 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Sequential Causal Optimization of Process Interventions
Dec 22, 2025



Prescriptive Process Monitoring (PresPM) recommends interventions during business processes to optimize key performance indicators (KPIs). In realistic settings, interventions are rarely isolated: organizations need to align sequences of interventions to jointly steer the outcome of a case. Existing PresPM approaches fall short in this respect. Many focus on a single intervention decision, while others treat multiple interventions independently, ignoring how they interact over time. Methods that do address these dependencies depend either on simulation or data augmentation to approximate the process to train a Reinforcement Learning (RL) agent, which can create a reality gap and introduce bias. We introduce SCOPE, a PresPM approach that learns aligned sequential intervention recommendations. SCOPE employs backward induction to estimate the effect of each candidate intervention action, propagating its impact from the final decision point back to the first. By leveraging causal learners, our method can utilize observational data directly, unlike methods that require constructing process approximations for reinforcement learning. Experiments on both an existing synthetic dataset and a new semi-synthetic dataset show that SCOPE consistently outperforms state-of-the-art PresPM techniques in optimizing the KPI. The novel semi-synthetic setup, based on a real-life event log, is provided as a reusable benchmark for future work on sequential PresPM.
Time Series Foundation Models for Process Model Forecasting
Dec 08, 2025



Process Model Forecasting (PMF) aims to predict how the control-flow structure of a process evolves over time by modeling the temporal dynamics of directly-follows (DF) relations, complementing predictive process monitoring that focuses on single-case prefixes. Prior benchmarks show that machine learning and deep learning models provide only modest gains over statistical baselines, mainly due to the sparsity and heterogeneity of the DF time series. We investigate Time Series Foundation Models (TSFMs), large pre-trained models for generic time series, as an alternative for PMF. Using DF time series derived from real-life event logs, we compare zero-shot use of TSFMs, without additional training, with fine-tuned variants adapted on PMF-specific data. TSFMs generally achieve lower forecasting errors (MAE and RMSE) than traditional and specialized models trained from scratch on the same logs, indicating effective transfer of temporal structure from non-process domains. While fine-tuning can further improve accuracy, the gains are often small and may disappear on smaller or more complex datasets, so zero-shot use remains a strong default. Our study highlights the generalization capability and data efficiency of TSFMs for process-related time series and, to the best of our knowledge, provides the first systematic evaluation of temporal foundation models for PMF.
Generating Realistic Adversarial Examples for Business Processes using Variational Autoencoders
Nov 21, 2024



In predictive process monitoring, predictive models are vulnerable to adversarial attacks, where input perturbations can lead to incorrect predictions. Unlike in computer vision, where these perturbations are designed to be imperceptible to the human eye, the generation of adversarial examples in predictive process monitoring poses unique challenges. Minor changes to the activity sequences can create improbable or even impossible scenarios to occur due to underlying constraints such as regulatory rules or process constraints. To address this, we focus on generating realistic adversarial examples tailored to the business process context, in contrast to the imperceptible, pixel-level changes commonly seen in computer vision adversarial attacks. This paper introduces two novel latent space attacks, which generate adversaries by adding noise to the latent space representation of the input data, rather than directly modifying the input attributes. These latent space methods are domain-agnostic and do not rely on process-specific knowledge, as we restrict the generation of adversarial examples to the learned class-specific data distributions by directly perturbing the latent space representation of the business process executions. We evaluate these two latent space methods with six other adversarial attacking methods on eleven real-life event logs and four predictive models. The first three attacking methods directly permute the activities of the historically observed business process executions. The fourth method constrains the adversarial examples to lie within the same data distribution as the original instances, by projecting the adversarial examples to the original data distribution.
Generating Feasible and Plausible Counterfactual Explanations for Outcome Prediction of Business Processes
Mar 14, 2024



In recent years, various machine and deep learning architectures have been successfully introduced to the field of predictive process analytics. Nevertheless, the inherent opacity of these algorithms poses a significant challenge for human decision-makers, hindering their ability to understand the reasoning behind the predictions. This growing concern has sparked the introduction of counterfactual explanations, designed as human-understandable what if scenarios, to provide clearer insights into the decision-making process behind undesirable predictions. The generation of counterfactual explanations, however, encounters specific challenges when dealing with the sequential nature of the (business) process cases typically used in predictive process analytics. Our paper tackles this challenge by introducing a data-driven approach, REVISEDplus, to generate more feasible and plausible counterfactual explanations. First, we restrict the counterfactual algorithm to generate counterfactuals that lie within a high-density region of the process data, ensuring that the proposed counterfactuals are realistic and feasible within the observed process data distribution. Additionally, we ensure plausibility by learning sequential patterns between the activities in the process cases, utilising Declare language templates. Finally, we evaluate the properties that define the validity of counterfactuals.
