 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutotune: fast, accurate, and automatic tuning parameter selection for Lasso
Dec 15, 2025Least absolute shrinkage and selection operator (Lasso), a popular method for high-dimensional regression, is now used widely for estimating high-dimensional time series models such as the vector autoregression (VAR). Selecting its tuning parameter efficiently and accurately remains a challenge, despite the abundance of available methods for doing so. We propose $\mathsf{autotune}$, a strategy for Lasso to automatically tune itself by optimizing a penalized Gaussian log-likelihood alternately over regression coefficients and noise standard deviation. Using extensive simulation experiments on regression and VAR models, we show that $\mathsf{autotune}$ is faster, and provides better generalization and model selection than established alternatives in low signal-to-noise regimes. In the process, $\mathsf{autotune}$ provides a new estimator of noise standard deviation that can be used for high-dimensional inference, and a new visual diagnostic procedure for checking the sparsity assumption on regression coefficients. Finally, we demonstrate the utility of $\mathsf{autotune}$ on a real-world financial data set. An R package based on C++ is also made publicly available on Github.
Robust Matrix Completion for Discrete Rating-Scale Data
Dec 30, 2024Matrix completion has gained considerable interest in recent years. The goal of matrix completion is to predict the unknown entries of a partially observed matrix using its known entries. Although common applications feature discrete rating-scale data, such as user-product rating matrices in recommender systems or surveys in the social and behavioral sciences, methods for matrix completion are almost always designed for and studied in the context of continuous data. Furthermore, only a small subset of the literature considers matrix completion in the presence of corrupted observations despite their common occurrence in practice. Examples include attacks on recommender systems (i.e., malicious users deliberately manipulating ratings to influence the recommender system to their advantage), or careless respondents in surveys (i.e., respondents providing answers irrespective of what the survey asks of them due to a lack of attention). We introduce a matrix completion algorithm that is tailored towards the discrete nature of rating-scale data and robust to the presence of corrupted observations. In addition, we investigate the performance of the proposed method and its competitors with discrete rating-scale (rather than continuous) data as well as under various missing data mechanisms and types of corrupted observations.
Sparse outlier-robust PCA for multi-source data
Jul 23, 2024Sparse and outlier-robust Principal Component Analysis (PCA) has been a very active field of research recently. Yet, most existing methods apply PCA to a single dataset whereas multi-source data-i.e. multiple related datasets requiring joint analysis-arise across many scientific areas. We introduce a novel PCA methodology that simultaneously (i) selects important features, (ii) allows for the detection of global sparse patterns across multiple data sources as well as local source-specific patterns, and (iii) is resistant to outliers. To this end, we develop a regularization problem with a penalty that accommodates global-local structured sparsity patterns, and where the ssMRCD estimator is used as plug-in to permit joint outlier-robust analysis across multiple data sources. We provide an efficient implementation of our proposal via the Alternating Direction Method of Multiplier and illustrate its practical advantages in simulation and in applications.
Cross-Temporal Forecast Reconciliation at Digital Platforms with Machine Learning
Feb 14, 2024



Platform businesses operate on a digital core and their decision making requires high-dimensional accurate forecast streams at different levels of cross-sectional (e.g., geographical regions) and temporal aggregation (e.g., minutes to days). It also necessitates coherent forecasts across all levels of the hierarchy to ensure aligned decision making across different planning units such as pricing, product, controlling and strategy. Given that platform data streams feature complex characteristics and interdependencies, we introduce a non-linear hierarchical forecast reconciliation method that produces cross-temporal reconciled forecasts in a direct and automated way through the use of popular machine learning methods. The method is sufficiently fast to allow forecast-based high-frequency decision making that platforms require. We empirically test our framework on a unique, large-scale streaming dataset from a leading on-demand delivery platform in Europe.
Monitoring Machine Learning Forecasts for Platform Data Streams
Jan 17, 2024Data stream forecasts are essential inputs for decision making at digital platforms. Machine learning algorithms are appealing candidates to produce such forecasts. Yet, digital platforms require a large-scale forecast framework that can flexibly respond to sudden performance drops. Re-training ML algorithms at the same speed as new data batches enter is usually computationally too costly. On the other hand, infrequent re-training requires specifying the re-training frequency and typically comes with a severe cost of forecast deterioration. To ensure accurate and stable forecasts, we propose a simple data-driven monitoring procedure to answer the question when the ML algorithm should be re-trained. Instead of investigating instability of the data streams, we test if the incoming streaming forecast loss batch differs from a well-defined reference batch. Using a novel dataset constituting 15-min frequency data streams from an on-demand logistics platform operating in London, we apply the monitoring procedure to popular ML algorithms including random forest, XGBoost and lasso. We show that monitor-based re-training produces accurate forecasts compared to viable benchmarks while preserving computational feasibility. Moreover, the choice of monitoring procedure is more important than the choice of ML algorithm, thereby permitting practitioners to combine the proposed monitoring procedure with one's favorite forecasting algorithm.
