 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitive learning to generate sparse representations for associative memory
Jan 05, 2023One of the most well established brain principles, hebbian learning, has led to the theoretical concept of neural assemblies. Based on it, many interesting brain theories have spawned. Palm's work implements this concept through binary associative memory, in a model that not only has a wide cognitive explanatory power but also makes neuroscientific predictions. Yet, associative memory can only work with logarithmic sparse representations, which makes it extremely difficult to apply the model to real data. We propose a biologically plausible network that encodes images into codes that are suitable for associative memory. It is organized into groups of neurons that specialize on local receptive fields, and learn through a competitive scheme. After conducting auto- and hetero-association experiments on two visual data sets, we can conclude that our network not only beats sparse coding baselines, but also that it comes close to the performance achieved using optimal random codes.
The smooth output assumption, and why deep networks are better than wide ones
Nov 25, 2022When several models have similar training scores, classical model selection heuristics follow Occam's razor and advise choosing the ones with least capacity. Yet, modern practice with large neural networks has often led to situations where two networks with exactly the same number of parameters score similar on the training set, but the deeper one generalizes better to unseen examples. With this in mind, it is well accepted that deep networks are superior to shallow wide ones. However, theoretically there is no difference between the two. In fact, they are both universal approximators. In this work we propose a new unsupervised measure that predicts how well a model will generalize. We call it the output sharpness, and it is based on the fact that, in reality, boundaries between concepts are generally unsharp. We test this new measure on several neural network settings, and architectures, and show how generally strong the correlation is between our metric, and test set performance. Having established this measure, we give a mathematical probabilistic argument that predicts network depth to be correlated with our proposed measure. After verifying this in real data, we are able to formulate the key argument of the work: output sharpness hampers generalization; deep networks have an in built bias against it; therefore, deep networks beat wide ones. All in all the work not only provides a helpful predictor of overfitting that can be used in practice for model selection (or even regularization), but also provides a much needed theoretical grounding for the success of modern deep neural networks.
Understanding the double descent curve in Machine Learning
Nov 18, 2022The theory of bias-variance used to serve as a guide for model selection when applying Machine Learning algorithms. However, modern practice has shown success with over-parameterized models that were expected to overfit but did not. This led to the proposal of the double descent curve of performance by Belkin et al. Although it seems to describe a real, representative phenomenon, the field is lacking a fundamental theoretical understanding of what is happening, what are the consequences for model selection and when is double descent expected to occur. In this paper we develop a principled understanding of the phenomenon, and sketch answers to these important questions. Furthermore, we report real experimental results that are correctly predicted by our proposed hypothesis.
Multi-level Data Representation For Training Deep Helmholtz Machines
Oct 26, 2022A vast majority of the current research in the field of Machine Learning is done using algorithms with strong arguments pointing to their biological implausibility such as Backpropagation, deviating the field's focus from understanding its original organic inspiration to a compulsive search for optimal performance. Yet, there have been a few proposed models that respect most of the biological constraints present in the human brain and are valid candidates for mimicking some of its properties and mechanisms. In this paper, we will focus on guiding the learning of a biologically plausible generative model called the Helmholtz Machine in complex search spaces using a heuristic based on the Human Image Perception mechanism. We hypothesize that this model's learning algorithm is not fit for Deep Networks due to its Hebbian-like local update rule, rendering it incapable of taking full advantage of the compositional properties that multi-layer networks provide. We propose to overcome this problem, by providing the network's hidden layers with visual queues at different resolutions using a Multi-level Data representation. The results on several image datasets showed the model was able to not only obtain better overall quality but also a wider diversity in the generated images, corroborating our intuition that using our proposed heuristic allows the model to take more advantage of the network's depth growth. More importantly, they show the unexplored possibilities underlying brain-inspired models and techniques.
