 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating Privacy Risks Stemming from Language Models: A Survey
Sep 27, 2023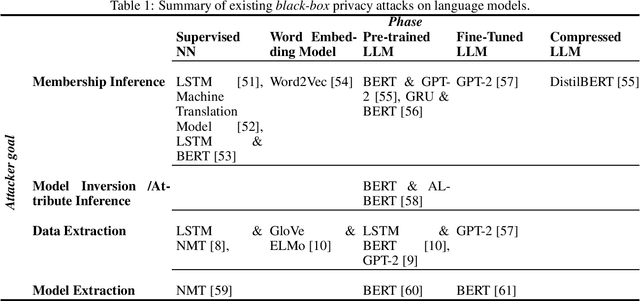
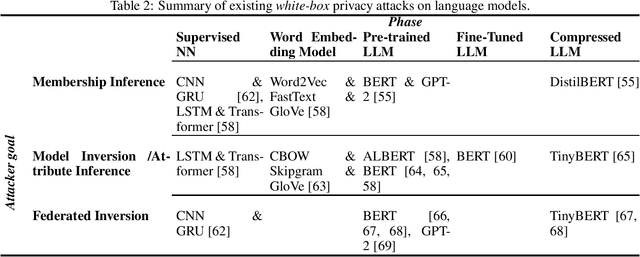
Rapid advancements in language models (LMs) have led to their adoption across many sectors. Alongside the potential benefits, such models present a range of risks, including around privacy. In particular, as LMs have grown in size, the potential to memorise aspects of their training data has increased, resulting in the risk of leaking private information. As LMs become increasingly widespread, it is vital that we understand such privacy risks and how they might be mitigated. To help researchers and policymakers understand the state of knowledge around privacy attacks and mitigations, including where more work is needed, we present the first technical survey on LM privacy. We (i) identify a taxonomy of salient dimensions where attacks differ on LMs, (ii) survey existing attacks and use our taxonomy of dimensions to highlight key trends, (iii) discuss existing mitigation strategies, highlighting their strengths and limitations, identifying key gaps and demonstrating open problems and areas for concern.
Why Fair Labels Can Yield Unfair Predictions: Graphical Conditions for Introduced Unfairness
Feb 23, 2022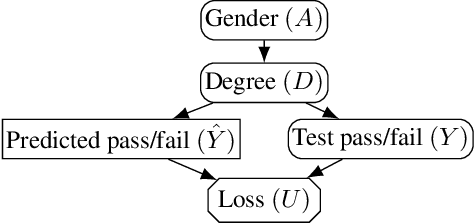
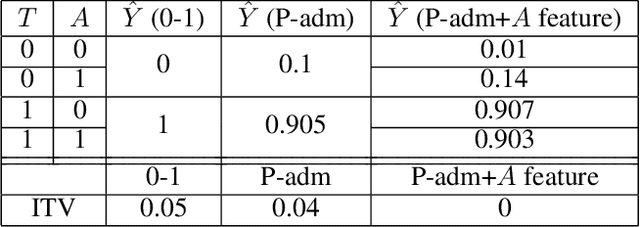
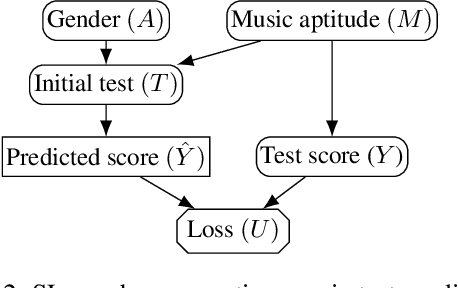
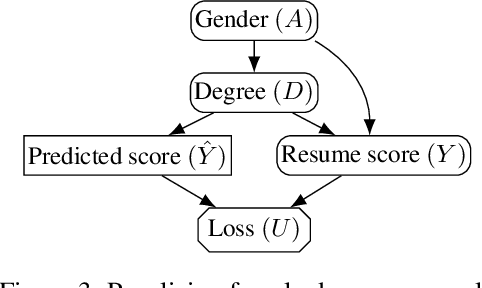
In addition to reproducing discriminatory relationships in the training data, machine learning systems can also introduce or amplify discriminatory effects. We refer to this as introduced unfairness, and investigate the conditions under which it may arise. To this end, we propose introduced total variation as a measure of introduced unfairness, and establish graphical conditions under which it may be incentivised to occur. These criteria imply that adding the sensitive attribute as a feature removes the incentive for introduced variation under well-behaved loss functions. Additionally, taking a causal perspective, introduced path-specific effects shed light on the issue of when specific paths should be considered fair.