Tree-based Forecasting of Day-ahead Solar Power Generation from Granular Meteorological Features
Nov 30, 2023
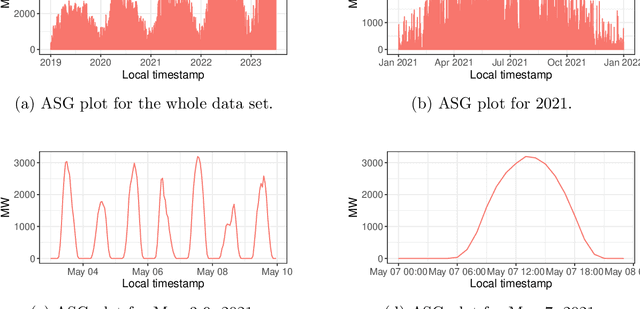
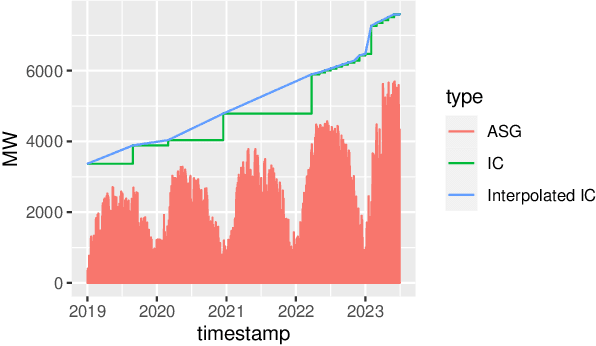

Accurate forecasts for day-ahead photovoltaic (PV) power generation are crucial to support a high PV penetration rate in the local electricity grid and to assure stability in the grid. We use state-of-the-art tree-based machine learning methods to produce such forecasts and, unlike previous studies, we hereby account for (i) the effects various meteorological as well as astronomical features have on PV power production, and this (ii) at coarse as well as granular spatial locations. To this end, we use data from Belgium and forecast day-ahead PV power production at an hourly resolution. The insights from our study can assist utilities, decision-makers, and other stakeholders in optimizing grid operations, economic dispatch, and in facilitating the integration of distributed PV power into the electricity grid.
Tree-based Node Aggregation in Sparse Graphical Models
Jan 29, 2021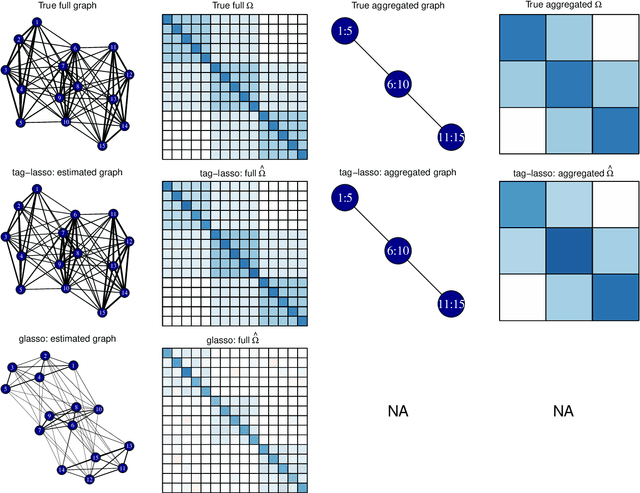

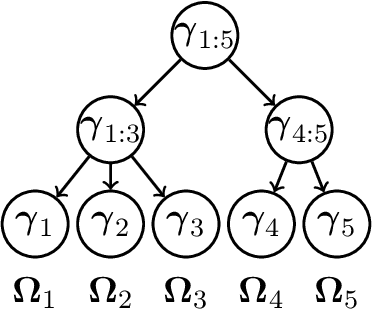

High-dimensional graphical models are often estimated using regularization that is aimed at reducing the number of edges in a network. In this work, we show how even simpler networks can be produced by aggregating the nodes of the graphical model. We develop a new convex regularized method, called the tree-aggregated graphical lasso or tag-lasso, that estimates graphical models that are both edge-sparse and node-aggregated. The aggregation is performed in a data-driven fashion by leveraging side information in the form of a tree that encodes node similarity and facilitates the interpretation of the resulting aggregated nodes. We provide an efficient implementation of the tag-lasso by using the locally adaptive alternating direction method of multipliers and illustrate our proposal's practical advantages in simulation and in applications in finance and biology.