Multiple-Modality Associative Memory: a framework for Learning
Jul 18, 2022
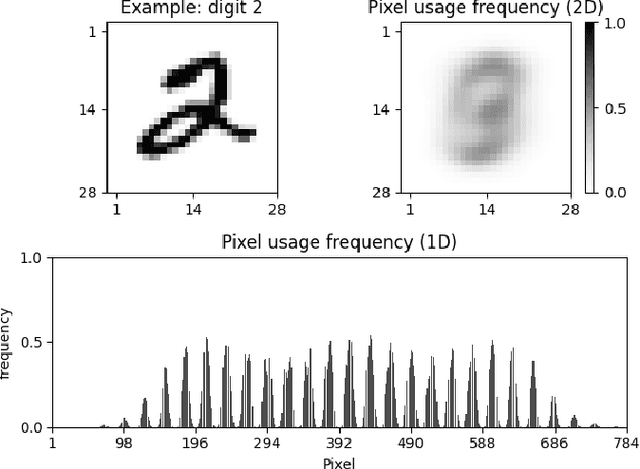
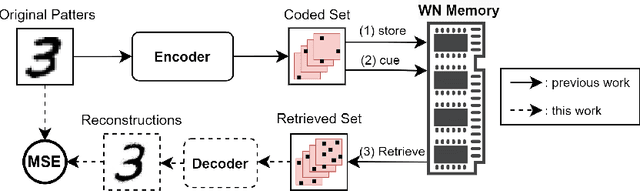
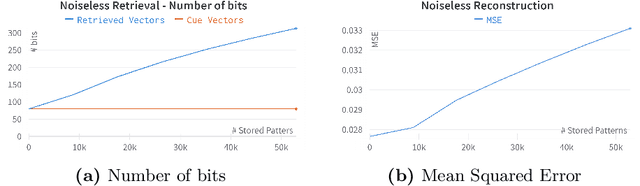
Drawing from memory the face of a friend you have not seen in years is a difficult task. However, if you happen to cross paths, you would easily recognize each other. The biological memory is equipped with an impressive compression algorithm that can store the essential, and then infer the details to match perception. Willshaw's model of Associative memory is a likely candidate for a computational model of this brain function, but its application on real-world data is hindered by the so-called Sparse Coding Problem. Due to a recently proposed sparse encoding prescription [31], which maps visual patterns into binary feature maps, we were able to analyze the behavior of the Willshaw Network (WN) on real-world data and gain key insights into the strengths of the model. To further enhance the capabilities of the WN, we propose the Multiple-Modality architecture. In this new setting, the memory stores several modalities (e.g., visual, or textual) simultaneously. After training, the model can be used to infer missing modalities when just a subset is perceived, thus serving as a flexible framework for learning tasks. We evaluated the model on the MNIST dataset. By storing both the images and labels as modalities, we were able to successfully perform pattern completion, classification, and generation with a single model.
Using brain inspired principles to unsupervisedly learn good representations for visual pattern recognition
Apr 30, 2021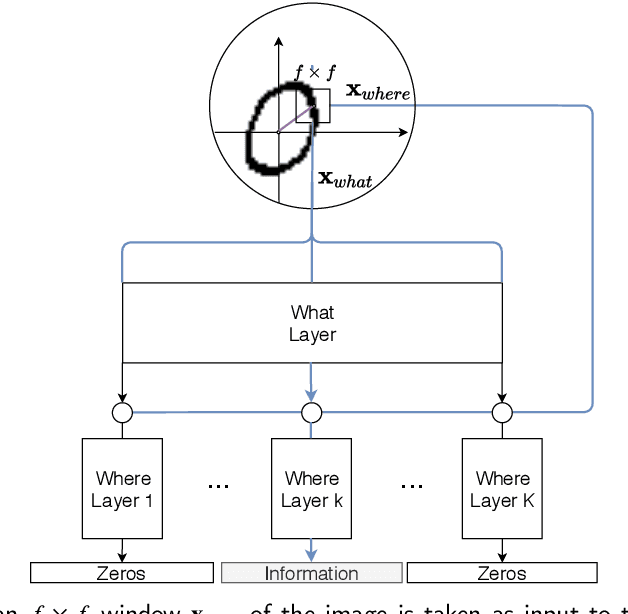
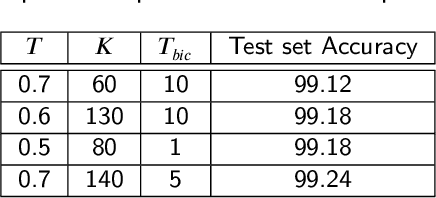
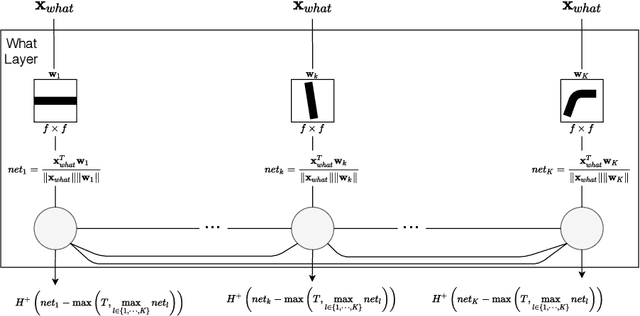
Although deep learning has solved difficult problems in visual pattern recognition, it is mostly successful in tasks where there are lots of labeled training data available. Furthermore, the global back-propagation based training rule and the amount of employed layers represents a departure from biological inspiration. The brain is able to perform most of these tasks in a very general way from limited to no labeled data. For these reasons it is still a key research question to look into