 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSMMIC: Comment-Sensitive Multimodal Multilingual Indian Corpus for Summarization and Headline Generation
Jun 18, 2025Despite progress in comment-aware multimodal and multilingual summarization for English and Chinese, research in Indian languages remains limited. This study addresses this gap by introducing COSMMIC, a pioneering comment-sensitive multimodal, multilingual dataset featuring nine major Indian languages. COSMMIC comprises 4,959 article-image pairs and 24,484 reader comments, with ground-truth summaries available in all included languages. Our approach enhances summaries by integrating reader insights and feedback. We explore summarization and headline generation across four configurations: (1) using article text alone, (2) incorporating user comments, (3) utilizing images, and (4) combining text, comments, and images. To assess the dataset's effectiveness, we employ state-of-the-art language models such as LLama3 and GPT-4. We conduct a comprehensive study to evaluate different component combinations, including identifying supportive comments, filtering out noise using a dedicated comment classifier using IndicBERT, and extracting valuable insights from images with a multilingual CLIP-based classifier. This helps determine the most effective configurations for natural language generation (NLG) tasks. Unlike many existing datasets that are either text-only or lack user comments in multimodal settings, COSMMIC uniquely integrates text, images, and user feedback. This holistic approach bridges gaps in Indian language resources, advancing NLP research and fostering inclusivity.
SANSKRITI: A Comprehensive Benchmark for Evaluating Language Models' Knowledge of Indian Culture
Jun 18, 2025

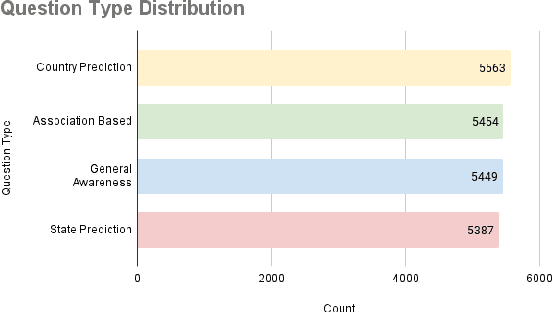
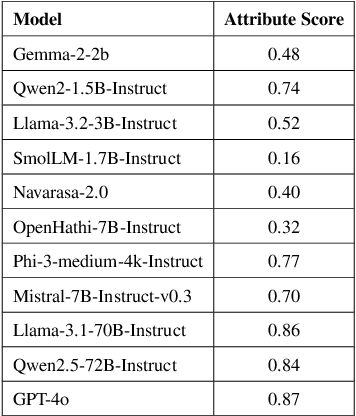
Language Models (LMs) are indispensable tools shaping modern workflows, but their global effectiveness depends on understanding local socio-cultural contexts. To address this, we introduce SANSKRITI, a benchmark designed to evaluate language models' comprehension of India's rich cultural diversity. Comprising 21,853 meticulously curated question-answer pairs spanning 28 states and 8 union territories, SANSKRITI is the largest dataset for testing Indian cultural knowledge. It covers sixteen key attributes of Indian culture: rituals and ceremonies, history, tourism, cuisine, dance and music, costume, language, art, festivals, religion, medicine, transport, sports, nightlife, and personalities, providing a comprehensive representation of India's cultural tapestry. We evaluate SANSKRITI on leading Large Language Models (LLMs), Indic Language Models (ILMs), and Small Language Models (SLMs), revealing significant disparities in their ability to handle culturally nuanced queries, with many models struggling in region-specific contexts. By offering an extensive, culturally rich, and diverse dataset, SANSKRITI sets a new standard for assessing and improving the cultural understanding of LMs.
Poetry in Pixels: Prompt Tuning for Poem Image Generation via Diffusion Models
Jan 10, 2025