High Dimensional Forecasting via Interpretable Vector Autoregression
Sep 08, 2018
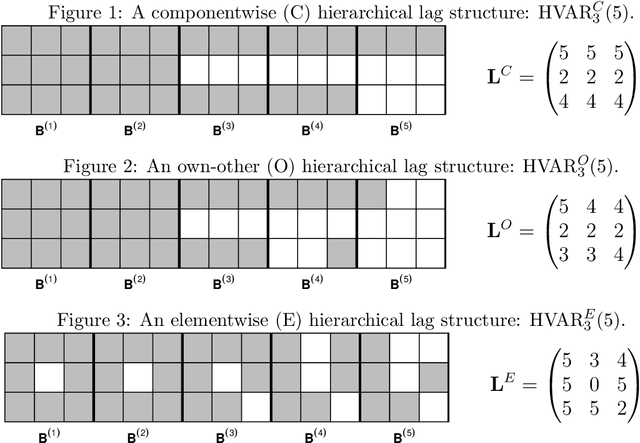
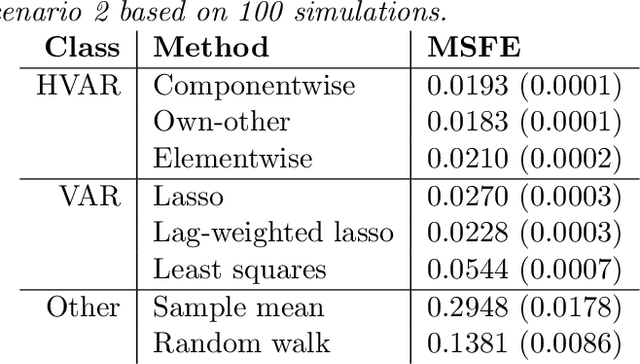
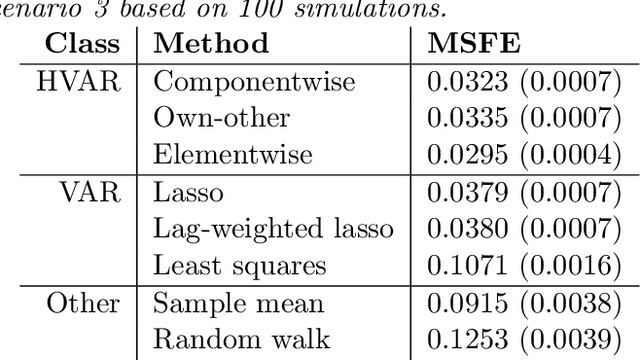
Vector autoregression (VAR) is a fundamental tool for modeling multivariate time series. However, as the number of component series is increased, the VAR model becomes overparameterized. Several authors have addressed this issue by incorporating regularized approaches, such as the lasso in VAR estimation. Traditional approaches address overparameterization by selecting a low lag order, based on the assumption of short range dependence, assuming that a universal lag order applies to all components. Such an approach constrains the relationship between the components and impedes forecast performance. The lasso-based approaches work much better in high-dimensional situations but do not incorporate the notion of lag order selection. We propose a new class of hierarchical lag structures (HLag) that embed the notion of lag selection into a convex regularizer. The key modeling tool is a group lasso with nested groups which guarantees that the sparsity pattern of lag coefficients honors the VAR's ordered structure. The HLag framework offers three structures, which allow for varying levels of flexibility. A simulation study demonstrates improved performance in forecasting and lag order selection over previous approaches, and a macroeconomic application further highlights forecasting improvements as well as HLag's convenient, interpretable output.
Interpretable Vector AutoRegressions with Exogenous Time Series
Nov 09, 2017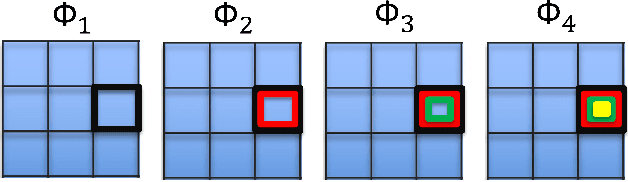
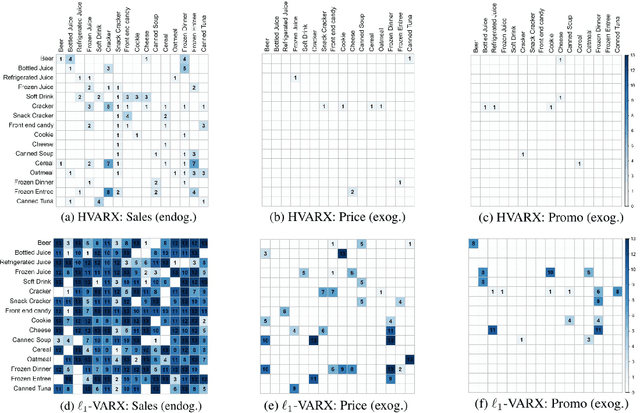
The Vector AutoRegressive (VAR) model is fundamental to the study of multivariate time series. Although VAR models are intensively investigated by many researchers, practitioners often show more interest in analyzing VARX models that incorporate the impact of unmodeled exogenous variables (X) into the VAR. However, since the parameter space grows quadratically with the number of time series, estimation quickly becomes challenging. While several proposals have been made to sparsely estimate large VAR models, the estimation of large VARX models is under-explored. Moreover, typically these sparse proposals involve a lasso-type penalty and do not incorporate lag selection into the estimation procedure. As a consequence, the resulting models may be difficult to interpret. In this paper, we propose a lag-based hierarchically sparse estimator, called "HVARX", for large VARX models. We illustrate the usefulness of HVARX on a cross-category management marketing application. Our results show how it provides a highly interpretable model, and improves out-of-sample forecast accuracy compared to a lasso-type approach.