 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI Optimisation (AAIO): what it is, how it works, why it matters, and how to deal with it
Apr 16, 2025
The emergence of Agentic Artificial Intelligence (AAI) systems capable of independently initiating digital interactions necessitates a new optimisation paradigm designed explicitly for seamless agent-platform interactions. This article introduces Agentic AI Optimisation (AAIO) as an essential methodology for ensuring effective integration between websites and agentic AI systems. Like how Search Engine Optimisation (SEO) has shaped digital content discoverability, AAIO can define interactions between autonomous AI agents and online platforms. By examining the mutual interdependency between website optimisation and agentic AI success, the article highlights the virtuous cycle that AAIO can create. It further explores the governance, ethical, legal, and social implications (GELSI) of AAIO, emphasising the necessity of proactive regulatory frameworks to mitigate potential negative impacts. The article concludes by affirming AAIO's essential role as part of a fundamental digital infrastructure in the era of autonomous digital agents, advocating for equitable and inclusive access to its benefits.
AI Ethics Statements -- Analysis and lessons learnt from NeurIPS Broader Impact Statements
Nov 02, 2021
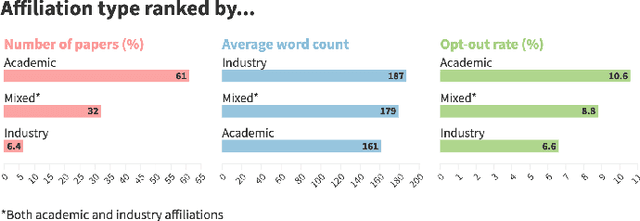
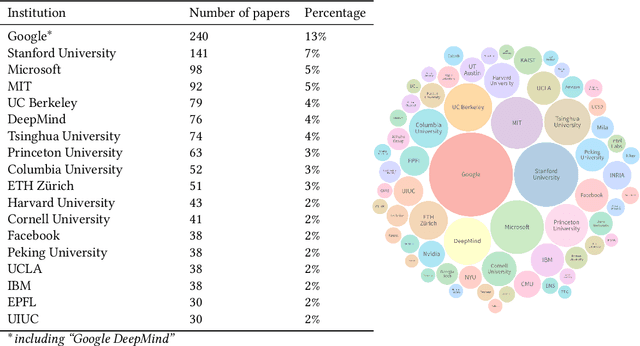
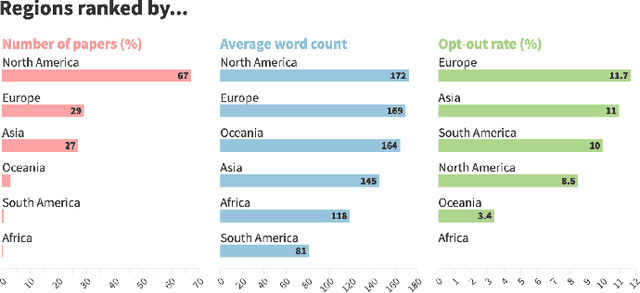
Ethics statements have been proposed as a mechanism to increase transparency and promote reflection on the societal impacts of published research. In 2020, the machine learning (ML) conference NeurIPS broke new ground by requiring that all papers include a broader impact statement. This requirement was removed in 2021, in favour of a checklist approach. The 2020 statements therefore provide a unique opportunity to learn from the broader impact experiment: to investigate the benefits and challenges of this and similar governance mechanisms, as well as providing an insight into how ML researchers think about the societal impacts of their own work. Such learning is needed as NeurIPS and other venues continue to question and adapt their policies. To enable this, we have created a dataset containing the impact statements from all NeurIPS 2020 papers, along with additional information such as affiliation type, location and subject area, and a simple visualisation tool for exploration. We also provide an initial quantitative analysis of the dataset, covering representation, engagement, common themes, and willingness to discuss potential harms alongside benefits. We investigate how these vary by geography, affiliation type and subject area. Drawing on these findings, we discuss the potential benefits and negative outcomes of ethics statement requirements, and their possible causes and associated challenges. These lead us to several lessons to be learnt from the 2020 requirement: (i) the importance of creating the right incentives, (ii) the need for clear expectations and guidance, and (iii) the importance of transparency and constructive deliberation. We encourage other researchers to use our dataset to provide additional analysis, to further our understanding of how researchers responded to this requirement, and to investigate the benefits and challenges of this and related mechanisms.
RAFT: A Real-World Few-Shot Text Classification Benchmark
Sep 28, 2021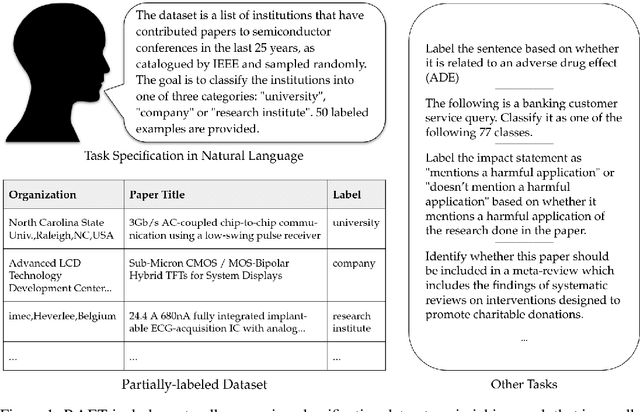
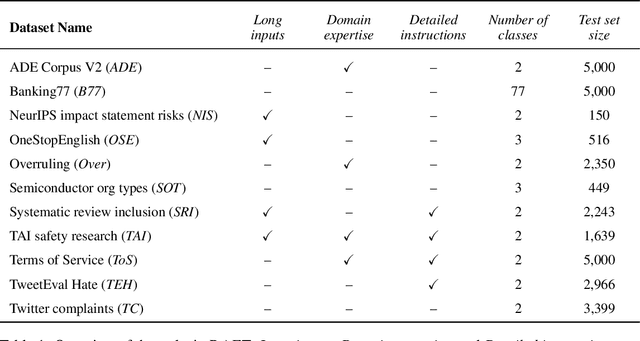
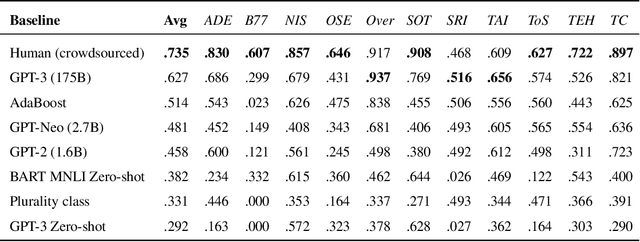

Large pre-trained language models have shown promise for few-shot learning, completing text-based tasks given only a few task-specific examples. Will models soon solve classification tasks that have so far been reserved for human research assistants? Existing benchmarks are not designed to measure progress in applied settings, and so don't directly answer this question. The RAFT benchmark (Real-world Annotated Few-shot Tasks) focuses on naturally occurring tasks and uses an evaluation setup that mirrors deployment. Baseline evaluations on RAFT reveal areas current techniques struggle with: reasoning over long texts and tasks with many classes. Human baselines show that some classification tasks are difficult for non-expert humans, reflecting that real-world value sometimes depends on domain expertise. Yet even non-expert human baseline F1 scores exceed GPT-3 by an average of 0.11. The RAFT datasets and leaderboard will track which model improvements translate into real-world benefits at https://raft.elicit.org .