The task of text-to-image generation has encountered significant challenges when applied to literary works, especially poetry. Poems are a distinct form of literature, with meanings that frequently transcend beyond the literal words. To address this shortcoming, we propose a PoemToPixel framework designed to generate images that visually represent the inherent meanings of poems. Our approach incorporates the concept of prompt tuning in our image generation framework to ensure that the resulting images closely align with the poetic content. In addition, we propose the PoeKey algorithm, which extracts three key elements in the form of emotions, visual elements, and themes from poems to form instructions which are subsequently provided to a diffusion model for generating corresponding images. Furthermore, to expand the diversity of the poetry dataset across different genres and ages, we introduce MiniPo, a novel multimodal dataset comprising 1001 children's poems and images. Leveraging this dataset alongside PoemSum, we conducted both quantitative and qualitative evaluations of image generation using our PoemToPixel framework. This paper demonstrates the effectiveness of our approach and offers a fresh perspective on generating images from literary sources.
Large Scale Multi-Lingual Multi-Modal Summarization Dataset
Feb 13, 2023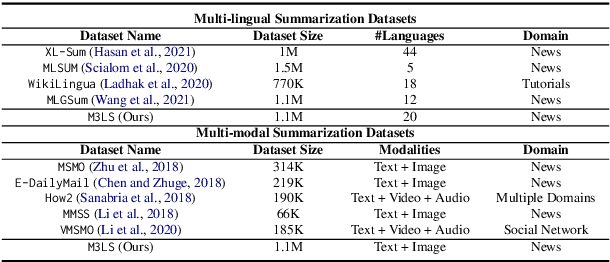

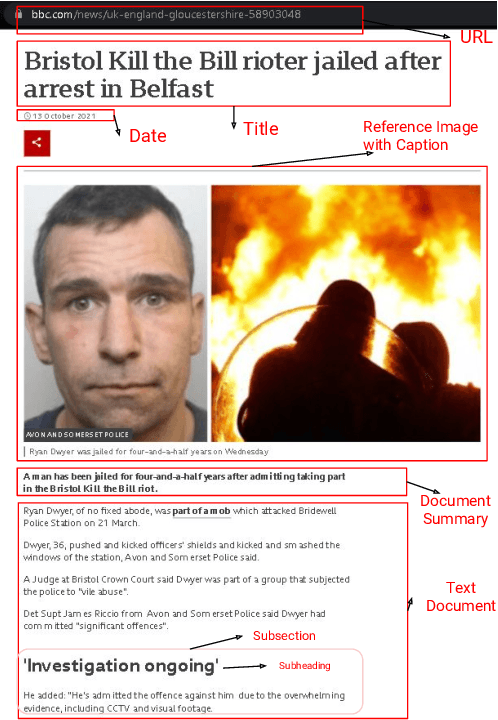
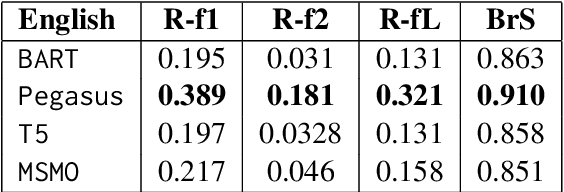
Significant developments in techniques such as encoder-decoder models have enabled us to represent information comprising multiple modalities. This information can further enhance many downstream tasks in the field of information retrieval and natural language processing; however, improvements in multi-modal techniques and their performance evaluation require large-scale multi-modal data which offers sufficient diversity. Multi-lingual modeling for a variety of tasks like multi-modal summarization, text generation, and translation leverages information derived from high-quality multi-lingual annotated data. In this work, we present the current largest multi-lingual multi-modal summarization dataset (M3LS), and it consists of over a million instances of document-image pairs along with a professionally annotated multi-modal summary for each pair. It is derived from news articles published by British Broadcasting Corporation(BBC) over a decade and spans 20 languages, targeting diversity across five language roots, it is also the largest summarization dataset for 13 languages and consists of cross-lingual summarization data for 2 languages. We formally define the multi-lingual multi-modal summarization task utilizing our dataset and report baseline scores from various state-of-the-art summarization techniques in a multi-lingual setting. We also compare it with many similar datasets to analyze the uniqueness and difficulty of M3LS.