 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe smooth output assumption, and why deep networks are better than wide ones
Nov 25, 2022When several models have similar training scores, classical model selection heuristics follow Occam's razor and advise choosing the ones with least capacity. Yet, modern practice with large neural networks has often led to situations where two networks with exactly the same number of parameters score similar on the training set, but the deeper one generalizes better to unseen examples. With this in mind, it is well accepted that deep networks are superior to shallow wide ones. However, theoretically there is no difference between the two. In fact, they are both universal approximators. In this work we propose a new unsupervised measure that predicts how well a model will generalize. We call it the output sharpness, and it is based on the fact that, in reality, boundaries between concepts are generally unsharp. We test this new measure on several neural network settings, and architectures, and show how generally strong the correlation is between our metric, and test set performance. Having established this measure, we give a mathematical probabilistic argument that predicts network depth to be correlated with our proposed measure. After verifying this in real data, we are able to formulate the key argument of the work: output sharpness hampers generalization; deep networks have an in built bias against it; therefore, deep networks beat wide ones. All in all the work not only provides a helpful predictor of overfitting that can be used in practice for model selection (or even regularization), but also provides a much needed theoretical grounding for the success of modern deep neural networks.
Understanding the double descent curve in Machine Learning
Nov 18, 2022The theory of bias-variance used to serve as a guide for model selection when applying Machine Learning algorithms. However, modern practice has shown success with over-parameterized models that were expected to overfit but did not. This led to the proposal of the double descent curve of performance by Belkin et al. Although it seems to describe a real, representative phenomenon, the field is lacking a fundamental theoretical understanding of what is happening, what are the consequences for model selection and when is double descent expected to occur. In this paper we develop a principled understanding of the phenomenon, and sketch answers to these important questions. Furthermore, we report real experimental results that are correctly predicted by our proposed hypothesis.
Multi-level Data Representation For Training Deep Helmholtz Machines
Oct 26, 2022A vast majority of the current research in the field of Machine Learning is done using algorithms with strong arguments pointing to their biological implausibility such as Backpropagation, deviating the field's focus from understanding its original organic inspiration to a compulsive search for optimal performance. Yet, there have been a few proposed models that respect most of the biological constraints present in the human brain and are valid candidates for mimicking some of its properties and mechanisms. In this paper, we will focus on guiding the learning of a biologically plausible generative model called the Helmholtz Machine in complex search spaces using a heuristic based on the Human Image Perception mechanism. We hypothesize that this model's learning algorithm is not fit for Deep Networks due to its Hebbian-like local update rule, rendering it incapable of taking full advantage of the compositional properties that multi-layer networks provide. We propose to overcome this problem, by providing the network's hidden layers with visual queues at different resolutions using a Multi-level Data representation. The results on several image datasets showed the model was able to not only obtain better overall quality but also a wider diversity in the generated images, corroborating our intuition that using our proposed heuristic allows the model to take more advantage of the network's depth growth. More importantly, they show the unexplored possibilities underlying brain-inspired models and techniques.
Multiple-Modality Associative Memory: a framework for Learning
Jul 18, 2022
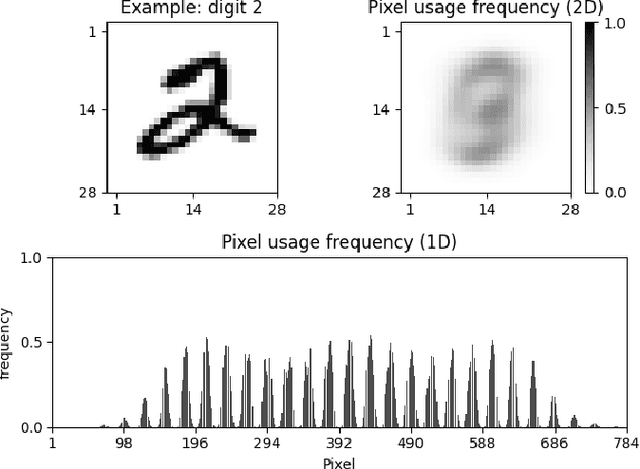
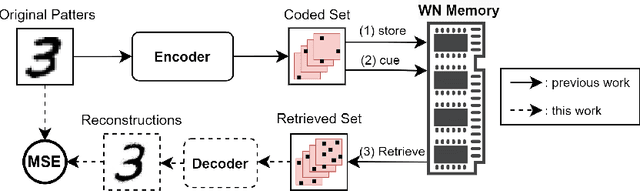
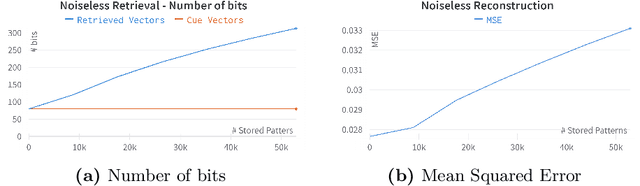
Drawing from memory the face of a friend you have not seen in years is a difficult task. However, if you happen to cross paths, you would easily recognize each other. The biological memory is equipped with an impressive compression algorithm that can store the essential, and then infer the details to match perception. Willshaw's model of Associative memory is a likely candidate for a computational model of this brain function, but its application on real-world data is hindered by the so-called Sparse Coding Problem. Due to a recently proposed sparse encoding prescription [31], which maps visual patterns into binary feature maps, we were able to analyze the behavior of the Willshaw Network (WN) on real-world data and gain key insights into the strengths of the model. To further enhance the capabilities of the WN, we propose the Multiple-Modality architecture. In this new setting, the memory stores several modalities (e.g., visual, or textual) simultaneously. After training, the model can be used to infer missing modalities when just a subset is perceived, thus serving as a flexible framework for learning tasks. We evaluated the model on the MNIST dataset. By storing both the images and labels as modalities, we were able to successfully perform pattern completion, classification, and generation with a single model.
