 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecipe2Vec: Multi-modal Recipe Representation Learning with Graph Neural Networks
Paper and Code
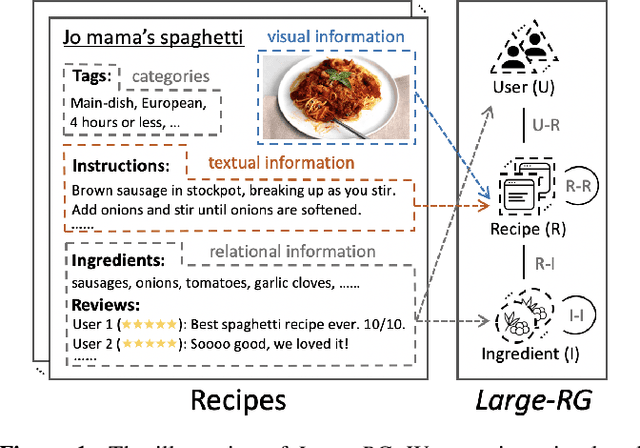
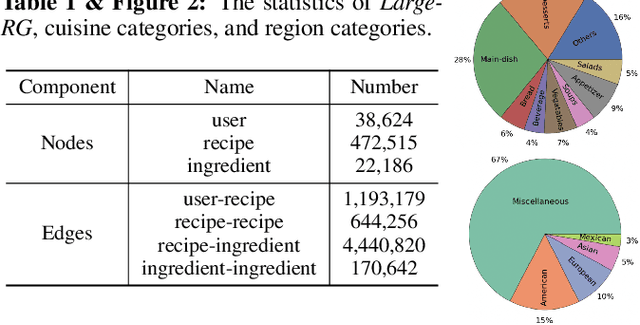
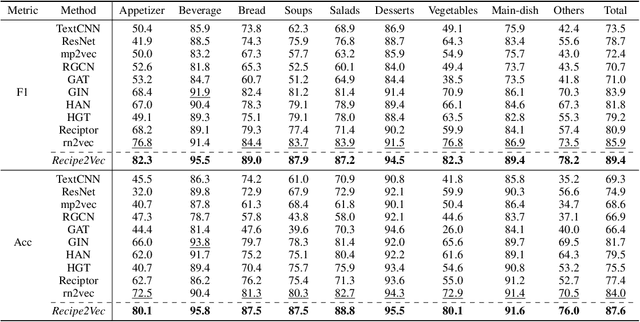
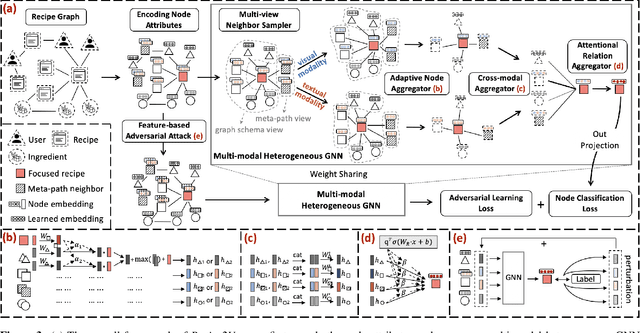
Learning effective recipe representations is essential in food studies. Unlike what has been developed for image-based recipe retrieval or learning structural text embeddings, the combined effect of multi-modal information (i.e., recipe images, text, and relation data) receives less attention. In this paper, we formalize the problem of multi-modal recipe representation learning to integrate the visual, textual, and relational information into recipe embeddings. In particular, we first present Large-RG, a new recipe graph data with over half a million nodes, making it the largest recipe graph to date. We then propose Recipe2Vec, a novel graph neural network based recipe embedding model to capture multi-modal information. Additionally, we introduce an adversarial attack strategy to ensure stable learning and improve performance. Finally, we design a joint objective function of node classification and adversarial learning to optimize the model. Extensive experiments demonstrate that Recipe2Vec outperforms state-of-the-art baselines on two classic food study tasks, i.e., cuisine category classification and region prediction. Dataset and codes are available at https://github.com/meettyj/Recipe2Vec.