AI Ethics Statements -- Analysis and lessons learnt from NeurIPS Broader Impact Statements
Nov 02, 2021
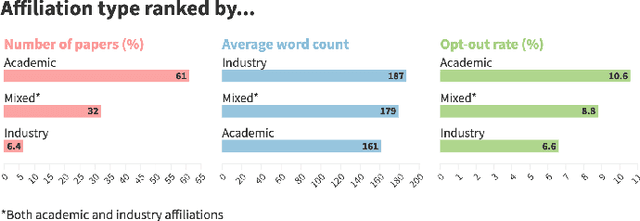
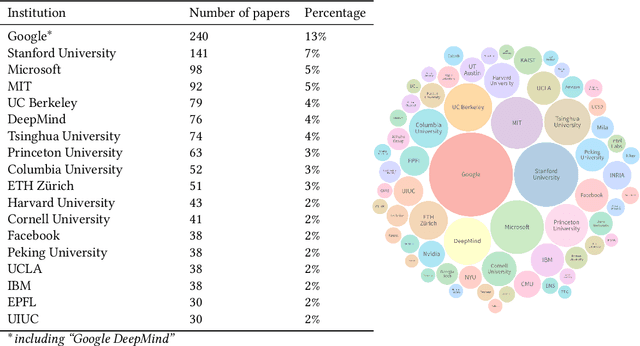
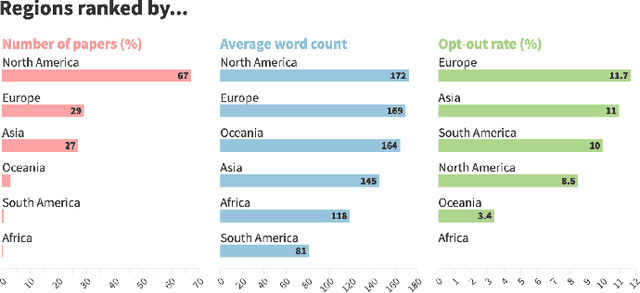
Ethics statements have been proposed as a mechanism to increase transparency and promote reflection on the societal impacts of published research. In 2020, the machine learning (ML) conference NeurIPS broke new ground by requiring that all papers include a broader impact statement. This requirement was removed in 2021, in favour of a checklist approach. The 2020 statements therefore provide a unique opportunity to learn from the broader impact experiment: to investigate the benefits and challenges of this and similar governance mechanisms, as well as providing an insight into how ML researchers think about the societal impacts of their own work. Such learning is needed as NeurIPS and other venues continue to question and adapt their policies. To enable this, we have created a dataset containing the impact statements from all NeurIPS 2020 papers, along with additional information such as affiliation type, location and subject area, and a simple visualisation tool for exploration. We also provide an initial quantitative analysis of the dataset, covering representation, engagement, common themes, and willingness to discuss potential harms alongside benefits. We investigate how these vary by geography, affiliation type and subject area. Drawing on these findings, we discuss the potential benefits and negative outcomes of ethics statement requirements, and their possible causes and associated challenges. These lead us to several lessons to be learnt from the 2020 requirement: (i) the importance of creating the right incentives, (ii) the need for clear expectations and guidance, and (iii) the importance of transparency and constructive deliberation. We encourage other researchers to use our dataset to provide additional analysis, to further our understanding of how researchers responded to this requirement, and to investigate the benefits and challenges of this and related mechanisms.
