the overall semantics of the tables, and sometimes unfairly penalize good tables and reward bad ones. We propose TabEval, a novel table evaluation strategy that captures table semantics by first breaking down a table into a list of natural language atomic statements and then compares them with ground truth statements using entailment-based measures. To validate our approach, we curate a dataset comprising of text descriptions for 1,250 diverse Wikipedia tables, covering a range of topics and structures, in contrast to the limited scope of existing datasets. We compare TabEval with existing metrics using unsupervised and supervised text-to-table generation methods, demonstrating its stronger correlation with human judgments of table quality across four datasets.
RE$^2$: Region-Aware Relation Extraction from Visually Rich Documents
May 24, 2023Current research in form understanding predominantly relies on large pre-trained language models, necessitating extensive data for pre-training. However, the importance of layout structure (i.e., the spatial relationship between the entity blocks in the visually rich document) to relation extraction has been overlooked. In this paper, we propose REgion-Aware Relation Extraction (RE$^2$) that leverages region-level spatial structure among the entity blocks to improve their relation prediction. We design an edge-aware graph attention network to learn the interaction between entities while considering their spatial relationship defined by their region-level representations. We also introduce a constraint objective to regularize the model towards consistency with the inherent constraints of the relation extraction task. Extensive experiments across various datasets, languages and domains demonstrate the superiority of our proposed approach.