 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUplift modeling with continuous treatments: A predict-then-optimize approach
Dec 12, 2024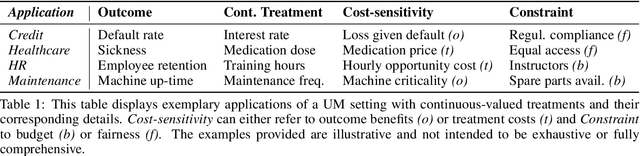

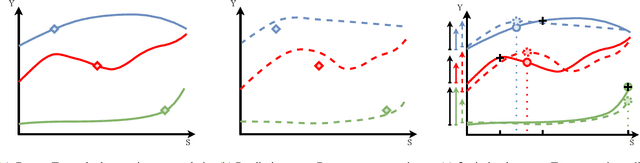
The goal of uplift modeling is to recommend actions that optimize specific outcomes by determining which entities should receive treatment. One common approach involves two steps: first, an inference step that estimates conditional average treatment effects (CATEs), and second, an optimization step that ranks entities based on their CATE values and assigns treatment to the top k within a given budget. While uplift modeling typically focuses on binary treatments, many real-world applications are characterized by continuous-valued treatments, i.e., a treatment dose. This paper presents a predict-then-optimize framework to allow for continuous treatments in uplift modeling. First, in the inference step, conditional average dose responses (CADRs) are estimated from data using causal machine learning techniques. Second, in the optimization step, we frame the assignment task of continuous treatments as a dose-allocation problem and solve it using integer linear programming (ILP). This approach allows decision-makers to efficiently and effectively allocate treatment doses while balancing resource availability, with the possibility of adding extra constraints like fairness considerations or adapting the objective function to take into account instance-dependent costs and benefits to maximize utility. The experiments compare several CADR estimators and illustrate the trade-offs between policy value and fairness, as well as the impact of an adapted objective function. This showcases the framework's advantages and flexibility across diverse applications in healthcare, lending, and human resource management. All code is available on github.com/SimonDeVos/UMCT.
Sources of Gain: Decomposing Performance in Conditional Average Dose Response Estimation
Jun 12, 2024



Estimating conditional average dose responses (CADR) is an important but challenging problem. Estimators must correctly model the potentially complex relationships between covariates, interventions, doses, and outcomes. In recent years, the machine learning community has shown great interest in developing tailored CADR estimators that target specific challenges. Their performance is typically evaluated against other methods on (semi-) synthetic benchmark datasets. Our paper analyses this practice and shows that using popular benchmark datasets without further analysis is insufficient to judge model performance. Established benchmarks entail multiple challenges, whose impacts must be disentangled. Therefore, we propose a novel decomposition scheme that allows the evaluation of the impact of five distinct components contributing to CADR estimator performance. We apply this scheme to eight popular CADR estimators on four widely-used benchmark datasets, running nearly 1,500 individual experiments. Our results reveal that most established benchmarks are challenging for reasons different from their creators' claims. Notably, confounding, the key challenge tackled by most estimators, is not an issue in any of the considered datasets. We discuss the major implications of our findings and present directions for future research.
Learning continuous-valued treatment effects through representation balancing
Sep 07, 2023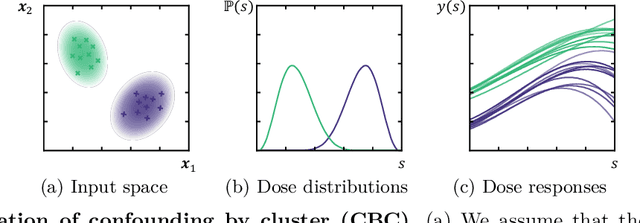
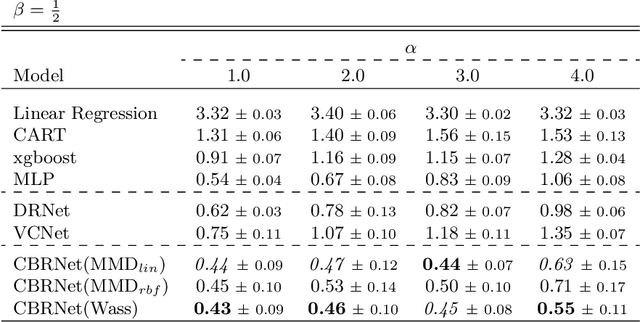
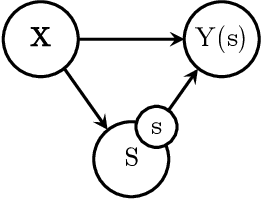
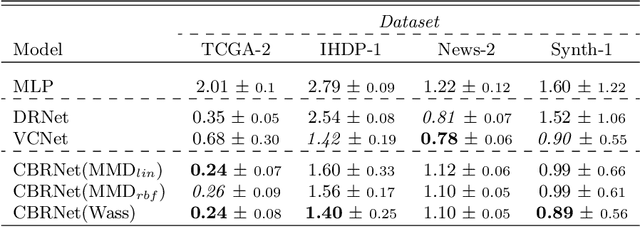
Estimating the effects of treatments with an associated dose on an instance's outcome, the "dose response", is relevant in a variety of domains, from healthcare to business, economics, and beyond. Such effects, also known as continuous-valued treatment effects, are typically estimated from observational data, which may be subject to dose selection bias. This means that the allocation of doses depends on pre-treatment covariates. Previous studies have shown that conventional machine learning approaches fail to learn accurate individual estimates of dose responses under the presence of dose selection bias. In this work, we propose CBRNet, a causal machine learning approach to estimate an individual dose response from observational data. CBRNet adopts the Neyman-Rubin potential outcome framework and extends the concept of balanced representation learning for overcoming selection bias to continuous-valued treatments. Our work is the first to apply representation balancing in a continuous-valued treatment setting. We evaluate our method on a newly proposed benchmark. Our experiments demonstrate CBRNet's ability to accurately learn treatment effects under selection bias and competitive performance with respect to other state-of-the-art methods.
A Causal Perspective on Loan Pricing: Investigating the Impacts of Selection Bias on Identifying Bid-Response Functions
Sep 07, 2023In lending, where prices are specific to both customers and products, having a well-functioning personalized pricing policy in place is essential to effective business making. Typically, such a policy must be derived from observational data, which introduces several challenges. While the problem of ``endogeneity'' is prominently studied in the established pricing literature, the problem of selection bias (or, more precisely, bid selection bias) is not. We take a step towards understanding the effects of selection bias by posing pricing as a problem of causal inference. Specifically, we consider the reaction of a customer to price a treatment effect. In our experiments, we simulate varying levels of selection bias on a semi-synthetic dataset on mortgage loan applications in Belgium. We investigate the potential of parametric and nonparametric methods for the identification of individual bid-response functions. Our results illustrate how conventional methods such as logistic regression and neural networks suffer adversely from selection bias. In contrast, we implement state-of-the-art methods from causal machine learning and show their capability to overcome selection bias in pricing data.
Fraud Analytics: A Decade of Research -- Organizing Challenges and Solutions in the Field
Dec 07, 2022