computational principles in the brain that can help guide models to unsupervisedly learn good representations which can then be used to perform tasks like classification. In this work we explore some of these principles to generate such representations for the MNIST data set. We compare the obtained results with similar recent works and verify extremely competitive results.
An Investigation of Interpretability Techniques for Deep Learning in Predictive Process Analytics
Feb 21, 2020
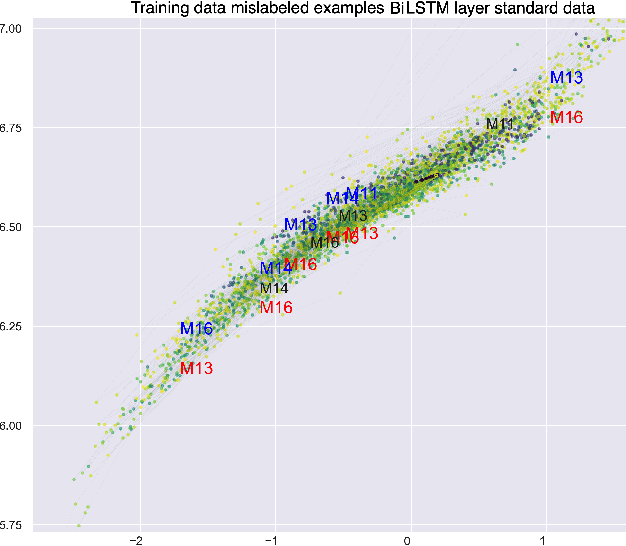
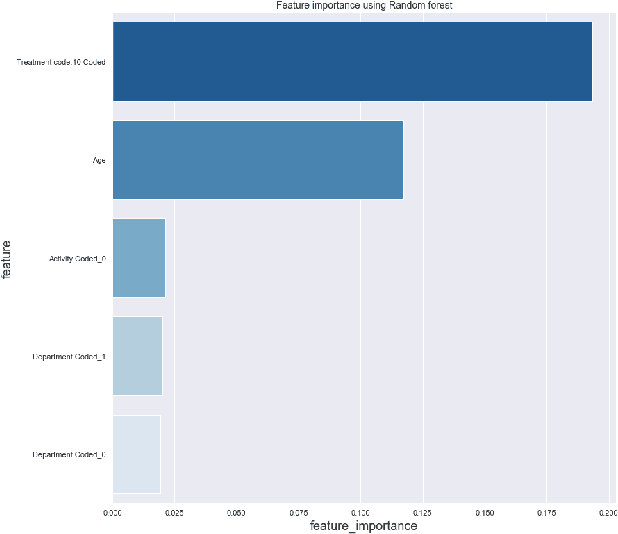

This paper explores interpretability techniques for two of the most successful learning algorithms in medical decision-making literature: deep neural networks and random forests. We applied these algorithms in a real-world medical dataset containing information about patients with cancer, where we learn models that try to predict the type of cancer of the patient, given their set of medical activity records. We explored different algorithms based on neural network architectures using long short term deep neural networks, and random forests. Since there is a growing need to provide decision-makers understandings about the logic of predictions of black boxes, we also explored different techniques that provide interpretations for these classifiers. In one of the techniques, we intercepted some hidden layers of these neural networks and used autoencoders in order to learn what is the representation of the input in the hidden layers. In another, we investigated an interpretable model locally around the random forest's prediction. Results show learning an interpretable model locally around the model's prediction leads to a higher understanding of why the algorithm is making some decision. Use of local and linear model helps identify the features used in prediction of a specific instance or data point. We see certain distinct features used for predictions that provide useful insights about the type of cancer, along with features that do not generalize well. In addition, the structured deep learning approach using autoencoders provided meaningful prediction insights, which resulted in the identification of nonlinear clusters correspondent to the patients' different types of cancer.
