 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning (Re-)Starting Solutions for Vehicle Routing Problems
Aug 08, 2020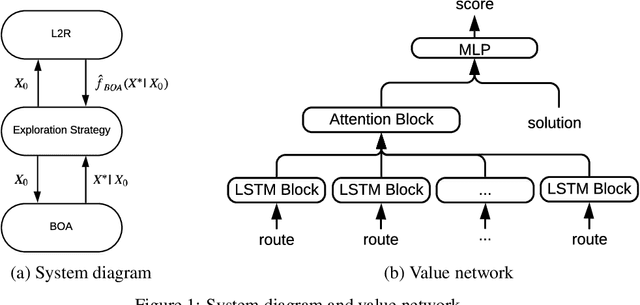

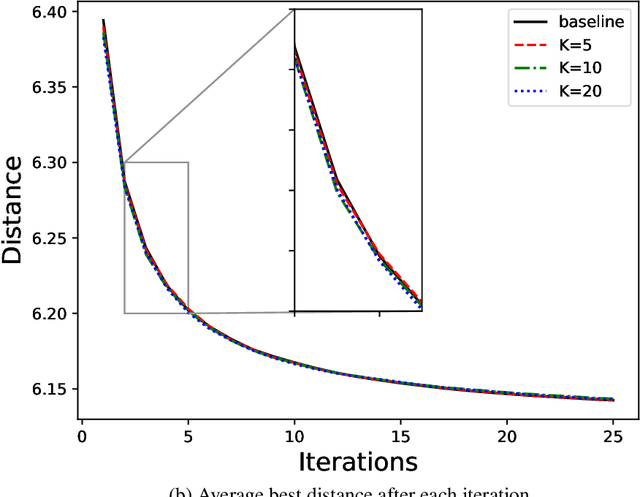
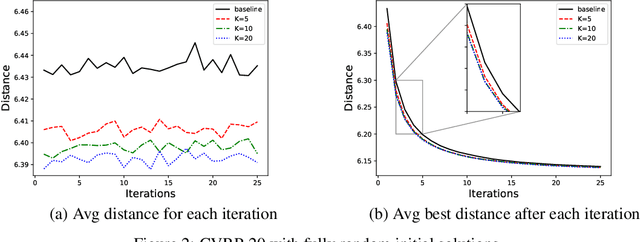
A key challenge in solving a combinatorial optimization problem is how to guide the agent (i.e., solver) to efficiently explore the enormous search space. Conventional approaches often rely on enumeration (e.g., exhaustive, random, or tabu search) or have to restrict the exploration to rather limited regions (e.g., a single path as in iterative algorithms). In this paper, we show it is possible to use machine learning to speedup the exploration. In particular, a value network is trained to evaluate solution candidates, which provides a useful structure (i.e., an approximate value surface) over the search space; this value network is then used to screen solutions to help a black-box optimization agent to initialize or restart so as to navigate through the search space towards desirable solutions. Experiments demonstrate that the proposed ``Learn to Restart'' algorithm achieves promising results in solving Capacitated Vehicle Routing Problems (CVRPs).
Solving Billion-Scale Knapsack Problems
Feb 02, 2020



Knapsack problems (KPs) are common in industry, but solving KPs is known to be NP-hard and has been tractable only at a relatively small scale. This paper examines KPs in a slightly generalized form and shows that they can be solved nearly optimally at scale via distributed algorithms. The proposed approach can be implemented fairly easily with off-the-shelf distributed computing frameworks (e.g. MPI, Hadoop, Spark). As an example, our implementation leads to one of the most efficient KP solvers known to date -- capable to solve KPs at an unprecedented scale (e.g., KPs with 1 billion decision variables and 1 billion constraints can be solved within 1 hour). The system has been deployed to production and called on a daily basis, yielding significant business impacts at Ant Financial.
On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
Dec 18, 2017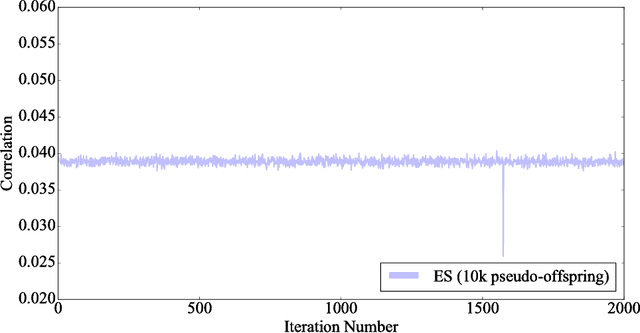

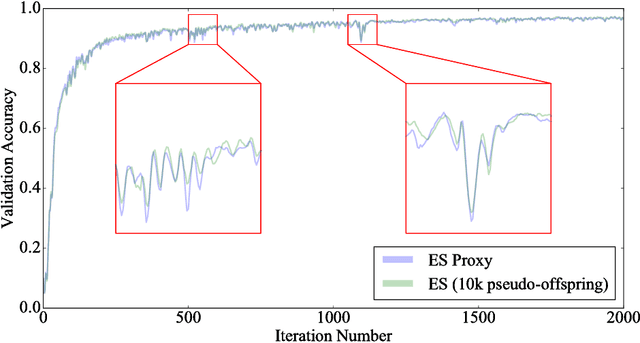
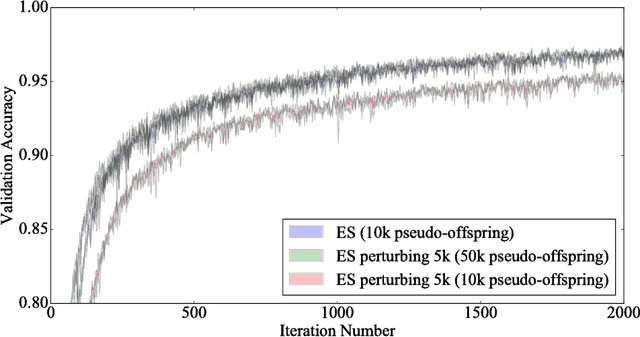
Because stochastic gradient descent (SGD) has shown promise optimizing neural networks with millions of parameters and few if any alternatives are known to exist, it has moved to the heart of leading approaches to reinforcement learning (RL). For that reason, the recent result from OpenAI showing that a particular kind of evolution strategy (ES) can rival the performance of SGD-based deep RL methods with large neural networks provoked surprise. This result is difficult to interpret in part because of the lingering ambiguity on how ES actually relates to SGD. The aim of this paper is to significantly reduce this ambiguity through a series of MNIST-based experiments designed to uncover their relationship. As a simple supervised problem without domain noise (unlike in most RL), MNIST makes it possible (1) to measure the correlation between gradients computed by ES and SGD and (2) then to develop an SGD-based proxy that accurately predicts the performance of different ES population sizes. These innovations give a new level of insight into the real capabilities of ES, and lead also to some unconventional means for applying ES to supervised problems that shed further light on its differences from SGD. Incorporating these lessons, the paper concludes by demonstrating that ES can achieve 99% accuracy on MNIST, a number higher than any previously published result for any evolutionary method. While not by any means suggesting that ES should substitute for SGD in supervised learning, the suite of experiments herein enables more informed decisions on the application of ES within RL and other paradigms.