 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADCrowner: Margin Aware Dental Crown Design with Template Deformation and Refinement
Mar 05, 2026Dental crown restoration is one of the most common treatment modalities for tooth defect, where personalized dental crown design is critical. While computer-aided design (CAD) systems have notably enhanced the efficiency of dental crown design, extensive manual adjustments are still required in the clinic workflow. Recent studies have explored the application of learning-based methods for the automated generation of restorative dental crowns. Nevertheless, these approaches were challenged by inadequate spatial resolution, noisy outputs, and overextension of surface reconstruction. To address these limitations, we propose \totalframework, a margin-aware mesh generation framework comprising CrownDeformR and CrownSegger. Inspired by the clinic manual workflow of dental crown design, we designed CrownDeformR to deform an initial template to the target crown based on anatomical context, which is extracted by a multi-scale intraoral scan encoder. Additionally, we introduced \marginseg, a novel margin segmentation network, to extract the cervical margin of the target tooth. The performance of CrownDeformR improved with the cervical margin as an extra constraint. And it was also utilized as the boundary condition for the tailored postprocessing method, which removed the overextended area of the reconstructed surface. We constructed a large-scale intraoral scan dataset and performed extensive experiments. The proposed method significantly outperformed existing approaches in both geometric accuracy and clinical feasibility.
ArchPilot: A Proxy-Guided Multi-Agent Approach for Machine Learning Engineering
Nov 06, 2025Recent LLM-based agents have demonstrated strong capabilities in automated ML engineering. However, they heavily rely on repeated full training runs to evaluate candidate solutions, resulting in significant computational overhead, limited scalability to large search spaces, and slow iteration cycles. To address these challenges, we introduce ArchPilot, a multi-agent system that integrates architecture generation, proxy-based evaluation, and adaptive search into a unified framework. ArchPilot consists of three specialized agents: an orchestration agent that coordinates the search process using a Monte Carlo Tree Search (MCTS)-inspired novel algorithm with a restart mechanism and manages memory of previous candidates; a generation agent that iteratively generates, improves, and debugs candidate architectures; and an evaluation agent that executes proxy training runs, generates and optimizes proxy functions, and aggregates the proxy scores into a fidelity-aware performance metric. This multi-agent collaboration allows ArchPilot to prioritize high-potential candidates with minimal reliance on expensive full training runs, facilitating efficient ML engineering under limited budgets. Experiments on MLE-Bench demonstrate that ArchPilot outperforms SOTA baselines such as AIDE and ML-Master, validating the effectiveness of our multi-agent system.
GeoDecoder: Empowering Multimodal Map Understanding
Jan 26, 2024


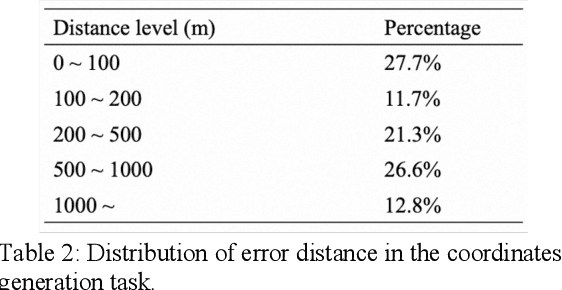
This paper presents GeoDecoder, a dedicated multimodal model designed for processing geospatial information in maps. Built on the BeitGPT architecture, GeoDecoder incorporates specialized expert modules for image and text processing. On the image side, GeoDecoder utilizes GaoDe Amap as the underlying base map, which inherently encompasses essential details about road and building shapes, relative positions, and other attributes. Through the utilization of rendering techniques, the model seamlessly integrates external data and features such as symbol markers, drive trajectories, heatmaps, and user-defined markers, eliminating the need for extra feature engineering. The text module of GeoDecoder accepts various context texts and question prompts, generating text outputs in the style of GPT. Furthermore, the GPT-based model allows for the training and execution of multiple tasks within the same model in an end-to-end manner. To enhance map cognition and enable GeoDecoder to acquire knowledge about the distribution of geographic entities in Beijing, we devised eight fundamental geospatial tasks and conducted pretraining of the model using large-scale text-image samples. Subsequently, rapid fine-tuning was performed on three downstream tasks, resulting in significant performance improvements. The GeoDecoder model demonstrates a comprehensive understanding of map elements and their associated operations, enabling efficient and high-quality application of diverse geospatial tasks in different business scenarios.