Towards a Quantum-Like Cognitive Architecture for Decision-Making
May 11, 2019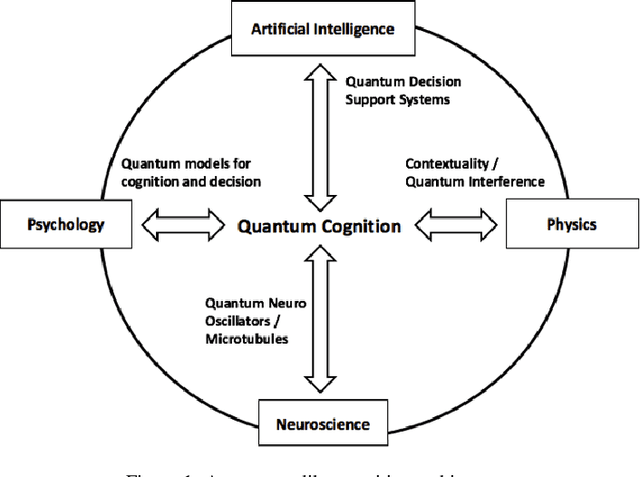
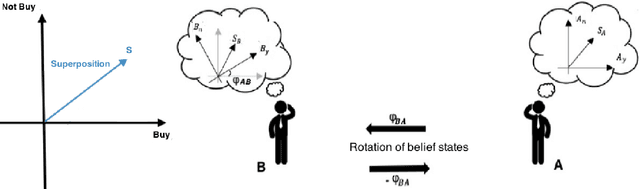
We propose an alternative and unifying framework for decision-making that, by using quantum mechanics, provides more generalised cognitive and decision models with the ability to represent more information than classical models. This framework can accommodate and predict several cognitive biases reported in Lieder & Griffiths without heavy reliance on heuristics nor on assumptions of the computational resources of the mind.
Introducing Quantum-Like Influence Diagrams for Violations of the Sure Thing Principle
Jul 16, 2018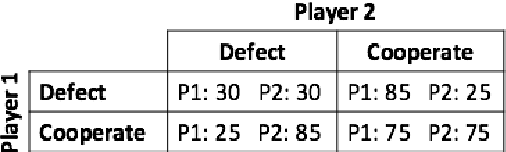
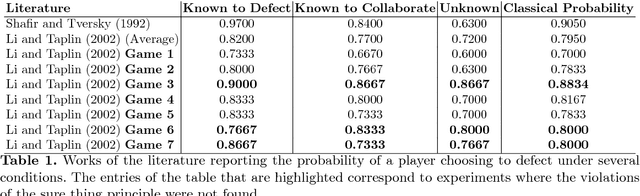
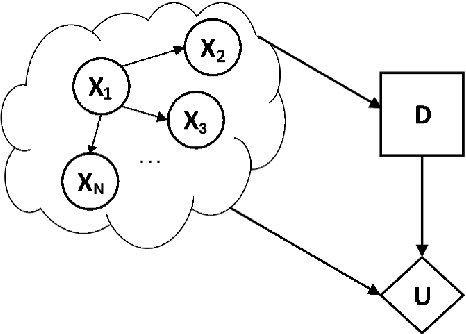

It is the focus of this work to extend and study the previously proposed quantum-like Bayesian networks to deal with decision-making scenarios by incorporating the notion of maximum expected utility in influence diagrams. The general idea is to take advantage of the quantum interference terms produced in the quantum-like Bayesian Network to influence the probabilities used to compute the expected utility of some action. This way, we are not proposing a new type of expected utility hypothesis. On the contrary, we are keeping it under its classical definition. We are only incorporating it as an extension of a probabilistic graphical model in a compact graphical representation called an influence diagram in which the utility function depends on the probabilistic influences of the quantum-like Bayesian network. Our findings suggest that the proposed quantum-like influence digram can indeed take advantage of the quantum interference effects of quantum-like Bayesian Networks to maximise the utility of a cooperative behaviour in detriment of a fully rational defect behaviour under the prisoner's dilemma game.
