 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARGE: A Locally Adaptive Regularization Approach for Estimating Gaussian Graphical Models
Jan 14, 2026The graphical Lasso (GLASSO) is a widely used algorithm for learning high-dimensional undirected Gaussian graphical models (GGM). Given i.i.d. observations from a multivariate normal distribution, GLASSO estimates the precision matrix by maximizing the log-likelihood with an \ell_1-penalty on the off-diagonal entries. However, selecting an optimal regularization parameter λin this unsupervised setting remains a significant challenge. A well-known issue is that existing methods, such as out-of-sample likelihood maximization, select a single global λand do not account for heterogeneity in variable scaling or partial variances. Standardizing the data to unit variances, although a common workaround, has been shown to negatively affect graph recovery. Addressing the problem of nodewise adaptive tuning in graph estimation is crucial for applications like computational neuroscience, where brain networks are constructed from highly heterogeneous, region-specific fMRI data. In this work, we develop Locally Adaptive Regularization for Graph Estimation (LARGE), an approach to adaptively learn nodewise tuning parameters to improve graph estimation and selection. In each block coordinate descent step of GLASSO, we augment the nodewise Lasso regression to jointly estimate the regression coefficients and error variance, which in turn guides the adaptive learning of nodewise penalties. In simulations, LARGE consistently outperforms benchmark methods in graph recovery, demonstrates greater stability across replications, and achieves the best estimation accuracy in the most difficult simulation settings. We demonstrate the practical utility of our method by estimating brain functional connectivity from a real fMRI data set.
Autotune: fast, accurate, and automatic tuning parameter selection for Lasso
Dec 15, 2025Least absolute shrinkage and selection operator (Lasso), a popular method for high-dimensional regression, is now used widely for estimating high-dimensional time series models such as the vector autoregression (VAR). Selecting its tuning parameter efficiently and accurately remains a challenge, despite the abundance of available methods for doing so. We propose $\mathsf{autotune}$, a strategy for Lasso to automatically tune itself by optimizing a penalized Gaussian log-likelihood alternately over regression coefficients and noise standard deviation. Using extensive simulation experiments on regression and VAR models, we show that $\mathsf{autotune}$ is faster, and provides better generalization and model selection than established alternatives in low signal-to-noise regimes. In the process, $\mathsf{autotune}$ provides a new estimator of noise standard deviation that can be used for high-dimensional inference, and a new visual diagnostic procedure for checking the sparsity assumption on regression coefficients. Finally, we demonstrate the utility of $\mathsf{autotune}$ on a real-world financial data set. An R package based on C++ is also made publicly available on Github.
Counterfactual Forecasting For Panel Data
Nov 09, 2025We address the challenge of forecasting counterfactual outcomes in a panel data with missing entries and temporally dependent latent factors -- a common scenario in causal inference, where estimating unobserved potential outcomes ahead of time is essential. We propose Forecasting Counterfactuals under Stochastic Dynamics (FOCUS), a method that extends traditional matrix completion methods by leveraging time series dynamics of the factors, thereby enhancing the prediction accuracy of future counterfactuals. Building upon a PCA estimator, our method accommodates both stochastic and deterministic components within the factors, and provides a flexible framework for various applications. In case of stationary autoregressive factors and under standard conditions, we derive error bounds and establish asymptotic normality of our estimator. Empirical evaluations demonstrate that our method outperforms existing benchmarks when the latent factors have an autoregressive component. We illustrate FOCUS results on HeartSteps, a mobile health study, illustrating its effectiveness in forecasting step counts for users receiving activity prompts, thereby leveraging temporal patterns in user behavior.