Learning to Rank Normalized Entropy Curves with Differentiable Window Transformation
Jan 25, 2023



Recent automated machine learning systems often use learning curves ranking models to inform decisions about when to stop unpromising trials and identify better model configurations. In this paper, we present a novel learning curve ranking model specifically tailored for ranking normalized entropy (NE) learning curves, which are commonly used in online advertising and recommendation systems. Our proposed model, self-Adaptive Curve Transformation augmented Relative curve Ranking (ACTR2), features an adaptive curve transformation layer that transforms raw lifetime NE curves into composite window NE curves with the window sizes adaptively optimized based on both the position on the learning curve and the curve's dynamics. We also introduce a novel differentiable indexing method for the proposed adaptive curve transformation, which allows gradients with respect to the discrete indices to flow freely through the curve transformation layer, enabling the learned window sizes to be updated flexibly during training. Additionally, we propose a pairwise curve ranking architecture that directly models the difference between the two learning curves and is better at capturing subtle changes in relative performance that may not be evident when modeling each curve individually as the existing approaches did. Our extensive experiments on a real-world NE curve dataset demonstrate the effectiveness of each key component of ACTR2 and its improved performance over the state-of-the-art.
A framework for massive scale personalized promotion
Aug 27, 2021

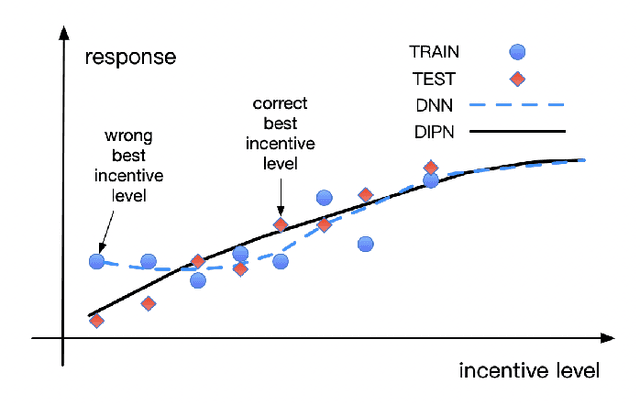
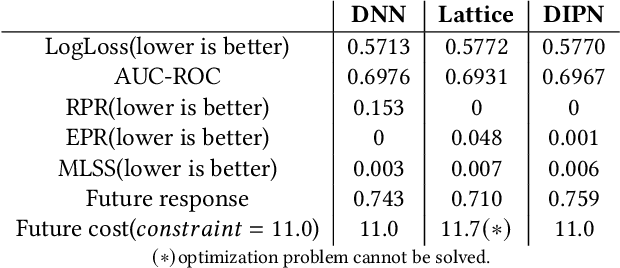
Technology companies building consumer-facing platforms may have access to massive-scale user population. In recent years, promotion with quantifiable incentive has become a popular approach for increasing active users on such platforms. On one hand, increased user activities can introduce network effect, bring in advertisement audience, and produce other benefits. On the other hand, massive-scale promotion causes massive cost. Therefore making promotion campaigns efficient in terms of return-on-investment (ROI) is of great interest to many companies. This paper proposes a practical two-stage framework that can optimize the ROI of various massive-scale promotion campaigns. In the first stage, users' personal promotion-response curves are modeled by machine learning techniques. In the second stage, business objectives and resource constraints are formulated into an optimization problem, the decision variables of which are how much incentive to give to each user. In order to do effective optimization in the second stage, counterfactual prediction and noise-reduction are essential for the first stage. We leverage existing counterfactual prediction techniques to correct treatment bias in data. We also introduce a novel deep neural network (DNN) architecture, the deep-isotonic-promotion-network (DIPN), to reduce noise in the promotion response curves. The DIPN architecture incorporates our prior knowledge of response curve shape, by enforcing isotonicity and smoothness. It out-performed regular DNN and other state-of-the-art shape-constrained models in our experiments.
