 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Multi-Model Fusion for Target-Oriented Adaptive Sampling in Materials Design
Feb 03, 2026Target-oriented discovery under limited evaluation budgets requires making reliable progress in high-dimensional, heterogeneous design spaces where each new measurement is costly, whether experimental or high-fidelity simulation. We present an information-theoretic framework for target-oriented adaptive sampling that reframes optimization as trajectory discovery: instead of approximating the full response surface, the method maintains and refines a low-entropy information state that concentrates search on target-relevant directions. The approach couples data, model beliefs, and physics/structure priors through dimension-aware information budgeting, adaptive bootstrapped distillation over a heterogeneous surrogate reservoir, and structure-aware candidate manifold analysis with Kalman-inspired multi-model fusion to balance consensus-driven exploitation and disagreement-driven exploration. Evaluated under a single unified protocol without dataset-specific tuning, the framework improves sample efficiency and reliability across 14 single- and multi-objective materials design tasks spanning candidate pools from $600$ to $4 \times 10^6$ and feature dimensions from $10$ to $10^3$, typically reaching top-performing regions within 100 evaluations. Complementary 20-dimensional synthetic benchmarks (Ackley, Rastrigin, Schwefel) further demonstrate robustness to rugged and multimodal landscapes.
GeoDecoder: Empowering Multimodal Map Understanding
Jan 26, 2024


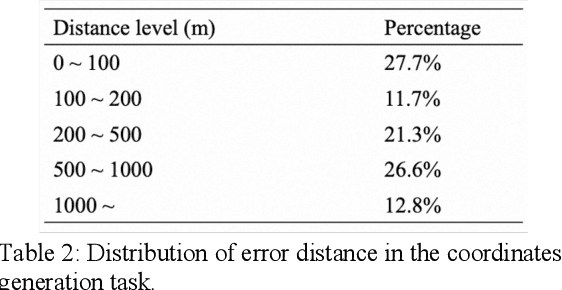
This paper presents GeoDecoder, a dedicated multimodal model designed for processing geospatial information in maps. Built on the BeitGPT architecture, GeoDecoder incorporates specialized expert modules for image and text processing. On the image side, GeoDecoder utilizes GaoDe Amap as the underlying base map, which inherently encompasses essential details about road and building shapes, relative positions, and other attributes. Through the utilization of rendering techniques, the model seamlessly integrates external data and features such as symbol markers, drive trajectories, heatmaps, and user-defined markers, eliminating the need for extra feature engineering. The text module of GeoDecoder accepts various context texts and question prompts, generating text outputs in the style of GPT. Furthermore, the GPT-based model allows for the training and execution of multiple tasks within the same model in an end-to-end manner. To enhance map cognition and enable GeoDecoder to acquire knowledge about the distribution of geographic entities in Beijing, we devised eight fundamental geospatial tasks and conducted pretraining of the model using large-scale text-image samples. Subsequently, rapid fine-tuning was performed on three downstream tasks, resulting in significant performance improvements. The GeoDecoder model demonstrates a comprehensive understanding of map elements and their associated operations, enabling efficient and high-quality application of diverse geospatial tasks in different business scenarios.