A Pathwise Coordinate Descent Algorithm for LASSO Penalized Quantile Regression
Feb 17, 2025$\ell_1$ penalized quantile regression is used in many fields as an alternative to penalized least squares regressions for high-dimensional data analysis. Existing algorithms for penalized quantile regression either use linear programming, which does not scale well in high dimension, or an approximate coordinate descent (CD) which does not solve for exact coordinatewise minimum of the nonsmooth loss function. Further, neither approaches build fast, pathwise algorithms commonly used in high-dimensional statistics to leverage sparsity structure of the problem in large-scale data sets. To avoid the computational challenges associated with the nonsmooth quantile loss, some recent works have even advocated using smooth approximations to the exact problem. In this work, we develop a fast, pathwise coordinate descent algorithm to compute exact $\ell_1$ penalized quantile regression estimates for high-dimensional data. We derive an easy-to-compute exact solution for the coordinatewise nonsmooth loss minimization, which, to the best of our knowledge, has not been reported in the literature. We also employ a random perturbation strategy to help the algorithm avoid getting stuck along the regularization path. In simulated data sets, we show that our algorithm runs substantially faster than existing alternatives based on approximate CD and linear program, while retaining the same level of estimation accuracy.
Random Forests for dependent data
Jul 30, 2020
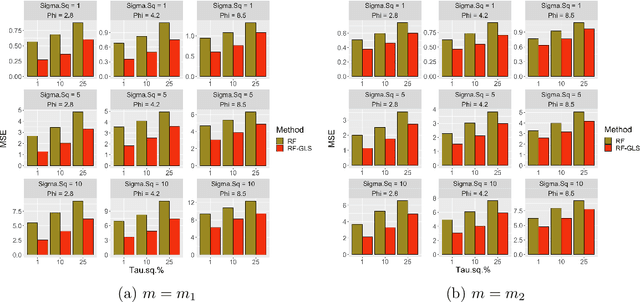
Random forest (RF) is one of the most popular methods for estimating regression functions. The local nature of the RF algorithm, based on intra-node means and variances, is ideal when errors are i.i.d. For dependent error processes like time series and spatial settings where data in all the nodes will be correlated, operating locally ignores this dependence. Also, RF will involve resampling of correlated data, violating the principles of bootstrap. Theoretically, consistency of RF has been established for i.i.d. errors, but little is known about the case of dependent errors. We propose RF-GLS, a novel extension of RF for dependent error processes in the same way Generalized Least Squares (GLS) fundamentally extends Ordinary Least Squares (OLS) for linear models under dependence. The key to this extension is the equivalent representation of the local decision-making in a regression tree as a global OLS optimization which is then replaced with a GLS loss to create a GLS-style regression tree. This also synergistically addresses the resampling issue, as the use of GLS loss amounts to resampling uncorrelated contrasts (pre-whitened data) instead of the correlated data. For spatial settings, RF-GLS can be used in conjunction with Gaussian Process correlated errors to generate kriging predictions at new locations. RF becomes a special case of RF-GLS with an identity working covariance matrix. We establish consistency of RF-GLS under beta- (absolutely regular) mixing error processes and show that this general result subsumes important cases like autoregressive time series and spatial Matern Gaussian Processes. As a byproduct, we also establish consistency of RF for beta-mixing processes, which to our knowledge, is the first such result for RF under dependence. We empirically demonstrate the improvement achieved by RF-GLS over RF for both estimation and prediction under dependence.