Extracting Process-Aware Decision Models from Object-Centric Process Data
Jan 26, 2024Organizations execute decisions within business processes on a daily basis whilst having to take into account multiple stakeholders who might require multiple point of views of the same process. Moreover, the complexity of the information systems running these business processes is generally high as they are linked to databases storing all the relevant data and aspects of the processes. Given the presence of multiple objects within an information system which support the processes in their enactment, decisions are naturally influenced by both these perspectives, logged in object-centric process logs. However, the discovery of such decisions from object-centric process logs is not straightforward as it requires to correctly link the involved objects whilst considering the sequential constraints that business processes impose as well as correctly discovering what a decision actually does. This paper proposes the first object-centric decision-mining algorithm called Integrated Object-centric Decision Discovery Algorithm (IODDA). IODDA is able to discover how a decision is structured as well as how a decision is made. Moreover, IODDA is able to discover which activities and object types are involved in the decision-making process. Next, IODDA is demonstrated with the first artificial knowledge-intensive process logs whose log generators are provided to the research community.
Predicting student performance using sequence classification with time-based windows
Aug 16, 2022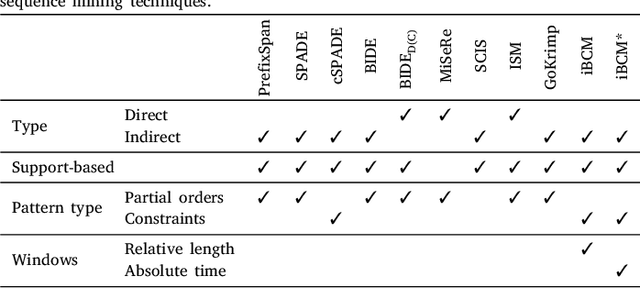
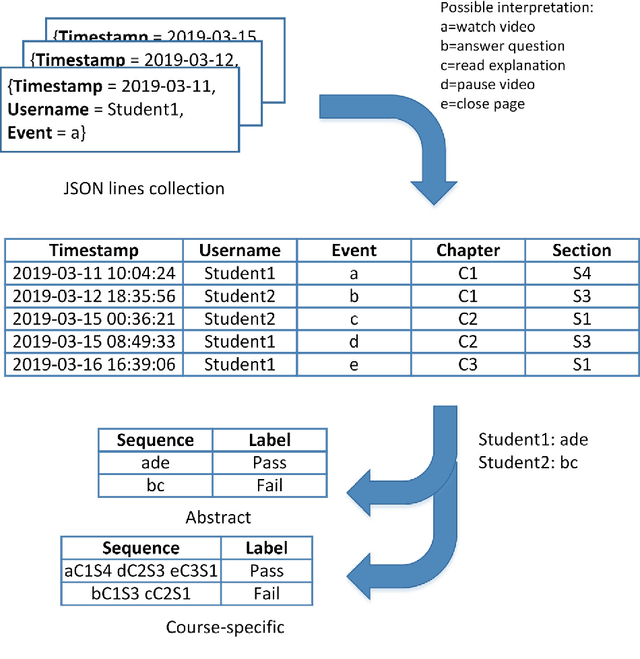
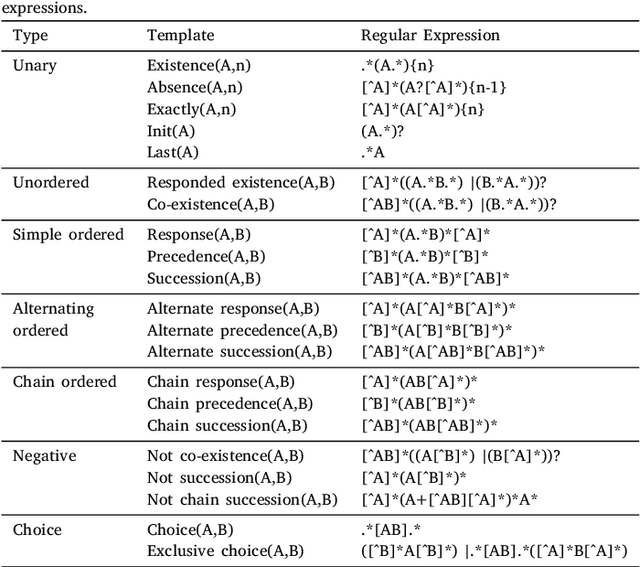
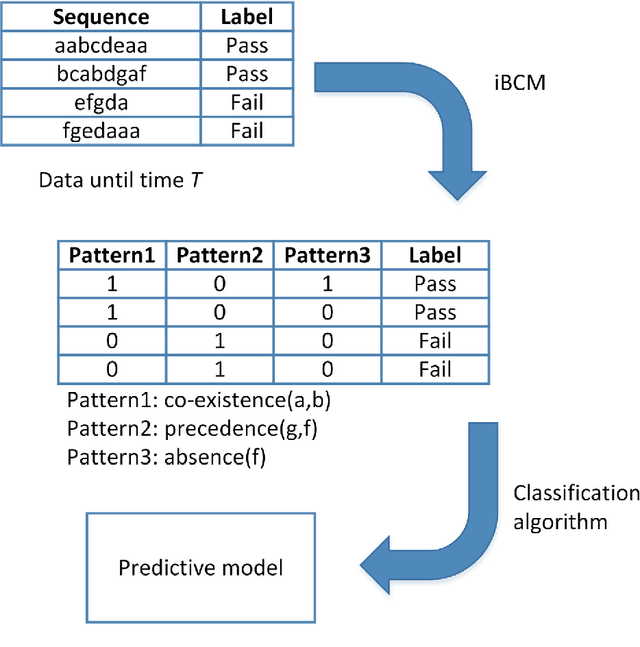
A growing number of universities worldwide use various forms of online and blended learning as part of their academic curricula. Furthermore, the recent changes caused by the COVID-19 pandemic have led to a drastic increase in importance and ubiquity of online education. Among the major advantages of e-learning is not only improving students' learning experience and widening their educational prospects, but also an opportunity to gain insights into students' learning processes with learning analytics. This study contributes to the topic of improving and understanding e-learning processes in the following