 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Invariance Coefficients Tests with the Adaptive Multi-Factor Model
Nov 09, 2020
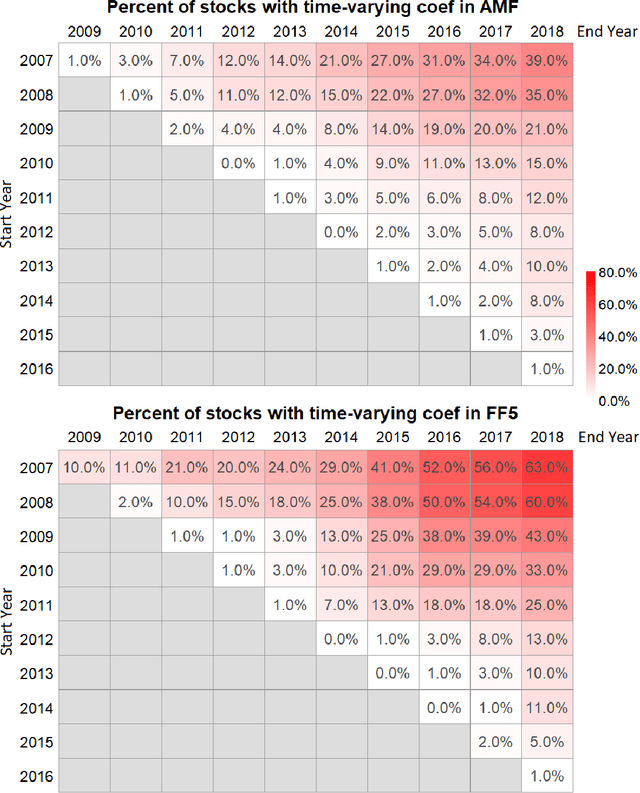
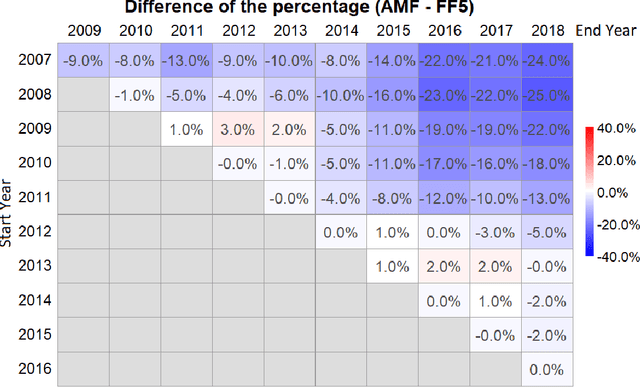
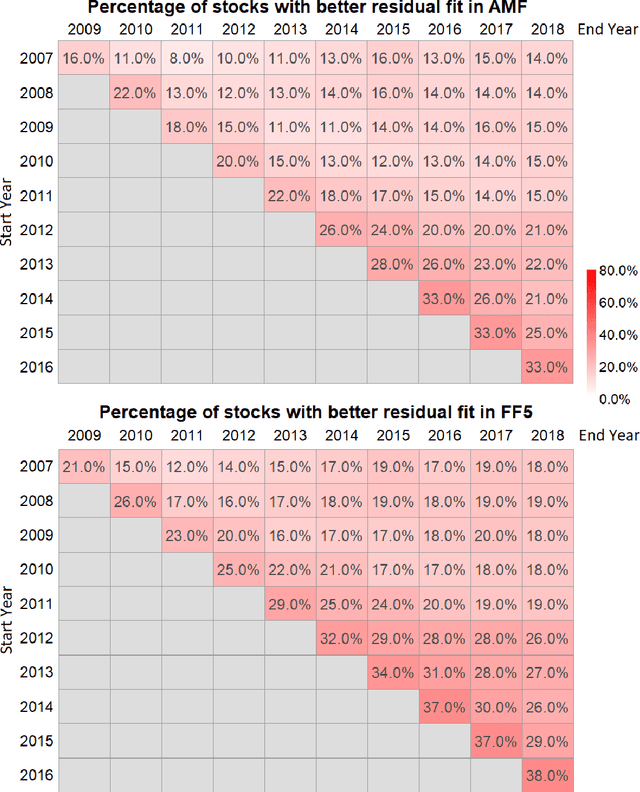
The purpose of this paper is to test the multi-factor beta model implied by the generalized arbitrage pricing theory (APT) and the Adaptive Multi-Factor (AMF) model with the Groupwise Interpretable Basis Selection (GIBS) algorithm, without imposing the exogenous assumption of constant betas. The intercept (arbitrage) tests validate both the AMF and the Fama-French 5-factor (FF5) model. We do the time-invariance tests for the betas for both the AMF model and the FF5 in various time periods. We show that for nearly all time periods with length less than 6 years, the beta coefficients are time-invariant for the AMF model, but not the FF5 model. The beta coefficients are time-varying for both AMF and FF5 models for longer time periods. Therefore, using the dynamic AMF model with a decent rolling window (such as 5 years) is more powerful and stable than the FF5 model.
Low-volatility Anomaly and the Adaptive Multi-Factor Model
Mar 16, 2020