A Debiased MDI Feature Importance Measure for Random Forests
Jun 26, 2019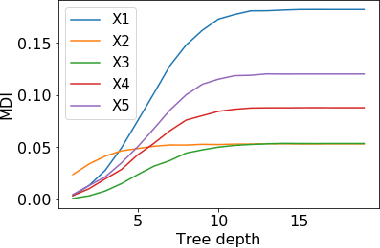
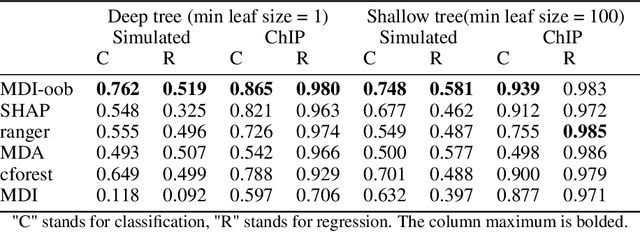
Tree ensembles such as Random Forests have achieved impressive empirical success across a wide variety of applications. To understand how these models make predictions, people routinely turn to feature importance measures calculated from tree ensembles. It has long been known that Mean Decrease Impurity (MDI), one of the most widely used measures of feature importance, incorrectly assigns high importance to noisy features, leading to systematic bias in feature selection. In this paper, we address the feature selection bias of MDI from both theoretical and methodological perspectives. Based on the original definition of MDI by Breiman et al. for a single tree, we derive a tight non-asymptotic bound on the expected bias of MDI importance of noisy features, showing that deep trees have higher (expected) feature selection bias than shallow ones. However, it is not clear how to reduce the bias of MDI using its existing analytical expression. We derive a new analytical expression for MDI, and based on this new expression, we are able to propose a debiased MDI feature importance measure using out-of-bag samples, called MDI-oob. For both the simulated data and a genomic ChIP dataset, MDI-oob achieves state-of-the-art performance in feature selection from Random Forests for both deep and shallow trees.
Large Spectral Density Matrix Estimation by Thresholding
Dec 03, 2018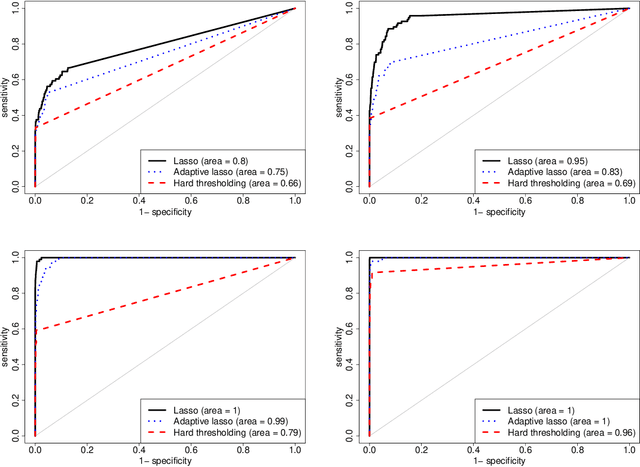
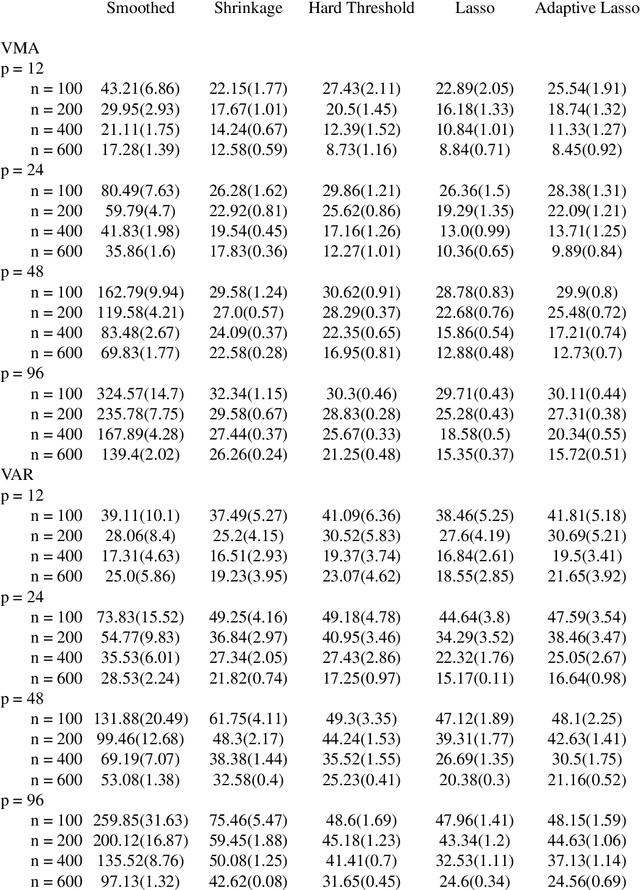