ways. First, we demonstrate that accurate predictive models can be built based on sequential patterns derived from students' behavioral data, which are able to identify underperforming students early in the course. Second, we investigate the specificity-generalizability trade-off in building such predictive models by investigating whether predictive models should be built for every course individually based on course-specific sequential patterns, or across several courses based on more general behavioral patterns. Finally, we present a methodology for capturing temporal aspects in behavioral data and analyze its influence on the predictive performance of the models. The results of our improved sequence classification technique are capable to predict student performance with high levels of accuracy, reaching 90 percent for course-specific models.
Explainable Artificial Intelligence in Process Mining: Assessing the Explainability-Performance Trade-Off in Outcome-Oriented Predictive Process Monitoring
Mar 30, 2022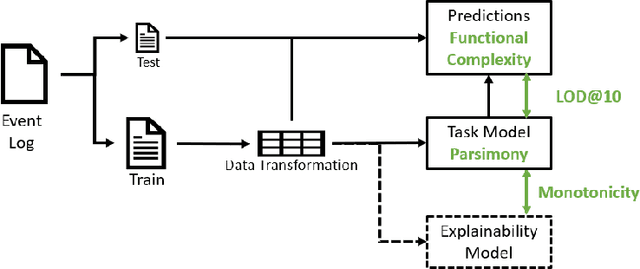
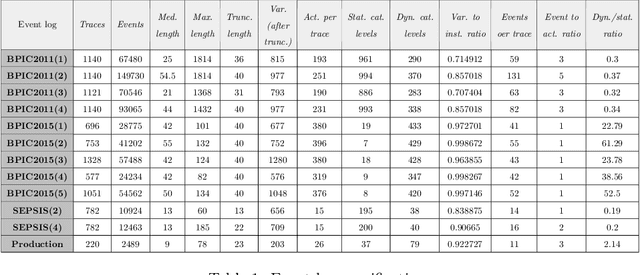
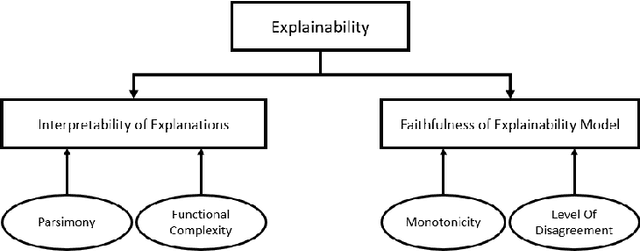
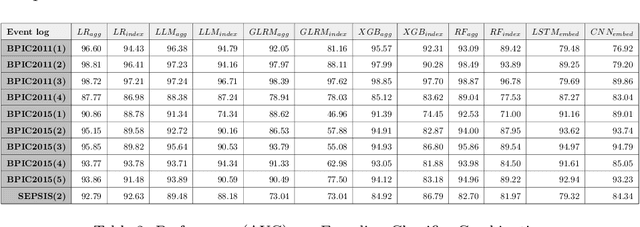
Recently, a shift has been made in the field of Outcome-Oriented Predictive Process Monitoring (OOPPM) to use models from the eXplainable Artificial Intelligence paradigm, however the evaluation still occurs mainly through performance-based metrics not accounting for the implications and lack of actionability of the explanations. In this paper, we define explainability by the interpretability of the explanations (through the widely-used XAI properties parsimony and functional complexity) and the faithfulness of the explainability model (through monotonicity and level of disagreement). The introduced properties are analysed along the event, case, and control flow perspective that are typical of a process-based analysis. This allows to quantitatively compare, inter alia, inherently created explanations (e.g., logistic regression coefficients) with post-hoc explanations (e.g., Shapley values). Moreover, this paper contributes a guideline named X-MOP to practitioners to select the appropriate model based on the event log specifications and the task at hand, by providing insight into how the varying preprocessing, model complexity and post-hoc explainability techniques typical in OOPPM influence the explainability of the model. To this end, we benchmark seven classifiers on thirteen real-life events logs.