The literature on fraud analytics and fraud detection has seen a substantial increase in output in the past decade. This has led to a wide range of research topics and overall little organization of the many aspects of fraud analytical research. The focus of academics ranges from identifying fraudulent credit card payments to spotting illegitimate insurance claims. In addition, there is a wide range of methods and research objectives. This paper aims to provide an overview of fraud analytics in research and aims to more narrowly organize the discipline and its many subfields. We analyze a sample of almost 300 records on fraud analytics published between 2011 and 2020. In a systematic way, we identify the most prominent domains of application, challenges faced, performance metrics, and methods used. In addition, we build a framework for fraud analytical methods and propose a keywording strategy for future research. One of the key challenges in fraud analytics is access to public datasets. To further aid the community, we provide eight requirements for suitable data sets in research motivated by our research. We structure our sample of the literature in an online database. The database is available online for fellow researchers to investigate and potentially build upon.
Predicting Day-Ahead Stock Returns using Search Engine Query Volumes: An Application of Gradient Boosted Decision Trees to the S&P 100
Jun 01, 2022
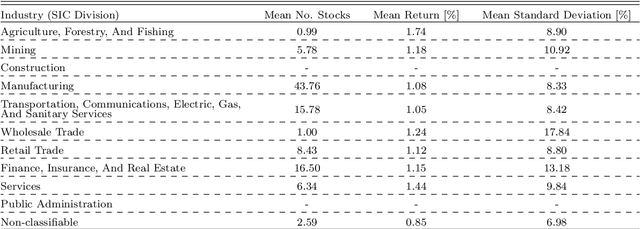


The internet has changed the way we live, work and take decisions. As it is the major modern resource for research, detailed data on internet usage exhibits vast amounts of behavioral information. This paper aims to answer the question whether this information can be facilitated to predict future returns of stocks on financial capital markets. In an empirical analysis it implements gradient boosted decision trees to learn relationships between abnormal returns of stocks within the S&P 100 index and lagged predictors derived from historical financial data, as well as search term query volumes on the internet search engine Google. Models predict the occurrence of day-ahead stock returns in excess of the index median. On a time frame from 2005 to 2017, all disparate datasets exhibit valuable information. Evaluated models have average areas under the receiver operating characteristic between 54.2% and 56.7%, clearly indicating a classification better than random guessing. Implementing a simple statistical arbitrage strategy, models are used to create daily trading portfolios of ten stocks and result in annual performances of more than 57% before transaction costs. With ensembles of different data sets topping up the performance ranking, the results further question the weak form and semi-strong form efficiency of modern financial capital markets. Even though transaction costs are not included, the approach adds to the existing literature. It gives guidance on how to use and transform data on internet usage behavior for financial and economic modeling and forecasting.