 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowSSC: Universal Generative Monocular Semantic Scene Completion via One-Step Latent Diffusion
Jan 21, 2026Semantic Scene Completion (SSC) from monocular RGB images is a fundamental yet challenging task due to the inherent ambiguity of inferring occluded 3D geometry from a single view. While feed-forward methods have made progress, they often struggle to generate plausible details in occluded regions and preserve the fundamental spatial relationships of objects. Such accurate generative reasoning capability for the entire 3D space is critical in real-world applications. In this paper, we present FlowSSC, the first generative framework applied directly to monocular semantic scene completion. FlowSSC treats the SSC task as a conditional generation problem and can seamlessly integrate with existing feed-forward SSC methods to significantly boost their performance. To achieve real-time inference without compromising quality, we introduce Shortcut Flow-matching that operates in a compact triplane latent space. Unlike standard diffusion models that require hundreds of steps, our method utilizes a shortcut mechanism to achieve high-fidelity generation in a single step, enabling practical deployment in autonomous systems. Extensive experiments on SemanticKITTI demonstrate that FlowSSC achieves state-of-the-art performance, significantly outperforming existing baselines.
PROMPTHEUS: A Human-Centered Pipeline to Streamline SLRs with LLMs
Oct 21, 2024The growing volume of academic publications poses significant challenges for researchers conducting timely and accurate Systematic Literature Reviews, particularly in fast-evolving fields like artificial intelligence. This growth of academic literature also makes it increasingly difficult for lay people to access scientific knowledge effectively, meaning academic literature is often misrepresented in the popular press and, more broadly, in society. Traditional SLR methods are labor-intensive and error-prone, and they struggle to keep up with the rapid pace of new research. To address these issues, we developed \textit{PROMPTHEUS}: an AI-driven pipeline solution that automates the SLR process using Large Language Models. We aimed to enhance efficiency by reducing the manual workload while maintaining the precision and coherence required for comprehensive literature synthesis. PROMPTHEUS automates key stages of the SLR process, including systematic search, data extraction, topic modeling using BERTopic, and summarization with transformer models. Evaluations conducted across five research domains demonstrate that PROMPTHEUS reduces review time, achieves high precision, and provides coherent topic organization, offering a scalable and effective solution for conducting literature reviews in an increasingly crowded research landscape. In addition, such tools may reduce the increasing mistrust in science by making summarization more accessible to laypeople. The code for this project can be found on the GitHub repository at https://github.com/joaopftorres/PROMPTHEUS.git
DALL-M: Context-Aware Clinical Data Augmentation with LLMs
Jul 11, 2024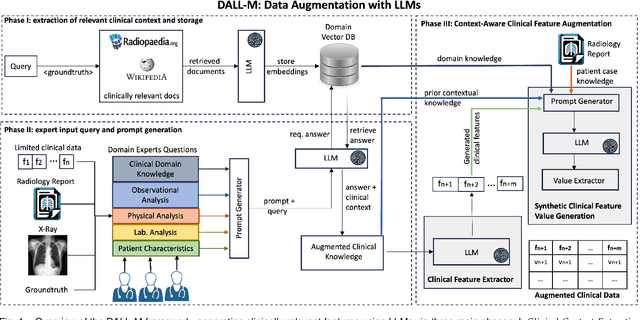


X-ray images are vital in medical diagnostics, but their effectiveness is limited without clinical context. Radiologists often find chest X-rays insufficient for diagnosing underlying diseases, necessitating comprehensive clinical features and data integration. We present a novel technique to enhance the clinical context through augmentation techniques with clinical tabular data, thereby improving its applicability and reliability in AI medical diagnostics. To address this, we introduce a pioneering approach to clinical data augmentation that employs large language models (LLMs) to generate patient contextual synthetic data. This methodology is crucial for training more robust deep learning models in healthcare. It preserves the integrity of real patient data while enriching the dataset with contextually relevant synthetic features, significantly enhancing model performance. DALL-M uses a three-phase feature generation process: (i) clinical context storage, (ii) expert query generation, and (iii) context-aware feature augmentation. DALL-M generates new, clinically relevant features by synthesizing chest X-ray images and reports. Applied to 799 cases using nine features from the MIMIC-IV dataset, it created an augmented set of 91 features. This is the first work to generate contextual values for existing and new features based on patients' X-ray reports, gender, and age and to produce new contextual knowledge during data augmentation. Empirical validation with machine learning models, including Decision Trees, Random Forests, XGBoost, and TabNET, showed significant performance improvements. Incorporating augmented features increased the F1 score by 16.5% and Precision and Recall by approximately 25%. DALL-M addresses a critical gap in clinical data augmentation, offering a robust framework for generating contextually enriched datasets.