Process Model Forecasting Using Time Series Analysis of Event Sequence Data
May 03, 2021



Process analytics is the field focusing on predictions for individual process instances or overall process models. At the instance level, various novel techniques have been recently devised, tackling next activity, remaining time, and outcome prediction. At the model level, there is a notable void. It is the ambition of this paper to fill this gap. To this end, we develop a technique to forecast the entire process model from historical event data. A forecasted model is a will-be process model representing a probable future state of the overall process. Such a forecast helps to investigate the consequences of drift and emerging bottlenecks. Our technique builds on a representation of event data as multiple time series, each capturing the evolution of a behavioural aspect of the process model, such that corresponding forecasting techniques can be applied. Our implementation demonstrates the accuracy of our technique on real-world event log data.
Conformance Checking of Mixed-paradigm Process Models
Nov 23, 2020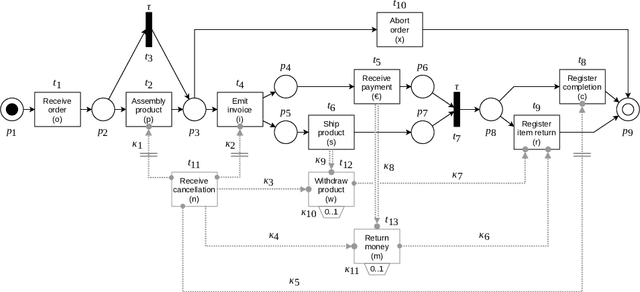
Mixed-paradigm process models integrate strengths of procedural and declarative representations like Petri nets and Declare. They are specifically interesting for process mining because they allow capturing complex behaviour in a compact way. A key research challenge for the proliferation of mixed-paradigm models for process mining is the lack of corresponding conformance checking techniques. In this paper, we address this problem by devising the first approach that works with intertwined state spaces of mixed-paradigm models. More specifically, our approach uses an alignment-based replay to explore the state space and compute trace fitness in a procedural way. In every state, the declarative constraints are separately updated, such that violations disable the corresponding activities. Our technique provides for an efficient replay towards an optimal alignment by respecting all orthogonal Declare constraints. We have implemented our technique in ProM and demonstrate its performance in an evaluation with real-world event logs.
