 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Long Context Performance in LLMs Through Inner Loop Query Mechanism
Oct 11, 2024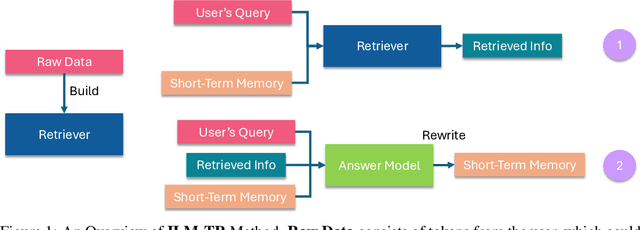
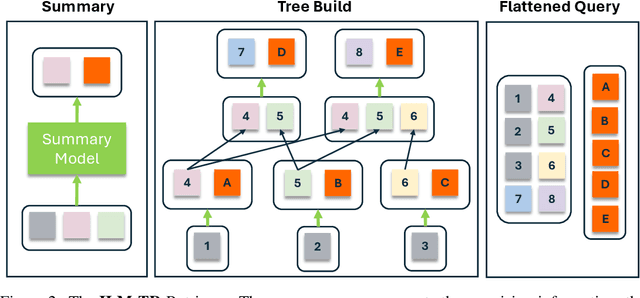
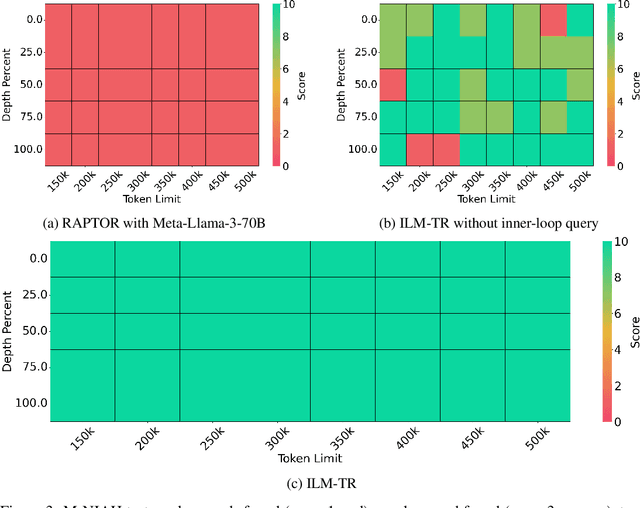
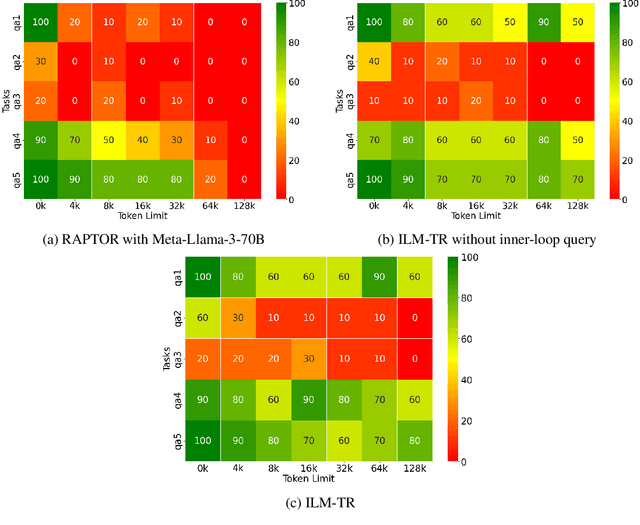
Transformers have a quadratic scaling of computational complexity with input size, which limits the input context window size of large language models (LLMs) in both training and inference. Meanwhile, retrieval-augmented generation (RAG) besed models can better handle longer contexts by using a retrieval system to filter out unnecessary information. However, most RAG methods only perform retrieval based on the initial query, which may not work well with complex questions that require deeper reasoning. We introduce a novel approach, Inner Loop Memory Augmented Tree Retrieval (ILM-TR), involving inner-loop queries, based not only on the query question itself but also on intermediate findings. At inference time, our model retrieves information from the RAG system, integrating data from lengthy documents at various levels of abstraction. Based on the information retrieved, the LLM generates texts stored in an area named Short-Term Memory (STM) which is then used to formulate the next query. This retrieval process is repeated until the text in STM converged. Our experiments demonstrate that retrieval with STM offers improvements over traditional retrieval-augmented LLMs, particularly in long context tests such as Multi-Needle In A Haystack (M-NIAH) and BABILong.