Spectral density matrix estimation of multivariate time series is a classical problem in time series and signal processing. In modern neuroscience, spectral density based metrics are commonly used for analyzing functional connectivity among brain regions. In this paper, we develop a non-asymptotic theory for regularized estimation of high-dimensional spectral density matrices of Gaussian and linear processes using thresholded versions of averaged periodograms. Our theoretical analysis ensures that consistent estimation of spectral density matrix of a $p$-dimensional time series using $n$ samples is possible under high-dimensional regime $\log p / n \rightarrow 0$ as long as the true spectral density is approximately sparse. A key technical component of our analysis is a new concentration inequality of average periodogram around its expectation, which is of independent interest. Our estimation consistency results complement existing results for shrinkage based estimators of multivariate spectral density, which require no assumption on sparsity but only ensure consistent estimation in a regime $p^2/n \rightarrow 0$. In addition, our proposed thresholding based estimators perform consistent and automatic edge selection when learning coherence networks among the components of a multivariate time series. We demonstrate the advantage of our estimators using simulation studies and a real data application on functional connectivity analysis with fMRI data.
Refining interaction search through signed iterative Random Forests
Oct 16, 2018
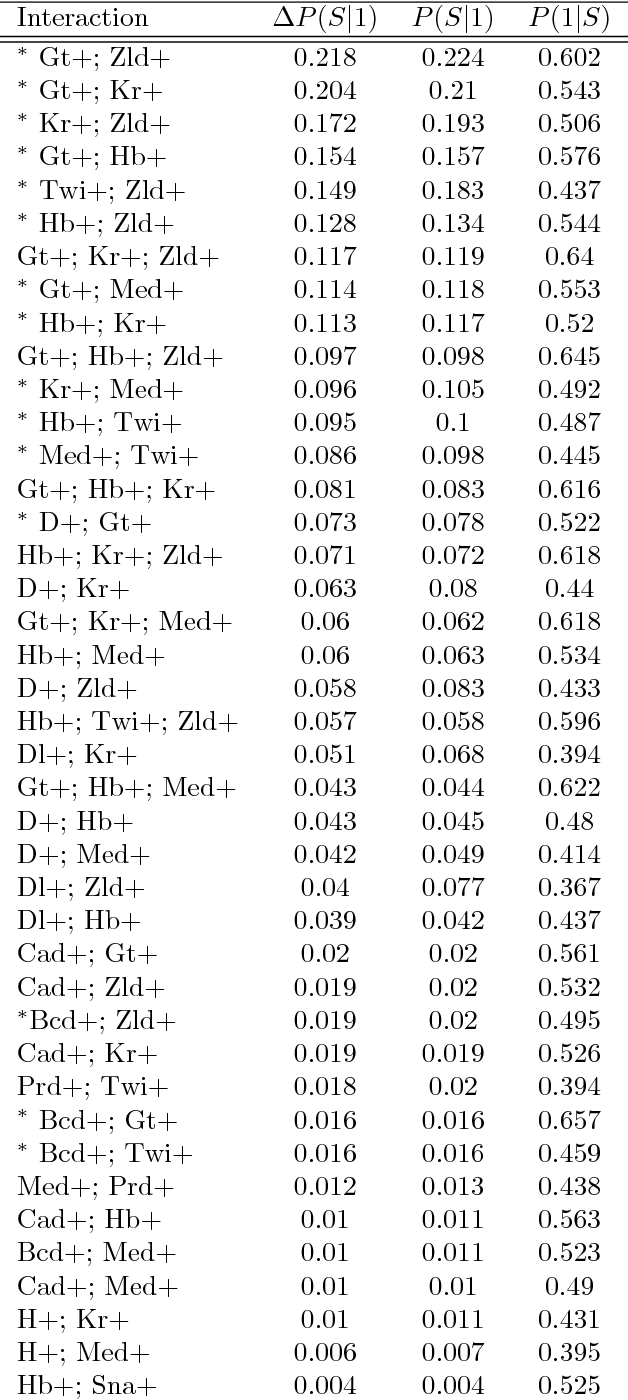
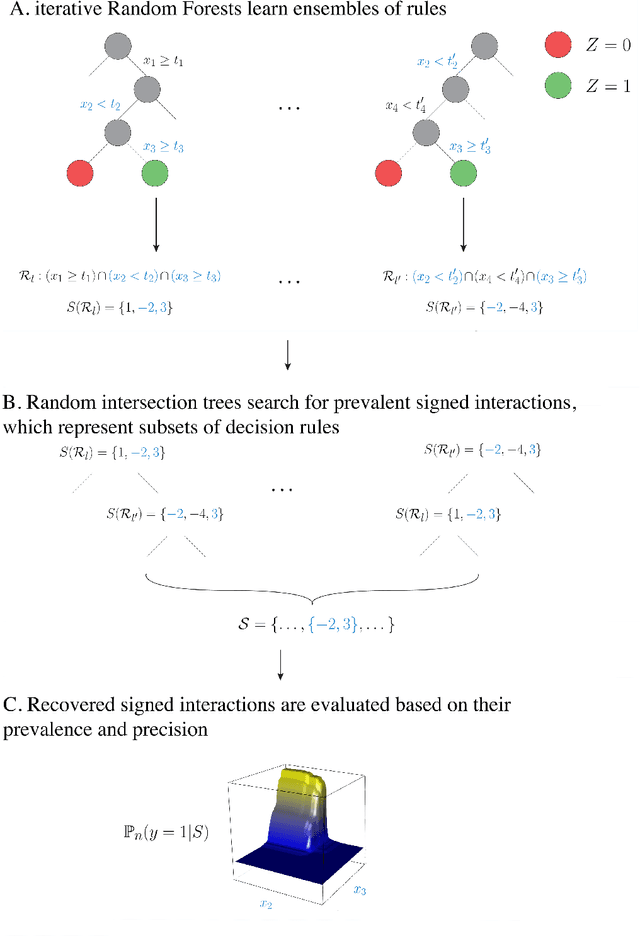
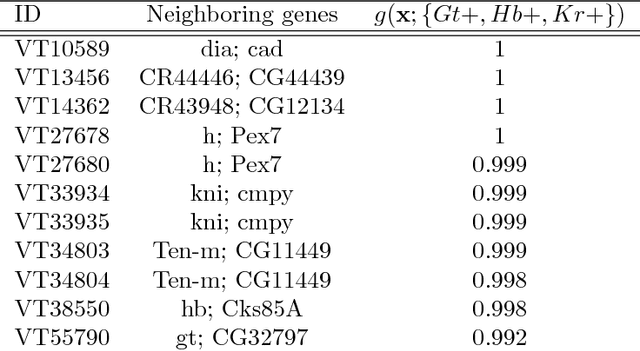