A Bi-Level Framework for Learning to Solve Combinatorial Optimization on Graphs
Jun 09, 2021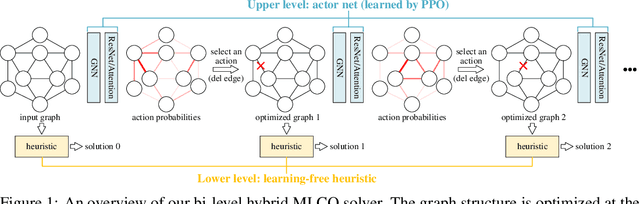
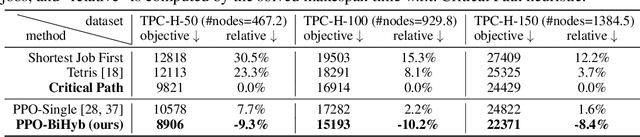
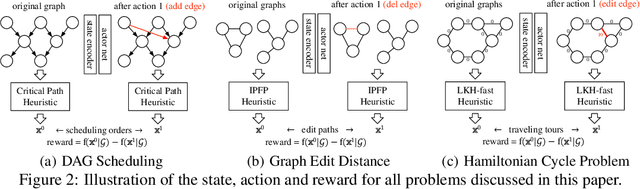
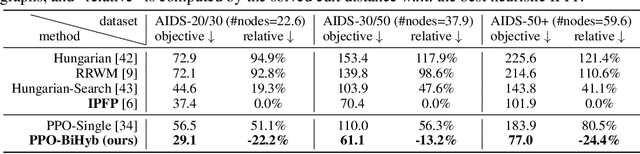
Combinatorial Optimization (CO) has been a long-standing challenging research topic featured by its NP-hard nature. Traditionally such problems are approximately solved with heuristic algorithms which are usually fast but may sacrifice the solution quality. Currently, machine learning for combinatorial optimization (MLCO) has become a trending research topic, but most existing MLCO methods treat CO as a single-level optimization by directly learning the end-to-end solutions, which are hard to scale up and mostly limited by the capacity of ML models given the high complexity of CO. In this paper, we propose a hybrid approach to combine the best of the two worlds, in which a bi-level framework is developed with an upper-level learning method to optimize the graph (e.g. add, delete or modify edges in a graph), fused with a lower-level heuristic algorithm solving on the optimized graph. Such a bi-level approach simplifies the learning on the original hard CO and can effectively mitigate the demand for model capacity. The experiments and results on several popular CO problems like Directed Acyclic Graph scheduling, Graph Edit Distance and Hamiltonian Cycle Problem show its effectiveness over manually designed heuristics and single-level learning methods.
Learning to Schedule DAG Tasks
Mar 05, 2021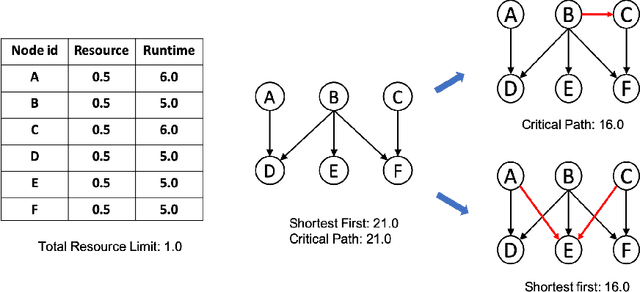

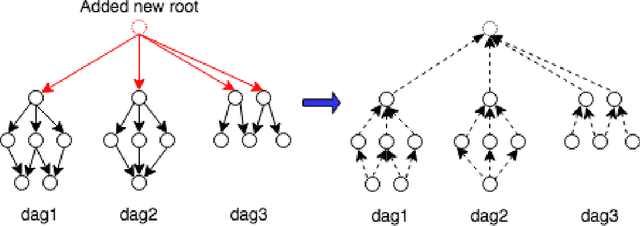
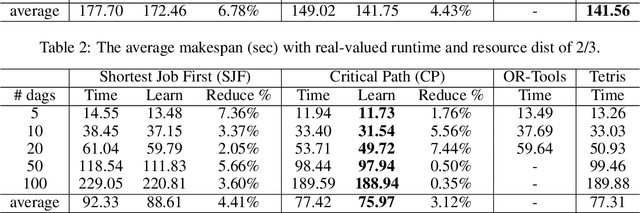
Scheduling computational tasks represented by directed acyclic graphs (DAGs) is challenging because of its complexity. Conventional scheduling algorithms rely heavily on simple heuristics such as shortest job first (SJF) and critical path (CP), and are often lacking in scheduling quality. In this paper, we present a novel learning-based approach to scheduling DAG tasks. The algorithm employs a reinforcement learning agent to iteratively add directed edges to the DAG, one at a time, to enforce ordering (i.e., priorities of execution and resource allocation) of "tricky" job nodes. By doing so, the original DAG scheduling problem is dramatically reduced to a much simpler proxy problem, on which heuristic scheduling algorithms such as SJF and CP can be efficiently improved. Our approach can be easily applied to any existing heuristic scheduling algorithms. On the benchmark dataset of TPC-H, we show that our learning based approach can significantly improve over popular heuristic algorithms and consistently achieves the best performance among several methods under a variety of settings.
