 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
Paper and Code
Dec 18, 2017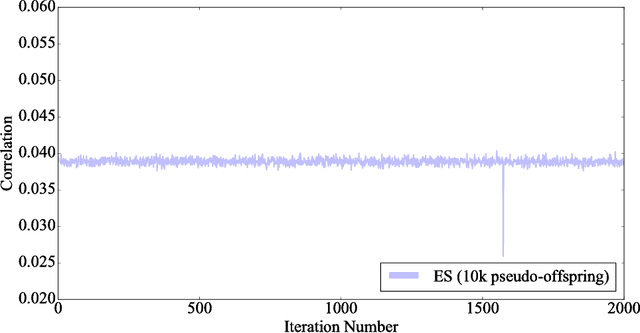

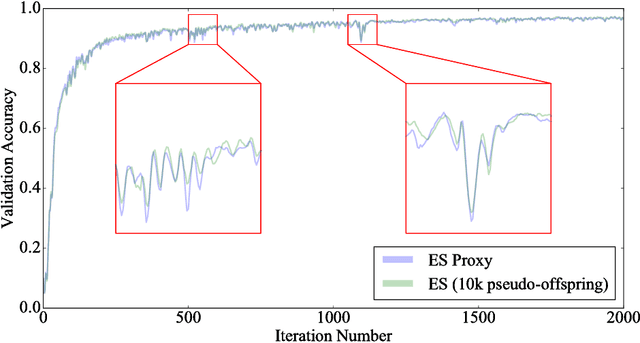
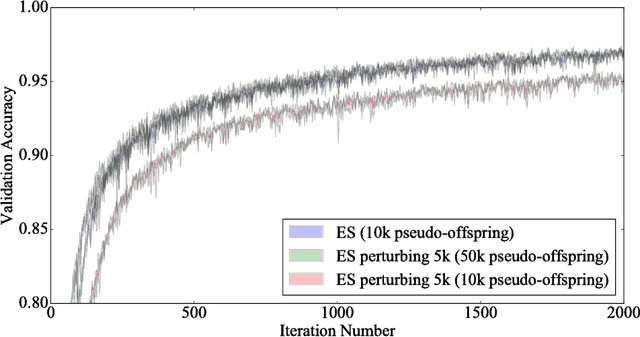
Because stochastic gradient descent (SGD) has shown promise optimizing neural networks with millions of parameters and few if any alternatives are known to exist, it has moved to the heart of leading approaches to reinforcement learning (RL). For that reason, the recent result from OpenAI showing that a particular kind of evolution strategy (ES) can rival the performance of SGD-based deep RL methods with large neural networks provoked surprise. This result is difficult to interpret in part because of the lingering ambiguity on how ES actually relates to SGD. The aim of this paper is to significantly reduce this ambiguity through a series of MNIST-based experiments designed to uncover their relationship. As a simple supervised problem without domain noise (unlike in most RL), MNIST makes it possible (1) to measure the correlation between gradients computed by ES and SGD and (2) then to develop an SGD-based proxy that accurately predicts the performance of different ES population sizes. These innovations give a new level of insight into the real capabilities of ES, and lead also to some unconventional means for applying ES to supervised problems that shed further light on its differences from SGD. Incorporating these lessons, the paper concludes by demonstrating that ES can achieve 99% accuracy on MNIST, a number higher than any previously published result for any evolutionary method. While not by any means suggesting that ES should substitute for SGD in supervised learning, the suite of experiments herein enables more informed decisions on the application of ES within RL and other paradigms.