SelfReDepth: Self-Supervised Real-Time Depth Restoration for Consumer-Grade Sensors
Jun 05, 2024Depth maps produced by consumer-grade sensors suffer from inaccurate measurements and missing data from either system or scene-specific sources. Data-driven denoising algorithms can mitigate such problems. However, they require vast amounts of ground truth depth data. Recent research has tackled this limitation using self-supervised learning techniques, but it requires multiple RGB-D sensors. Moreover, most existing approaches focus on denoising single isolated depth maps or specific subjects of interest, highlighting a need for methods to effectively denoise depth maps in real-time dynamic environments. This paper extends state-of-the-art approaches for depth-denoising commodity depth devices, proposing SelfReDepth, a self-supervised deep learning technique for depth restoration, via denoising and hole-filling by inpainting full-depth maps captured with RGB-D sensors. The algorithm targets depth data in video streams, utilizing multiple sequential depth frames coupled with color data to achieve high-quality depth videos with temporal coherence. Finally, SelfReDepth is designed to be compatible with various RGB-D sensors and usable in real-time scenarios as a pre-processing step before applying other depth-dependent algorithms. Our results demonstrate our approach's real-time performance on real-world datasets. They show that it outperforms state-of-the-art denoising and restoration performance at over 30fps on Commercial Depth Cameras, with potential benefits for augmented and mixed-reality applications.
* 13pp, 5 figures, 1 table
MDF-Net: Multimodal Dual-Fusion Network for Abnormality Detection using CXR Images and Clinical Data
Feb 26, 2023This study aims to investigate the effects of including patients' clinical information on the performance of deep learning (DL) classifiers for disease location in chest X-ray images. Although current classifiers achieve high performance using chest X-ray images alone, our interviews with radiologists indicate that clinical data is highly informative and essential for interpreting images and making proper diagnoses. In this work, we propose a novel architecture consisting of two fusion methods that enable the model to simultaneously process patients' clinical data (structured data) and chest X-rays (image data). Since these data modalities are in different dimensional spaces, we propose a spatial arrangement strategy, termed spatialization, to facilitate the multimodal learning process in a Mask R-CNN model. We performed an extensive experimental evaluation comprising three datasets with different modalities: MIMIC CXR (chest X-ray images), MIMIC IV-ED (patients' clinical data), and REFLACX (annotations of disease locations in chest X-rays). Results show that incorporating patients' clinical data in a DL model together with the proposed fusion methods improves the performance of disease localization in chest X-rays by 12\% in terms of Average Precision compared to a standard Mask R-CNN using only chest X-rays. Further ablation studies also emphasize the importance of multimodal DL architectures and the incorporation of patients' clinical data in disease localisation. The architecture proposed in this work is publicly available to promote the scientific reproducibility of our study (https://github.com/ChihchengHsieh/multimodal-abnormalities-detection).
Immersive Virtual Colonoscopy Viewer for Colorectal Diagnosis
Feb 06, 2023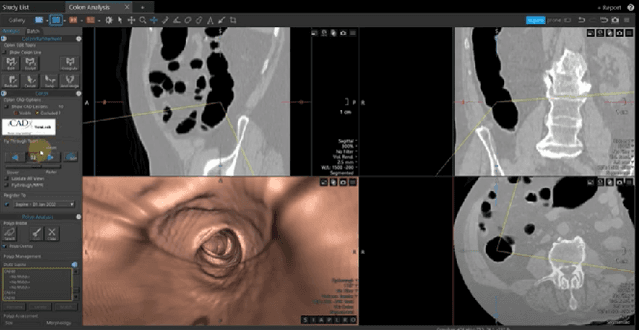


Desktop-based virtual colonoscopy has been proven to be an asset in the identification of colon anomalies. The process is accurate, although time-consuming. The use of immersive interfaces for virtual colonoscopy is incipient and not yet understood. In this work, we present a new design exploring elements of the VR paradigm to make the immersive analysis more efficient while still effective. We also plan the conduction of experiments with experts to assess the multi-factor influences of coverage, duration, and diagnostic accuracy.