Non-local Channel Aggregation Network for Single Image Rain Removal
Mar 03, 2021



Rain streaks showing in images or videos would severely degrade the performance of computer vision applications. Thus, it is of vital importance to remove rain streaks and facilitate our vision systems. While recent convolutinal neural network based methods have shown promising results in single image rain removal (SIRR), they fail to effectively capture long-range location dependencies or aggregate convolutional channel information simultaneously. However, as SIRR is a highly illposed problem, these spatial and channel information are very important clues to solve SIRR. First, spatial information could help our model to understand the image context by gathering long-range dependency location information hidden in the image. Second, aggregating channels could help our model to concentrate on channels more related to image background instead of rain streaks. In this paper, we propose a non-local channel aggregation network (NCANet) to address the SIRR problem. NCANet models 2D rainy images as sequences of vectors in three directions, namely vertical direction, transverse direction and channel direction. Recurrently aggregating information from all three directions enables our model to capture the long-range dependencies in both channels and spaitials locations. Extensive experiments on both heavy and light rain image data sets demonstrate the effectiveness of the proposed NCANet model.
Language guided machine action
Nov 23, 2020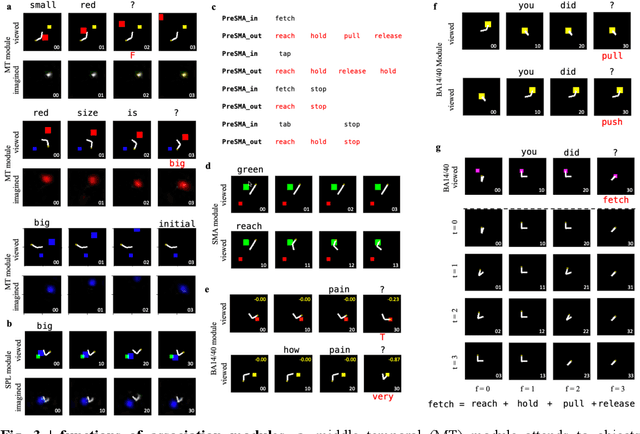
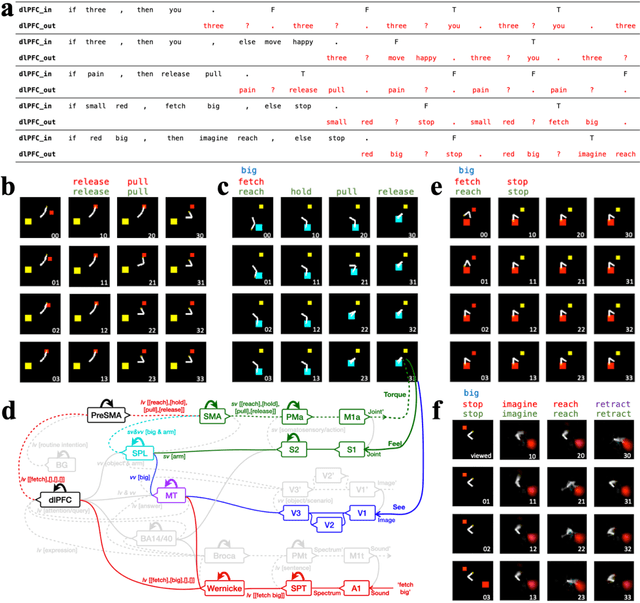
Here we build a hierarchical modular network called Language guided machine action (LGMA), whose modules process information stream mimicking human cortical network that allows to achieve multiple general tasks such as language guided action, intention decomposition and mental simulation before action execution etc. LGMA contains 3 main systems: (1) primary sensory system that multimodal sensory information of vision, language and sensorimotor. (2) association system involves and Broca modules to comprehend and synthesize language, BA14/40 module to translate between sensorimotor and language, midTemporal module to convert between language and vision, and superior parietal lobe to integrate attended visual object and arm state into cognitive map for future spatial actions. Pre-supplementary motor area (pre-SMA) can converts high level intention into sequential atomic actions, while SMA can integrate these atomic actions, current arm and attended object state into sensorimotor vector to apply corresponding torques on arm via pre-motor and primary motor of arm to achieve the intention. The high-level executive system contains PFC that does explicit inference and guide voluntary action based on language, while BG is the habitual action control center.
