 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Day-Ahead Stock Returns using Search Engine Query Volumes: An Application of Gradient Boosted Decision Trees to the S&P 100
Paper and Code
Jun 01, 2022
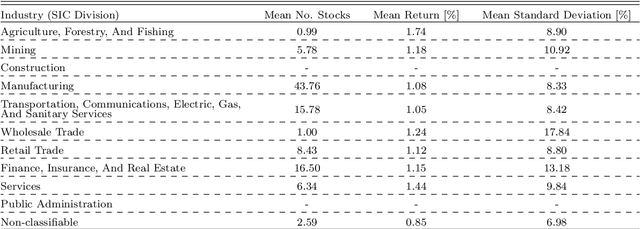


The internet has changed the way we live, work and take decisions. As it is the major modern resource for research, detailed data on internet usage exhibits vast amounts of behavioral information. This paper aims to answer the question whether this information can be facilitated to predict future returns of stocks on financial capital markets. In an empirical analysis it implements gradient boosted decision trees to learn relationships between abnormal returns of stocks within the S&P 100 index and lagged predictors derived from historical financial data, as well as search term query volumes on the internet search engine Google. Models predict the occurrence of day-ahead stock returns in excess of the index median. On a time frame from 2005 to 2017, all disparate datasets exhibit valuable information. Evaluated models have average areas under the receiver operating characteristic between 54.2% and 56.7%, clearly indicating a classification better than random guessing. Implementing a simple statistical arbitrage strategy, models are used to create daily trading portfolios of ten stocks and result in annual performances of more than 57% before transaction costs. With ensembles of different data sets topping up the performance ranking, the results further question the weak form and semi-strong form efficiency of modern financial capital markets. Even though transaction costs are not included, the approach adds to the existing literature. It gives guidance on how to use and transform data on internet usage behavior for financial and economic modeling and forecasting.