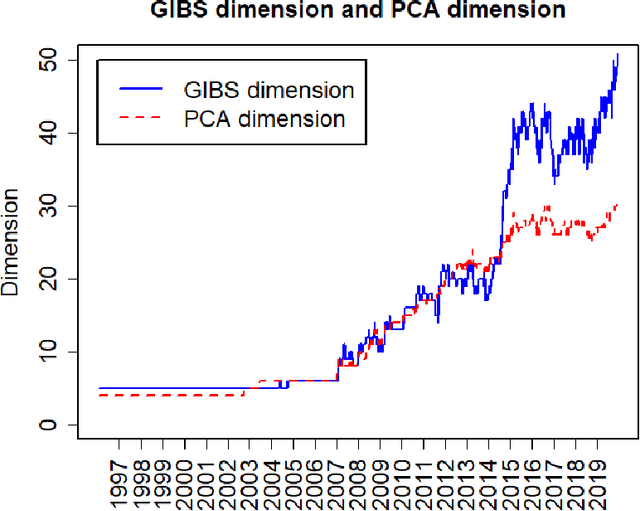

The paper explains the low-volatility anomaly from a new perspective. We use the Adaptive Multi-Factor (AMF) model estimated by the Groupwise Interpretable Basis Selection (GIBS) algorithm to find the basis assets significantly related to each of the portfolios. The AMF results show that the two portfolios load on very different factors, which indicates that the volatility is not an independent measure of risk, but are related to the basis assets and risk factors in the related industries. It is the performance of the loaded factors that results in the low-volatility anomaly. The out-performance of the low-volatility portfolio may not because of its low-risk (which contradicts the risk-premium theory), but because of the out-performance of the risk factors the low-volatility portfolio is loaded on. Also, we compare the AMF model with the traditional Fama-French 5-factor (FF5) model in various aspects, which shows the superior performance of the AMF model over FF5 in many perspectives.
High Dimensional Estimation and Multi-Factor Models
Jul 16, 2018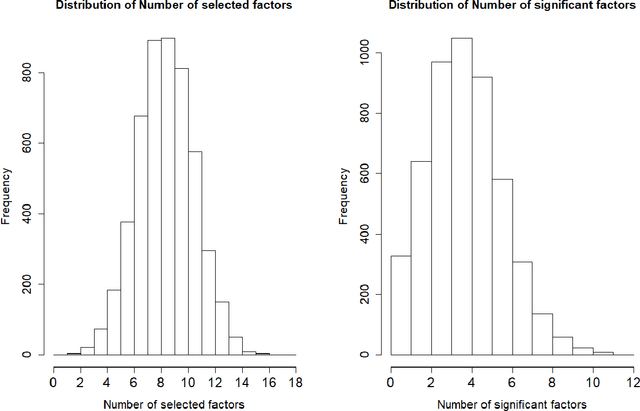
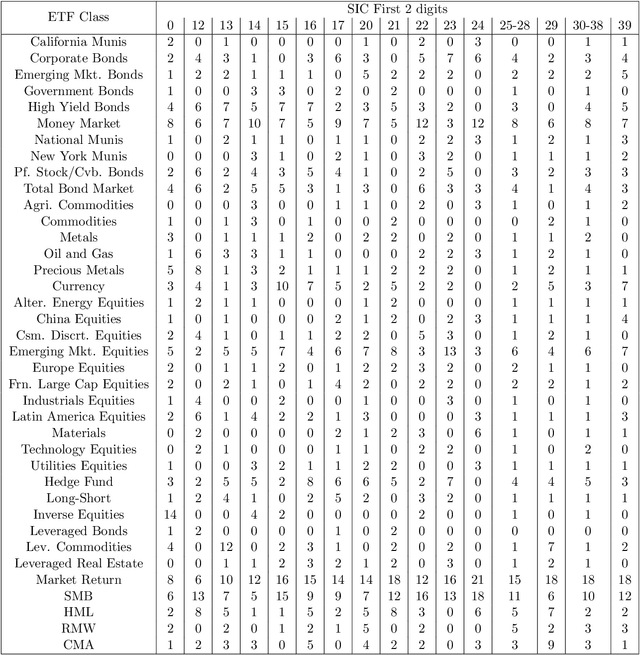


This paper re-investigates the estimation of multiple factor models relaxing the convention that the number of factors is small and using a new approach for identifying factors. We first obtain the collection of all possible factors and then provide a simultaneous test, security by security, of which factors are significant. Since the collection of risk factors is large and highly correlated, high-dimension methods (including the LASSO and prototype clustering) have to be used. The multi-factor model is shown to have a significantly better fit than the Fama-French 5-factor model. Robustness tests are also provided.