 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier AI Regulation: Managing Emerging Risks to Public Safety
Jul 11, 2023Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
Why and How Governments Should Monitor AI Development
Aug 31, 2021In this paper we outline a proposal for improving the governance of artificial intelligence (AI) by investing in government capacity to systematically measure and monitor the capabilities and impacts of AI systems. If adopted, this would give governments greater information about the AI ecosystem, equipping them to more effectively direct AI development and deployment in the most societally and economically beneficial directions. It would also create infrastructure that could rapidly identify potential threats or harms that could occur as a consequence of changes in the AI ecosystem, such as the emergence of strategically transformative capabilities, or the deployment of harmful systems. We begin by outlining the problem which motivates this proposal: in brief, traditional governance approaches struggle to keep pace with the speed of progress in AI. We then present our proposal for addressing this problem: governments must invest in measurement and monitoring infrastructure. We discuss this proposal in detail, outlining what specific things governments could focus on measuring and monitoring, and the kinds of benefits this would generate for policymaking. Finally, we outline some potential pilot projects and some considerations for implementing this in practice.
Beyond Near- and Long-Term: Towards a Clearer Account of Research Priorities in AI Ethics and Society
Jan 21, 2020

One way of carving up the broad "AI ethics and society" research space that has emerged in recent years is to distinguish between "near-term" and "long-term" research. While such ways of breaking down the research space can be useful, we put forward several concerns about the near/long-term distinction gaining too much prominence in how research questions and priorities are framed. We highlight some ambiguities and inconsistencies in how the distinction is used, and argue that while there are differing priorities within this broad research community, these differences are not well-captured by the near/long-term distinction. We unpack the near/long-term distinction into four different dimensions, and propose some ways that researchers can communicate more clearly about their work and priorities using these dimensions. We suggest that moving towards a more nuanced conversation about research priorities can help establish new opportunities for collaboration, aid the development of more consistent and coherent research agendas, and enable identification of previously neglected research areas.
Defining and Unpacking Transformative AI
Nov 27, 2019

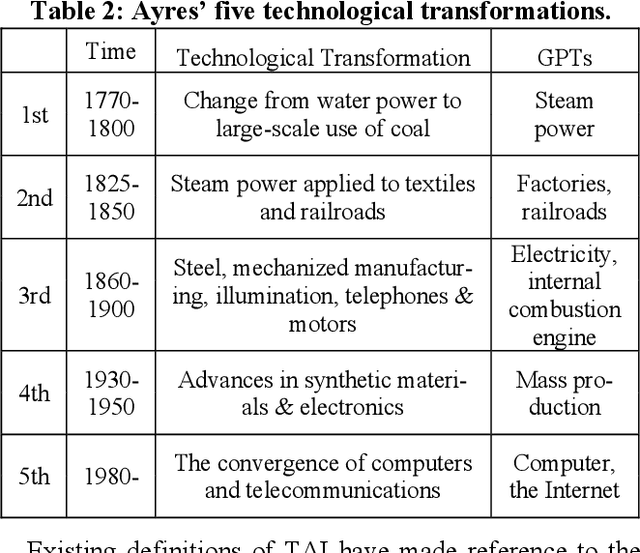
Recently the concept of transformative AI (TAI) has begun to receive attention in the AI policy space. TAI is often framed as an alternative formulation to notions of strong AI (e.g. artificial general intelligence or superintelligence) and reflects increasing consensus that advanced AI which does not fit these definitions may nonetheless have extreme and long-lasting impacts on society. However, the term TAI is poorly defined and often used ambiguously. Some use the notion of TAI to describe levels of societal transformation associated with previous 'general purpose technologies' (GPTs) such as electricity or the internal combustion engine. Others use the term to refer to more drastic levels of transformation comparable to the agricultural or industrial revolutions. The notion has also been used much more loosely, with some implying that current AI systems are already having a transformative impact on society. This paper unpacks and analyses the notion of TAI, proposing a distinction between TAI and radically transformative AI (RTAI), roughly corresponding to societal change on the level of the agricultural or industrial revolutions. We describe some relevant dimensions associated with each and discuss what kinds of advances in capabilities they might require. We further consider the relationship between TAI and RTAI and whether we should necessarily expect a period of TAI to precede the emergence of RTAI. This analysis is important as it can help guide discussions among AI policy researchers about how to allocate resources towards mitigating the most extreme impacts of AI and it can bring attention to negative TAI scenarios that are currently neglected.
The tension between openness and prudence in AI research
Oct 02, 2019This paper explores the tension between openness and prudence in AI research, evident in two core principles of the Montr\'eal Declaration for Responsible AI. While the AI community has strong norms around open sharing of research, concerns about the potential harms arising from misuse of research are growing, prompting some to consider whether the field of AI needs to reconsider publication norms. We discuss how different beliefs and values can lead to differing perspectives on how the AI community should manage this tension, and explore implications for what responsible publication norms in AI research might look like in practice.
Reducing malicious use of synthetic media research: Considerations and potential release practices for machine learning
Jul 29, 2019The aim of this paper is to facilitate nuanced discussion around research norms and practices to mitigate the harmful impacts of advances in machine learning (ML). We focus particularly on the use of ML to create "synthetic media" (e.g. to generate or manipulate audio, video, images, and text), and the question of what publication and release processes around such research might look like, though many of the considerations discussed will apply to ML research more broadly. We are not arguing for any specific approach on when or how research should be distributed, but instead try to lay out some useful tools, analogies, and options for thinking about these issues. We begin with some background on the idea that ML research might be misused in harmful ways, and why advances in synthetic media, in particular, are raising concerns. We then outline in more detail some of the different paths to harm from ML research, before reviewing research risk mitigation strategies in other fields and identifying components that seem most worth emulating in the ML and synthetic media research communities. Next, we outline some important dimensions of disagreement on these issues which risk polarizing conversations. Finally, we conclude with recommendations, suggesting that the machine learning community might benefit from: working with subject matter experts to increase understanding of the risk landscape and possible mitigation strategies; building a community and norms around understanding the impacts of ML research, e.g. through regular workshops at major conferences; and establishing institutions and systems to support release practices that would otherwise be onerous and error-prone.