Visualizing and Understanding Vision System
Jun 11, 2020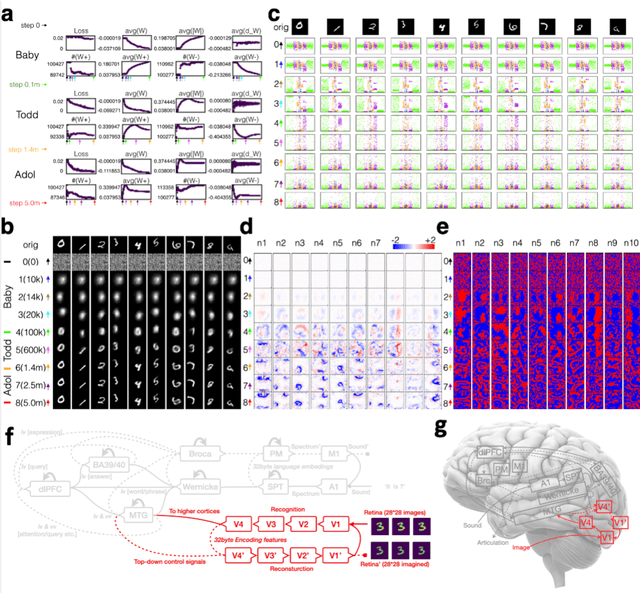

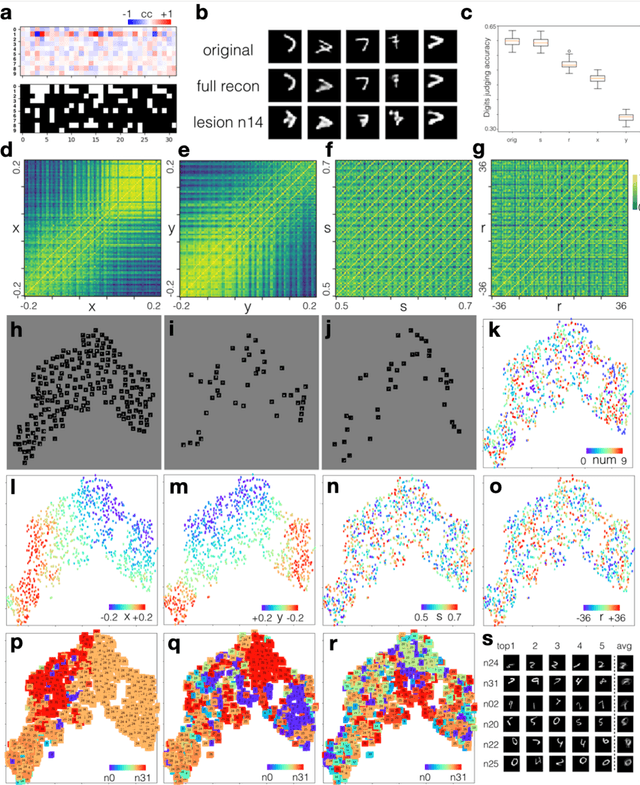
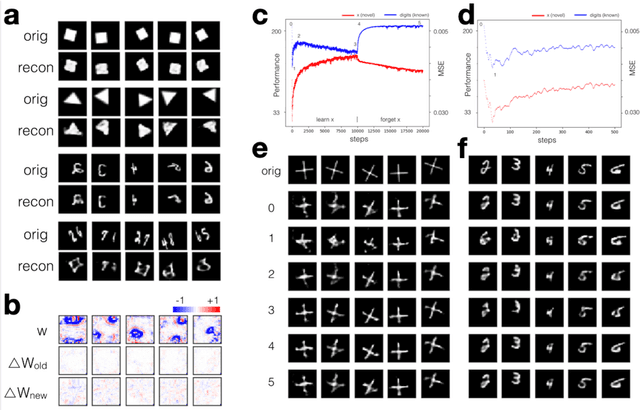
How the human vision system addresses the object identity-preserving recognition problem is largely unknown. Here, we use a vision recognition-reconstruction network (RRN) to investigate the development, recognition, learning and forgetting mechanisms, and achieve similar characteristics to electrophysiological measurements in monkeys. First, in network development study, the RRN also experiences critical developmental stages characterized by specificities in neuron types, synapse and activation patterns, and visual task performance from the early stage of coarse salience map recognition to mature stage of fine structure recognition. In digit recognition study, we witness that the RRN could maintain object invariance representation under various viewing conditions by coordinated adjustment of responses of population neurons. And such concerted population responses contained untangled object identity and properties information that could be accurately extracted via high-level cortices or even a simple weighted summation decoder. In the learning and forgetting study, novel structure recognition is implemented by adjusting entire synapses in low magnitude while pattern specificities of original synaptic connectivity are preserved, which guaranteed a learning process without disrupting the existing functionalities. This work benefits the understanding of the human visual processing mechanism and the development of human-like machine intelligence.