Using brain inspired principles to unsupervisedly learn good representations for visual pattern recognition
Apr 30, 2021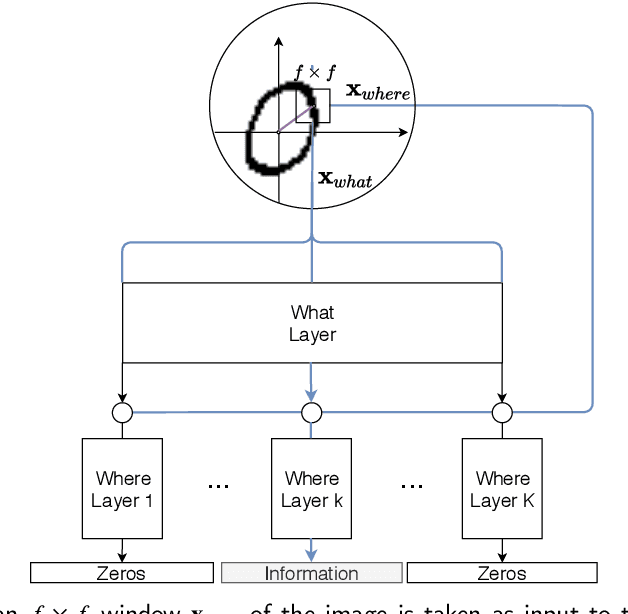
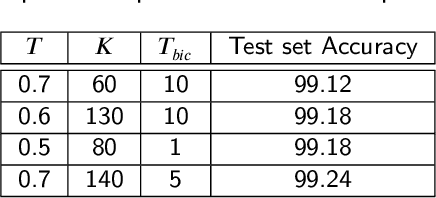
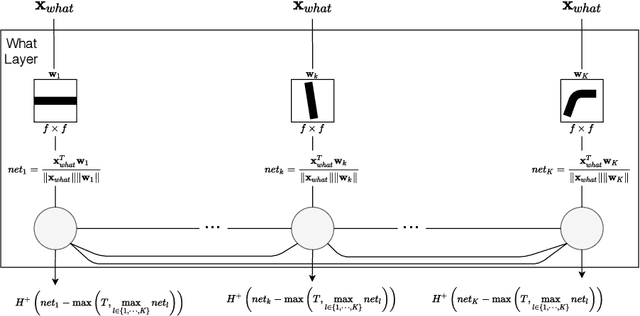
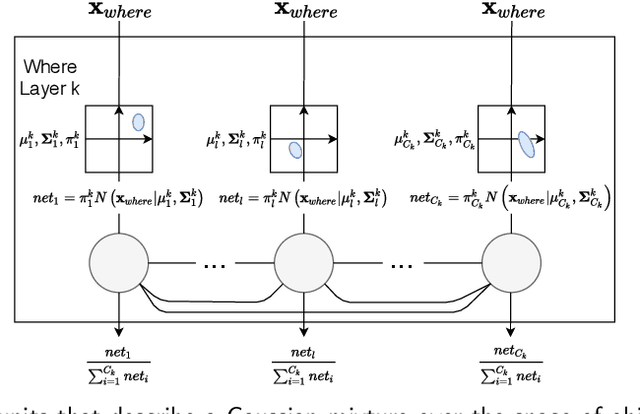
Although deep learning has solved difficult problems in visual pattern recognition, it is mostly successful in tasks where there are lots of labeled training data available. Furthermore, the global back-propagation based training rule and the amount of employed layers represents a departure from biological inspiration. The brain is able to perform most of these tasks in a very general way from limited to no labeled data. For these reasons it is still a key research question to look into computational principles in the brain that can help guide models to unsupervisedly learn good representations which can then be used to perform tasks like classification. In this work we explore some of these principles to generate such representations for the MNIST data set. We compare the obtained results with similar recent works and verify extremely competitive results.