 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Modality Associative Memory: a framework for Learning
Jul 18, 2022
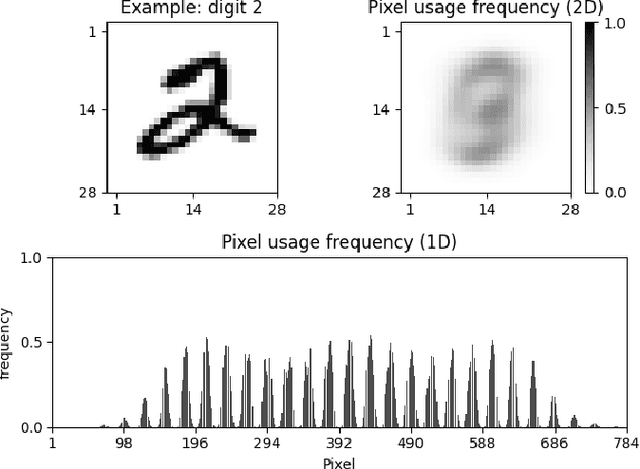
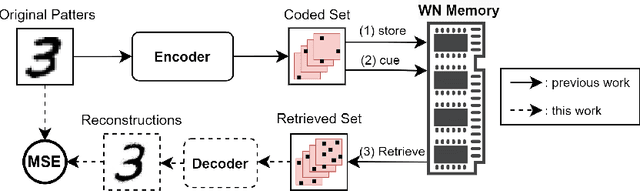
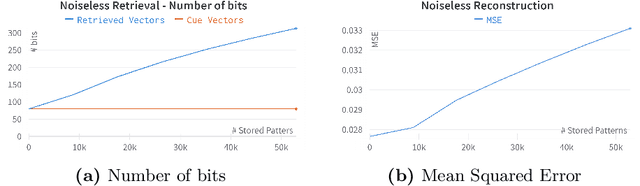
Drawing from memory the face of a friend you have not seen in years is a difficult task. However, if you happen to cross paths, you would easily recognize each other. The biological memory is equipped with an impressive compression algorithm that can store the essential, and then infer the details to match perception. Willshaw's model of Associative memory is a likely candidate for a computational model of this brain function, but its application on real-world data is hindered by the so-called Sparse Coding Problem. Due to a recently proposed sparse encoding prescription [31], which maps visual patterns into binary feature maps, we were able to analyze the behavior of the Willshaw Network (WN) on real-world data and gain key insights into the strengths of the model. To further enhance the capabilities of the WN, we propose the Multiple-Modality architecture. In this new setting, the memory stores several modalities (e.g., visual, or textual) simultaneously. After training, the model can be used to infer missing modalities when just a subset is perceived, thus serving as a flexible framework for learning tasks. We evaluated the model on the MNIST dataset. By storing both the images and labels as modalities, we were able to successfully perform pattern completion, classification, and generation with a single model.