Integrating Eye-Gaze Data into CXR DL Approaches: A Preliminary study
Feb 06, 2023


This paper proposes a novel multimodal DL architecture incorporating medical images and eye-tracking data for abnormality detection in chest x-rays. Our results show that applying eye gaze data directly into DL architectures does not show superior predictive performance in abnormality detection chest X-rays. These results support other works in the literature and suggest that human-generated data, such as eye gaze, needs a more thorough investigation before being applied to DL architectures.
Benchmark Evaluation of Counterfactual Algorithms for XAI: From a White Box to a Black Box
Mar 04, 2022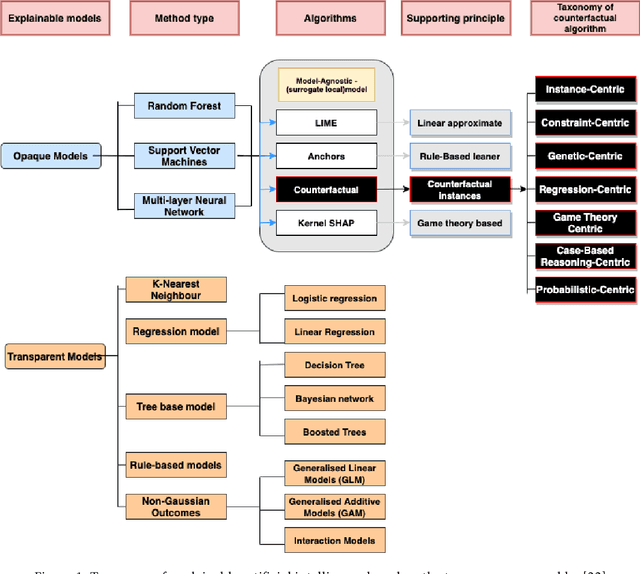
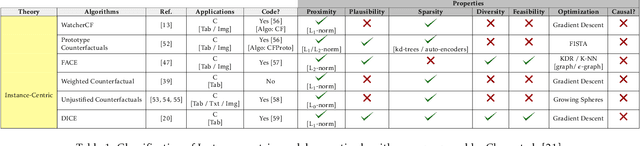
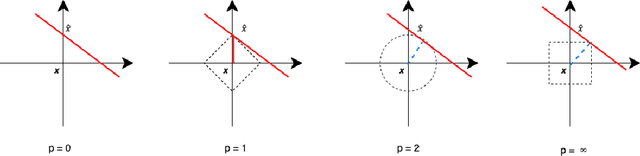

Counterfactual explanations have recently been brought to light as a potentially crucial response to obtaining human-understandable explanations from predictive models in Explainable Artificial Intelligence (XAI). Despite the fact that various counterfactual algorithms have been proposed, the state of the art research still lacks standardised protocols to evaluate the quality of counterfactual explanations. In this work, we conducted a benchmark evaluation across different model agnostic counterfactual algorithms in the literature (DiCE, WatcherCF, prototype, unjustifiedCF), and we investigated the counterfactual generation process on different types of machine learning models ranging from a white box (decision tree) to a grey-box (random forest) and a black box (neural network). We evaluated the different counterfactual algorithms using several metrics including proximity, interpretability and functionality for five datasets. The main findings of this work are the following: (1) without guaranteeing plausibility in the counterfactual generation process, one cannot have meaningful evaluation results. This means that all explainable counterfactual algorithms that do not take into consideration plausibility in their internal mechanisms cannot be evaluated with the current state of the art evaluation metrics; (2) the counterfactual generated are not impacted by the different types of machine learning models; (3) DiCE was the only tested algorithm that was able to generate actionable and plausible counterfactuals, because it provides mechanisms to constraint features; (4) WatcherCF and UnjustifiedCF are limited to continuous variables and can not deal with categorical data.