RAFT: A Real-World Few-Shot Text Classification Benchmark
Sep 28, 2021
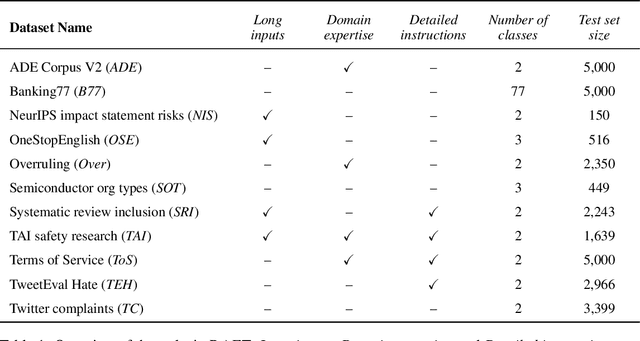
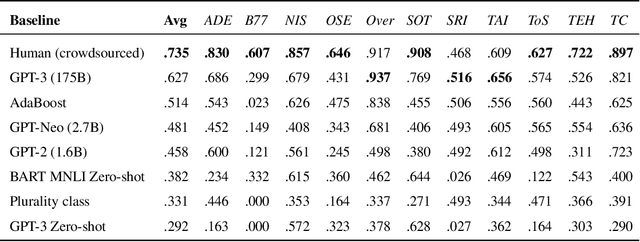

Large pre-trained language models have shown promise for few-shot learning, completing text-based tasks given only a few task-specific examples. Will models soon solve classification tasks that have so far been reserved for human research assistants? Existing benchmarks are not designed to measure progress in applied settings, and so don't directly answer this question. The RAFT benchmark (Real-world Annotated Few-shot Tasks) focuses on naturally occurring tasks and uses an evaluation setup that mirrors deployment. Baseline evaluations on RAFT reveal areas current techniques struggle with: reasoning over long texts and tasks with many classes. Human baselines show that some classification tasks are difficult for non-expert humans, reflecting that real-world value sometimes depends on domain expertise. Yet even non-expert human baseline F1 scores exceed GPT-3 by an average of 0.11. The RAFT datasets and leaderboard will track which model improvements translate into real-world benefits at https://raft.elicit.org .
Institutionalising Ethics in AI through Broader Impact Requirements
May 30, 2021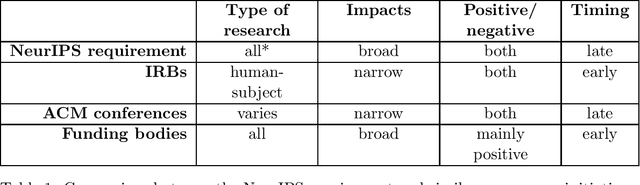
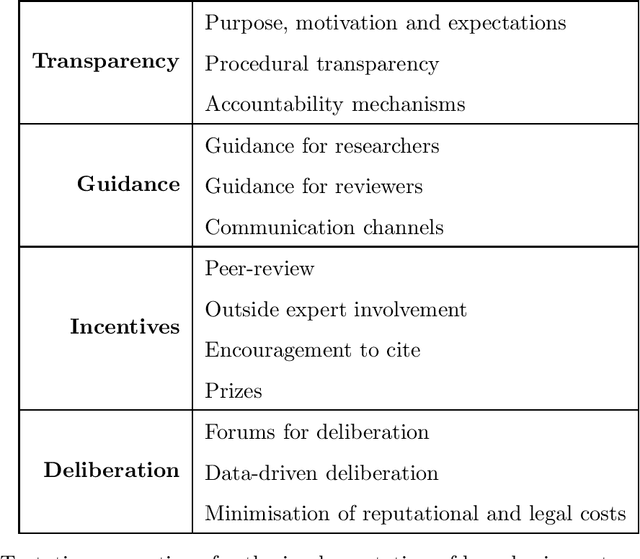
Turning principles into practice is one of the most pressing challenges of artificial intelligence (AI) governance. In this article, we reflect on a novel governance initiative by one of the world's largest AI conferences. In 2020, the Conference on Neural Information Processing Systems (NeurIPS) introduced a requirement for submitting authors to include a statement on the broader societal impacts of their research. Drawing insights from similar governance initiatives, including institutional review boards (IRBs) and impact requirements for funding applications, we investigate the risks, challenges and potential benefits of such an initiative. Among the challenges, we list a lack of recognised best practice and procedural transparency, researcher opportunity costs, institutional and social pressures, cognitive biases, and the inherently difficult nature of the task. The potential benefits, on the other hand, include improved anticipation and identification of impacts, better communication with policy and governance experts, and a general strengthening of the norms around responsible research. To maximise the chance of success, we recommend measures to increase transparency, improve guidance, create incentives to engage earnestly with the process, and facilitate public deliberation on the requirement's merits and future. Perhaps the most important contribution from this analysis are the insights we can gain regarding effective community-based governance and the role and responsibility of the AI research community more broadly.