 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023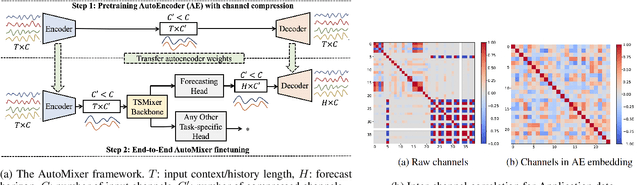
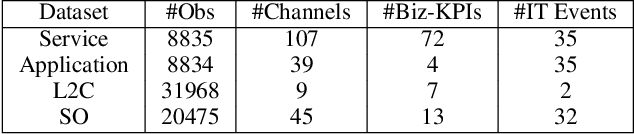
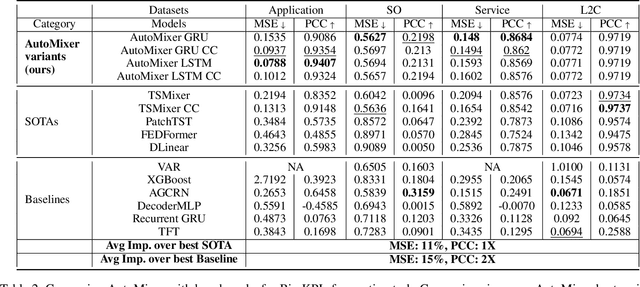
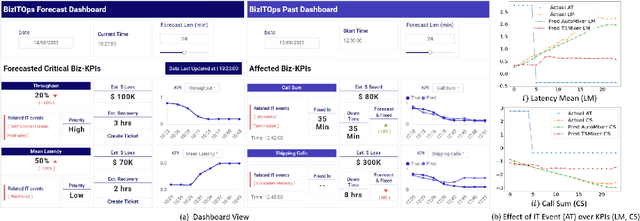
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
Demarcating Endogenous and Exogenous Opinion Dynamics: An Experimental Design Approach
Feb 11, 2021
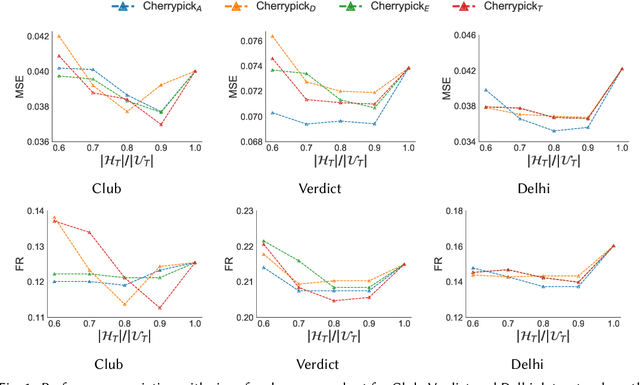
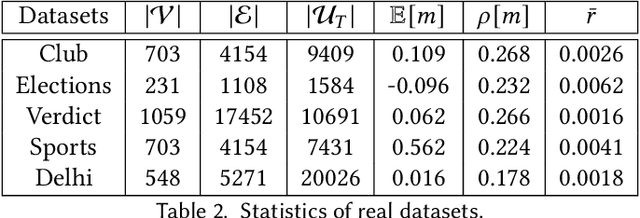

The networked opinion diffusion in online social networks (OSN) is often governed by the two genres of opinions - endogenous opinions that are driven by the influence of social contacts among users, and exogenous opinions which are formed by external effects like news, feeds etc. Accurate demarcation of endogenous and exogenous messages offers an important cue to opinion modeling, thereby enhancing its predictive performance. In this paper, we design a suite of unsupervised classification methods based on experimental design approaches, in which, we aim to select the subsets of events which minimize different measures of mean estimation error. In more detail, we first show that these subset selection tasks are NP-Hard. Then we show that the associated objective functions are weakly submodular, which allows us to cast efficient approximation algorithms with guarantees. Finally, we validate the efficacy of our proposal on various real-world datasets crawled from Twitter as well as diverse synthetic datasets. Our experiments range from validating prediction performance on unsanitized and sanitized events to checking the effect of selecting optimal subsets of various sizes. Through various experiments, we have found that our method offers a significant improvement in accuracy in terms of opinion forecasting, against several competitors.
* 25 Pages, Accepted in ACM TKDD, 2021