Predictive Process Model Monitoring using Recurrent Neural Networks
Nov 05, 2020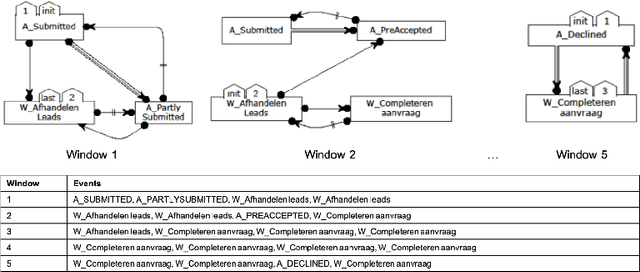
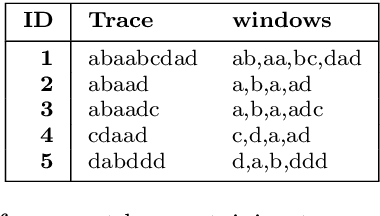
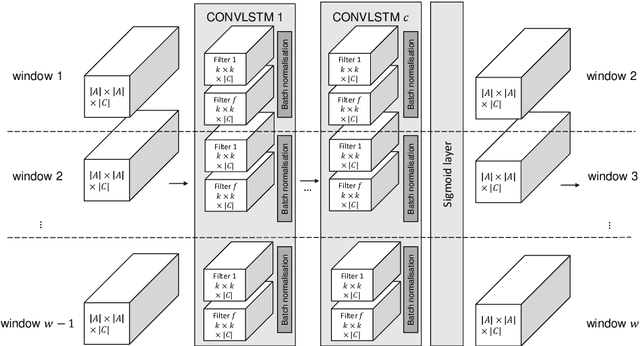
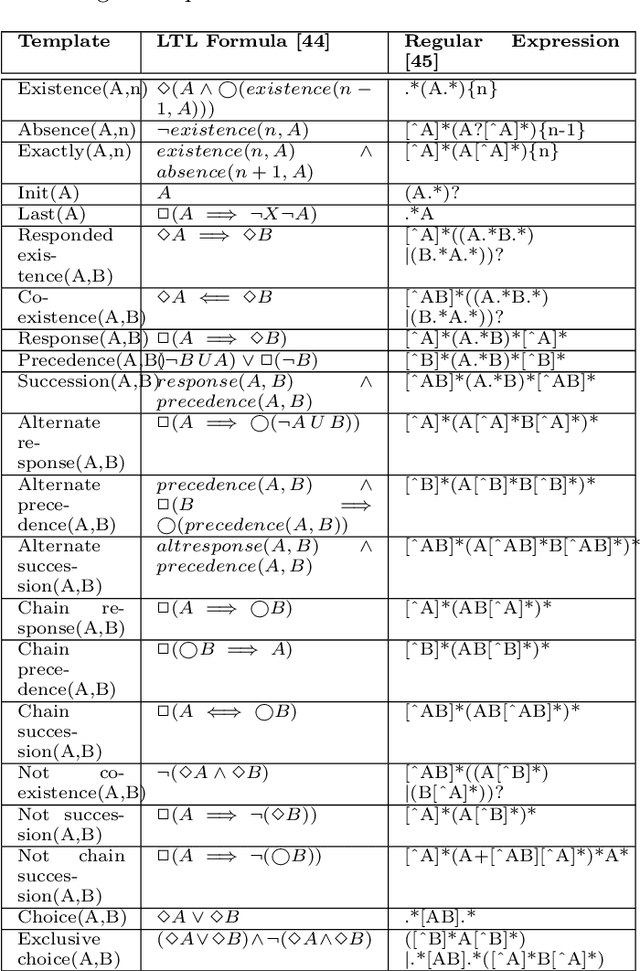
The field of predictive process monitoring focuses on modelling future characteristics of running business process instances, typically by either predicting the outcome of particular objectives (e.g. completion (time), cost), or next-in-sequence prediction (e.g. what is the next activity to execute). This paper introduces Processes-As-Movies (PAM), a technique that provides a middle ground between these predictive monitoring. It does so by capturing declarative process constraints between activities in various windows of a process execution trace, which represent a declarative process model at subsequent stages of execution. This high-dimensional representation of a process model allows the application of predictive modelling on how such constraints appear and vanish throughout a process' execution. Various recurrent neural network topologies tailored to high-dimensional input are used to model the process model evolution with windows as time steps, including encoder-decoder long short-term memory networks, and convolutional long short-term memory networks. Results show that these topologies are very effective in terms of accuracy and precision to predict a process model's future state, which allows process owners to simultaneously verify what linear temporal logic rules hold in a predicted process window (objective-based), and verify what future execution traces are allowed by all the constraints together (trace-based).