Advances in supervised learning have enabled accurate prediction in biological systems governed by complex interactions among biomolecules. However, state-of-the-art predictive algorithms are typically black-boxes, learning statistical interactions that are difficult to translate into testable hypotheses. The iterative Random Forest algorithm took a step towards bridging this gap by providing a computationally tractable procedure to identify the stable, high-order feature interactions that drive the predictive accuracy of Random Forests (RF). Here we refine the interactions identified by iRF to explicitly map responses as a function of interacting features. Our method, signed iRF, describes subsets of rules that frequently occur on RF decision paths. We refer to these rule subsets as signed interactions. Signed interactions share not only the same set of interacting features but also exhibit similar thresholding behavior, and thus describe a consistent functional relationship between interacting features and responses. We describe stable and predictive importance metrics to rank signed interactions. For each SPIM, we define null importance metrics that characterize its expected behavior under known structure. We evaluate our proposed approach in biologically inspired simulations and two case studies: predicting enhancer activity and spatial gene expression patterns. In the case of enhancer activity, s-iRF recovers one of the few experimentally validated high-order interactions and suggests novel enhancer elements where this interaction may be active. In the case of spatial gene expression patterns, s-iRF recovers all 11 reported links in the gap gene network. By refining the process of interaction recovery, our approach has the potential to guide mechanistic inquiry into systems whose scale and complexity is beyond human comprehension.
