 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
DePrompt: Desensitization and Evaluation of Personal Identifiable Information in Large Language Model Prompts
Aug 16, 2024Prompt serves as a crucial link in interacting with large language models (LLMs), widely impacting the accuracy and interpretability of model outputs. However, acquiring accurate and high-quality responses necessitates precise prompts, which inevitably pose significant risks of personal identifiable information (PII) leakage. Therefore, this paper proposes DePrompt, a desensitization protection and effectiveness evaluation framework for prompt, enabling users to safely and transparently utilize LLMs. Specifically, by leveraging large model fine-tuning techniques as the underlying privacy protection method, we integrate contextual attributes to define privacy types, achieving high-precision PII entity identification. Additionally, through the analysis of key features in prompt desensitization scenarios, we devise adversarial generative desensitization methods that retain important semantic content while disrupting the link between identifiers and privacy attributes. Furthermore, we present utility evaluation metrics for prompt to better gauge and balance privacy and usability. Our framework is adaptable to prompts and can be extended to text usability-dependent scenarios. Through comparison with benchmarks and other model methods, experimental evaluations demonstrate that our desensitized prompt exhibit superior privacy protection utility and model inference results.
A Bi-Level Framework for Learning to Solve Combinatorial Optimization on Graphs
Jun 09, 2021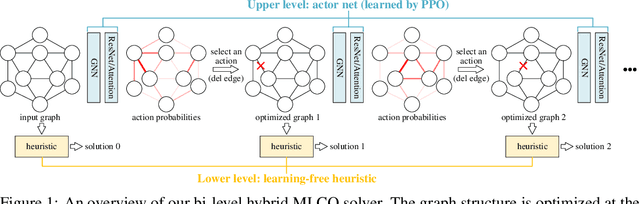
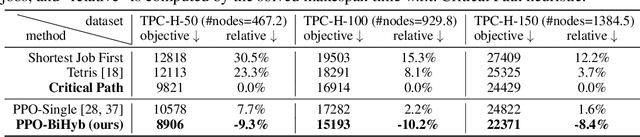
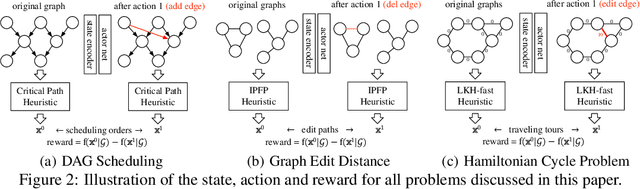
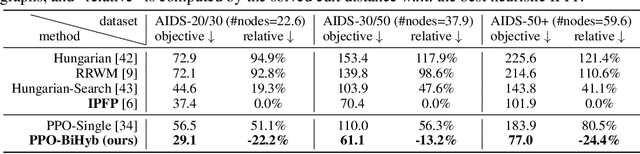
Combinatorial Optimization (CO) has been a long-standing challenging research topic featured by its NP-hard nature. Traditionally such problems are approximately solved with heuristic algorithms which are usually fast but may sacrifice the solution quality. Currently, machine learning for combinatorial optimization (MLCO) has become a trending research topic, but most existing MLCO methods treat CO as a single-level optimization by directly learning the end-to-end solutions, which are hard to scale up and mostly limited by the capacity of ML models given the high complexity of CO. In this paper, we propose a hybrid approach to combine the best of the two worlds, in which a bi-level framework is developed with an upper-level learning method to optimize the graph (e.g. add, delete or modify edges in a graph), fused with a lower-level heuristic algorithm solving on the optimized graph. Such a bi-level approach simplifies the learning on the original hard CO and can effectively mitigate the demand for model capacity. The experiments and results on several popular CO problems like Directed Acyclic Graph scheduling, Graph Edit Distance and Hamiltonian Cycle Problem show its effectiveness over manually designed heuristics and single-level learning methods.
Learning to Schedule DAG Tasks
Mar 05, 2021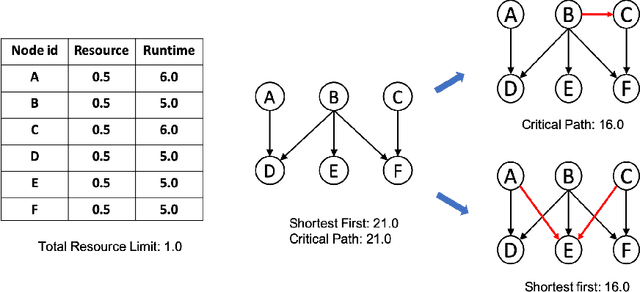

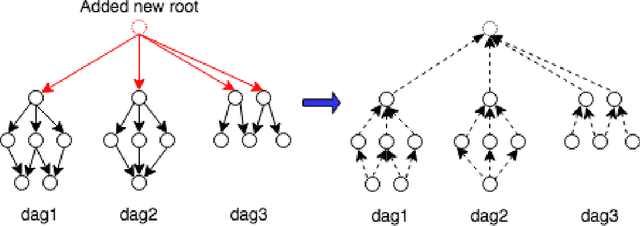
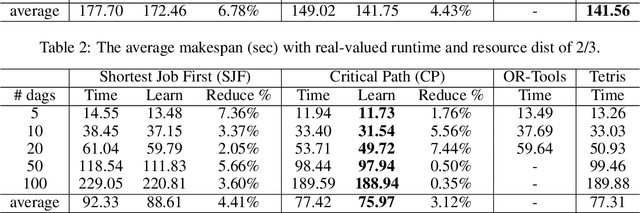
Scheduling computational tasks represented by directed acyclic graphs (DAGs) is challenging because of its complexity. Conventional scheduling algorithms rely heavily on simple heuristics such as shortest job first (SJF) and critical path (CP), and are often lacking in scheduling quality. In this paper, we present a novel learning-based approach to scheduling DAG tasks. The algorithm employs a reinforcement learning agent to iteratively add directed edges to the DAG, one at a time, to enforce ordering (i.e., priorities of execution and resource allocation) of "tricky" job nodes. By doing so, the original DAG scheduling problem is dramatically reduced to a much simpler proxy problem, on which heuristic scheduling algorithms such as SJF and CP can be efficiently improved. Our approach can be easily applied to any existing heuristic scheduling algorithms. On the benchmark dataset of TPC-H, we show that our learning based approach can significantly improve over popular heuristic algorithms and consistently achieves the best performance among several methods under a variety of settings.