The Dutch's Real World Financial Institute: Introducing Quantum-Like Bayesian Networks as an Alternative Model to deal with Uncertainty
Oct 02, 2017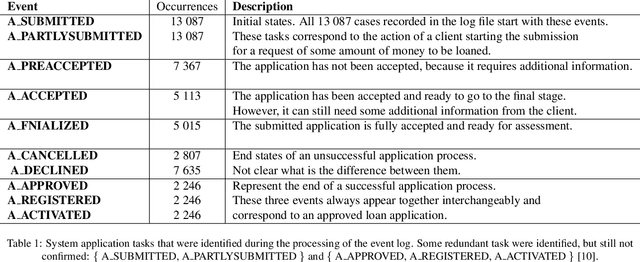
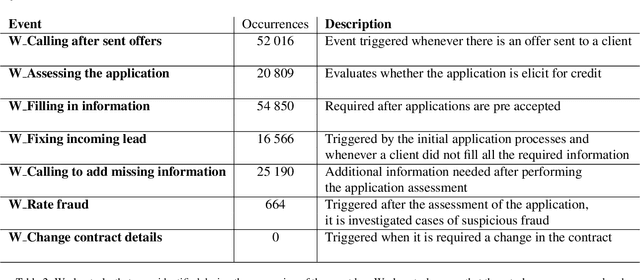
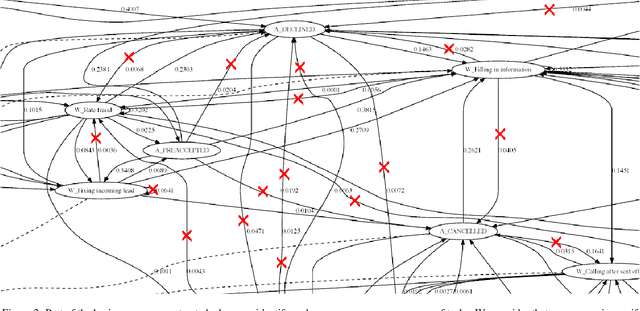
In this work, we analyse and model a real life financial loan application belonging to a sample bank in the Netherlands. The log is robust in terms of data, containing a total of 262 200 event logs, belonging to 13 087 different credit applications. The dataset is heterogeneous and consists of a mixture of computer generated automatic processes and manual human tasks. The goal is to work out a decision model, which represents the underlying tasks that make up the loan application service, and to assess potential areas of improvement of the institution's internal processes. To this end we study the impact of incomplete event logs for the extraction and analysis of business processes. It is quite common that event logs are incomplete with several amounts of missing information (for instance, workers forget to register their tasks). Absence of data is translated into a drastic decrease of precision and compromises the decision models, leading to biased and unrepresentative results. We investigate how classical probabilistic models are affected by incomplete event logs and we explore quantum-like probabilistic inferences as an alternative mathematical model to classical probability. This work represents a first step towards systematic investigation of the impact of quantum interference in a real life large scale decision scenario. The results obtained in this study indicate that, under high levels of uncertainty, the quantum-like models generate quantum interference terms, which allow an additional non-linear parameterisation of the data. Experimental results attest the efficiency of the quantum-like Bayesian networks, since the application of interference terms is able to reduce the error percentage of inferences performed over quantum-like models when compared to inferences produced by classical models.