Improving X-ray Diagnostics through Eye-Tracking and XR
Mar 03, 2022
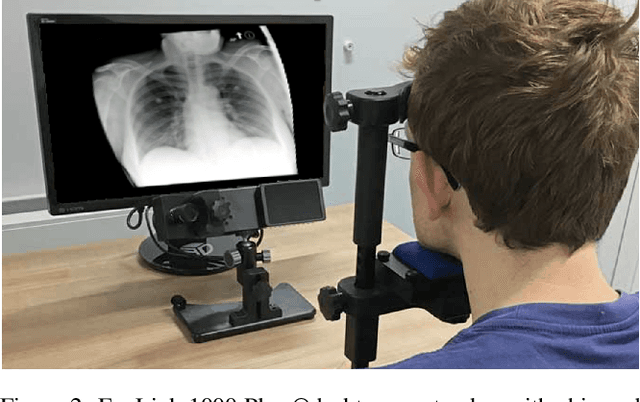
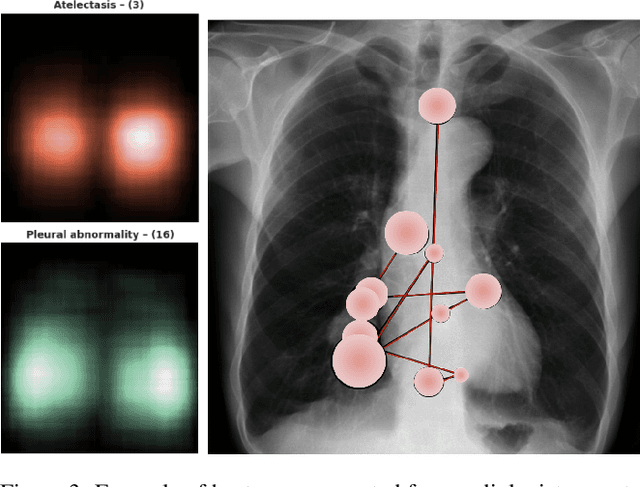
There is a growing need to assist radiologists in performing X-ray readings and diagnoses fast, comfortably, and effectively. As radiologists strive to maximize productivity, it is essential to consider the impact of reading rooms in interpreting complex examinations and ensure that higher volume and reporting speeds do not compromise patient outcomes. Virtual Reality (VR) is a disruptive technology for clinical practice in assessing X-ray images. We argue that conjugating eye-tracking with VR devices and Machine Learning may overcome obstacles posed by inadequate ergonomic postures and poor room conditions that often cause erroneous diagnostics when professionals examine digital images.
Counterfactuals and Causability in Explainable Artificial Intelligence: Theory, Algorithms, and Applications
Mar 07, 2021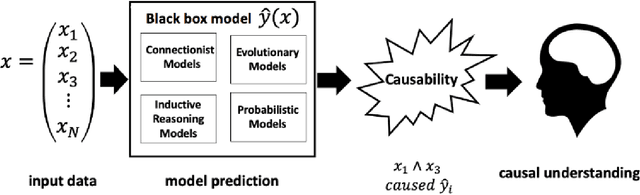



There has been a growing interest in model-agnostic methods that can make deep learning models more transparent and explainable to a user. Some researchers recently argued that for a machine to achieve a certain degree of human-level explainability, this machine needs to provide human causally understandable explanations, also known as causability. A specific class of algorithms that have the potential to provide causability are counterfactuals. This paper presents an in-depth systematic review of the diverse existing body of literature on counterfactuals and causability for explainable artificial intelligence. We performed an LDA topic modelling analysis under a PRISMA framework to find the most relevant literature articles. This analysis resulted in a novel taxonomy that considers the grounding theories of the surveyed algorithms, together with their underlying properties and applications in real-world data. This research suggests that current model-agnostic counterfactual algorithms for explainable AI are not grounded on a causal theoretical formalism and, consequently, cannot promote causability to a human decision-maker. Our findings suggest that the explanations derived from major algorithms in the literature provide spurious correlations rather than cause/effects relationships, leading to sub-optimal, erroneous or even biased explanations. This paper also advances the literature with new directions and challenges on promoting causability in model-agnostic approaches for explainable artificial intelligence.