 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID-GAN: Conditional Generative Models to Locate Unfairness
Jul 28, 2023Most group fairness notions detect unethical biases by computing statistical parity metrics on a model's output. However, this approach suffers from several shortcomings, such as philosophical disagreement, mutual incompatibility, and lack of interpretability. These shortcomings have spurred the research on complementary bias detection methods that offer additional transparency into the sources of discrimination and are agnostic towards an a priori decision on the definition of fairness and choice of protected features. A recent proposal in this direction is LUCID (Locating Unfairness through Canonical Inverse Design), where canonical sets are generated by performing gradient descent on the input space, revealing a model's desired input given a preferred output. This information about the model's mechanisms, i.e., which feature values are essential to obtain specific outputs, allows exposing potential unethical biases in its internal logic. Here, we present LUCID-GAN, which generates canonical inputs via a conditional generative model instead of gradient-based inverse design. LUCID-GAN has several benefits, including that it applies to non-differentiable models, ensures that canonical sets consist of realistic inputs, and allows to assess proxy and intersectional discrimination. We empirically evaluate LUCID-GAN on the UCI Adult and COMPAS data sets and show that it allows for detecting unethical biases in black-box models without requiring access to the training data.
LUCID: Exposing Algorithmic Bias through Inverse Design
Aug 26, 2022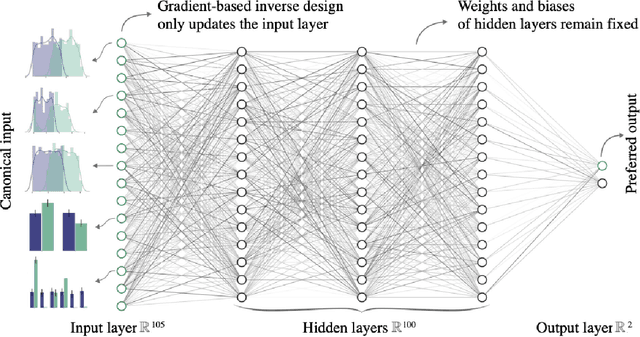
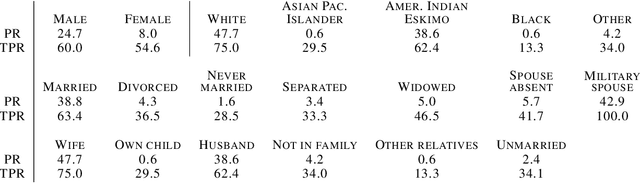
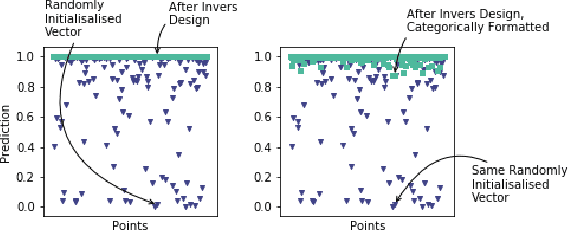

AI systems can create, propagate, support, and automate bias in decision-making processes. To mitigate biased decisions, we both need to understand the origin of the bias and define what it means for an algorithm to make fair decisions. Most group fairness notions assess a model's equality of outcome by computing statistical metrics on the outputs. We argue that these output metrics encounter intrinsic obstacles and present a complementary approach that aligns with the increasing focus on equality of treatment. By Locating Unfairness through Canonical Inverse Design (LUCID), we generate a canonical set that shows the desired inputs for a model given a preferred output. The canonical set reveals the model's internal logic and exposes potential unethical biases by repeatedly interrogating the decision-making process. We evaluate LUCID on the UCI Adult and COMPAS data sets and find that some biases detected by a canonical set differ from those of output metrics. The results show that by shifting the focus towards equality of treatment and looking into the algorithm's internal workings, the canonical sets are a valuable addition to the toolbox of algorithmic fairness evaluation.