 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating Privacy Risks Stemming from Language Models: A Survey
Paper and Code
Sep 27, 2023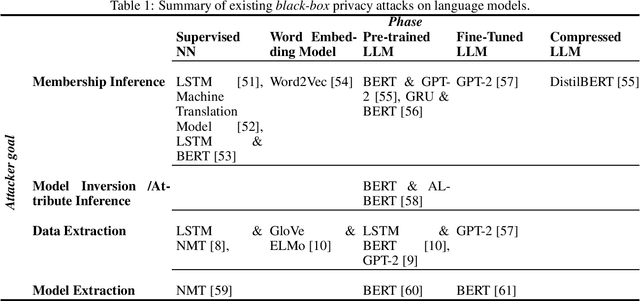
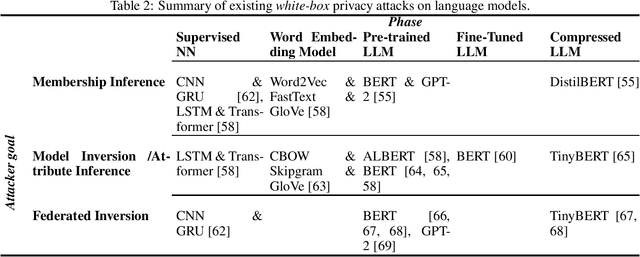
Rapid advancements in language models (LMs) have led to their adoption across many sectors. Alongside the potential benefits, such models present a range of risks, including around privacy. In particular, as LMs have grown in size, the potential to memorise aspects of their training data has increased, resulting in the risk of leaking private information. As LMs become increasingly widespread, it is vital that we understand such privacy risks and how they might be mitigated. To help researchers and policymakers understand the state of knowledge around privacy attacks and mitigations, including where more work is needed, we present the first technical survey on LM privacy. We (i) identify a taxonomy of salient dimensions where attacks differ on LMs, (ii) survey existing attacks and use our taxonomy of dimensions to highlight key trends, (iii) discuss existing mitigation strategies, highlighting their strengths and limitations, identifying key gaps and demonstrating open problems and areas for concern.