High Dimensional Estimation and Multi-Factor Models
Jul 16, 2018
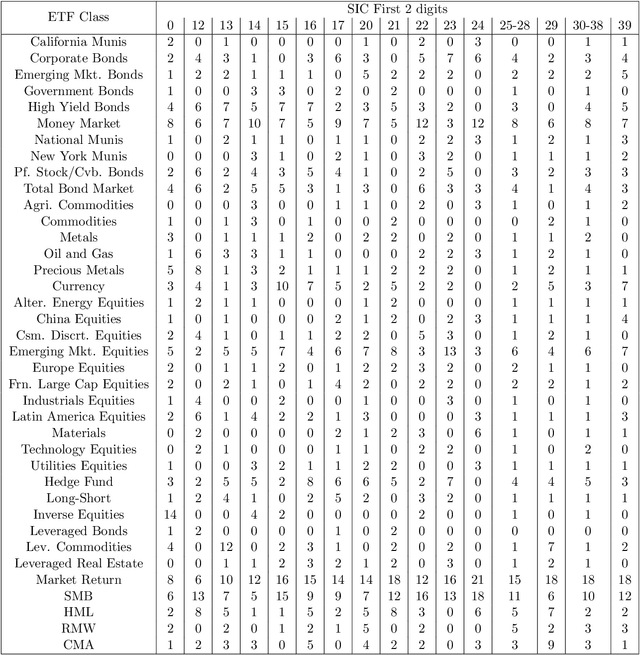


This paper re-investigates the estimation of multiple factor models relaxing the convention that the number of factors is small and using a new approach for identifying factors. We first obtain the collection of all possible factors and then provide a simultaneous test, security by security, of which factors are significant. Since the collection of risk factors is large and highly correlated, high-dimension methods (including the LASSO and prototype clustering) have to be used. The multi-factor model is shown to have a significantly better fit than the Fama-French 5-factor model. Robustness tests are also provided.
Iterative Random Forests to detect predictive and stable high-order interactions
Dec 23, 2017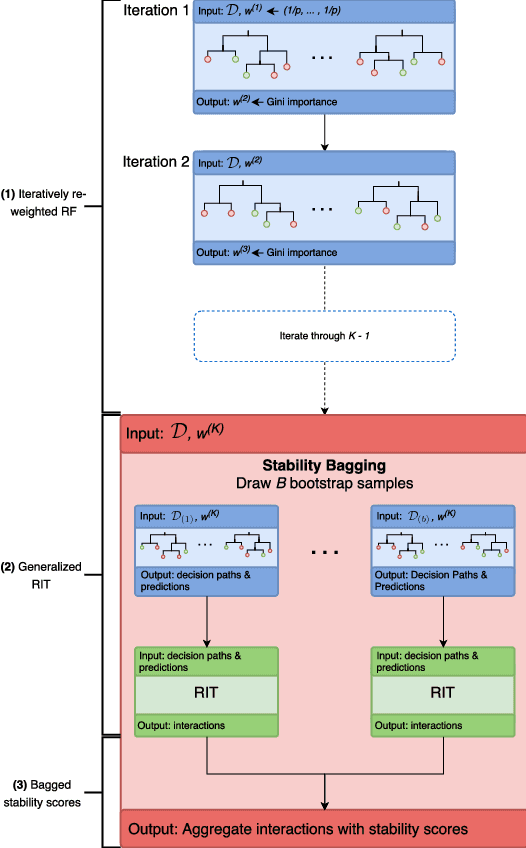
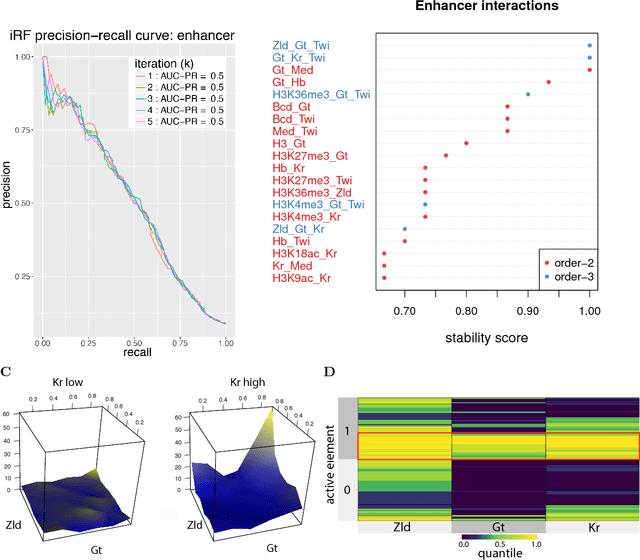
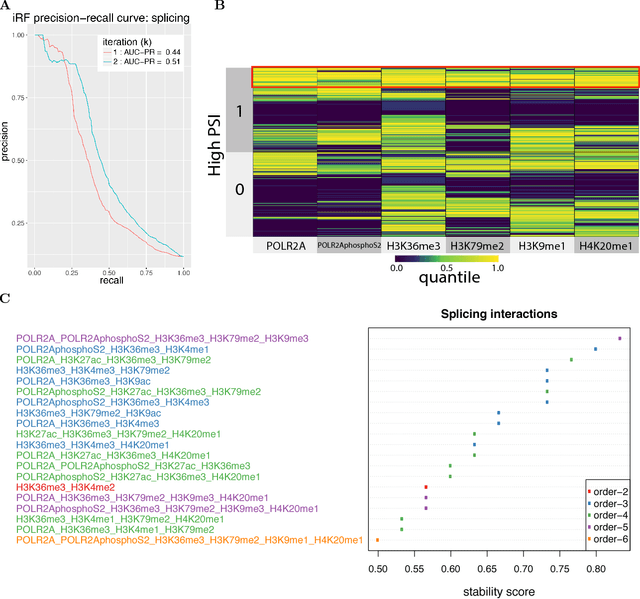
Genomics has revolutionized biology, enabling the interrogation of whole transcriptomes, genome-wide binding sites for proteins, and many other molecular processes. However, individual genomic assays measure elements that interact in vivo as components of larger molecular machines. Understanding how these high-order interactions drive gene expression presents a substantial statistical challenge. Building on Random Forests (RF), Random Intersection Trees (RITs), and through extensive, biologically inspired simulations, we developed the iterative Random Forest algorithm (iRF). iRF trains a feature-weighted ensemble of decision trees to detect stable, high-order interactions with same order of computational cost as RF. We demonstrate the utility of iRF for high-order interaction discovery in two prediction problems: enhancer activity in the early Drosophila embryo and alternative splicing of primary transcripts in human derived cell lines. In Drosophila, among the 20 pairwise transcription factor interactions iRF identifies as stable (returned in more than half of bootstrap replicates), 80% have been previously reported as physical interactions. Moreover, novel third-order interactions, e.g. between Zelda (Zld), Giant (Gt), and Twist (Twi), suggest high-order relationships that are candidates for follow-up experiments. In human-derived cells, iRF re-discovered a central role of H3K36me3 in chromatin-mediated splicing regulation, and identified novel 5th and 6th order interactions, indicative of multi-valent nucleosomes with specific roles in splicing regulation. By decoupling the order of interactions from the computational cost of identification, iRF opens new avenues of inquiry into the molecular mechanisms underlying genome biology.