 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETR: Outcome-Guided Elastic Trust Regions for Policy Optimization
Jan 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an important paradigm for unlocking reasoning capabilities in large language models, exemplified by the success of OpenAI o1 and DeepSeek-R1. Currently, Group Relative Policy Optimization (GRPO) stands as the dominant algorithm in this domain due to its stable training and critic-free efficiency. However, we argue that GRPO suffers from a structural limitation: it imposes a uniform, static trust region constraint across all samples. This design implicitly assumes signal homogeneity, a premise misaligned with the heterogeneous nature of outcome-driven learning, where advantage magnitudes and variances fluctuate significantly. Consequently, static constraints fail to fully exploit high-quality signals while insufficiently suppressing noise, often precipitating rapid entropy collapse. To address this, we propose \textbf{E}lastic \textbf{T}rust \textbf{R}egions (\textbf{ETR}), a dynamic mechanism that aligns optimization constraints with signal quality. ETR constructs a signal-aware landscape through dual-level elasticity: at the micro level, it scales clipping boundaries based on advantage magnitude to accelerate learning from high-confidence paths; at the macro level, it leverages group variance to implicitly allocate larger update budgets to tasks in the optimal learning zone. Extensive experiments on AIME and MATH benchmarks demonstrate that ETR consistently outperforms GRPO, achieving superior accuracy while effectively mitigating policy entropy degradation to ensure sustained exploration.
Eliminating Inductive Bias in Reward Models with Information-Theoretic Guidance
Dec 29, 2025Reward models (RMs) are essential in reinforcement learning from human feedback (RLHF) to align large language models (LLMs) with human values. However, RM training data is commonly recognized as low-quality, containing inductive biases that can easily lead to overfitting and reward hacking. For example, more detailed and comprehensive responses are usually human-preferred but with more words, leading response length to become one of the inevitable inductive biases. A limited number of prior RM debiasing approaches either target a single specific type of bias or model the problem with only simple linear correlations, \textit{e.g.}, Pearson coefficients. To mitigate more complex and diverse inductive biases in reward modeling, we introduce a novel information-theoretic debiasing method called \textbf{D}ebiasing via \textbf{I}nformation optimization for \textbf{R}M (DIR). Inspired by the information bottleneck (IB), we maximize the mutual information (MI) between RM scores and human preference pairs, while minimizing the MI between RM outputs and biased attributes of preference inputs. With theoretical justification from information theory, DIR can handle more sophisticated types of biases with non-linear correlations, broadly extending the real-world application scenarios for RM debiasing methods. In experiments, we verify the effectiveness of DIR with three types of inductive biases: \textit{response length}, \textit{sycophancy}, and \textit{format}. We discover that DIR not only effectively mitigates target inductive biases but also enhances RLHF performance across diverse benchmarks, yielding better generalization abilities. The code and training recipes are available at https://github.com/Qwen-Applications/DIR.
Search Self-play: Pushing the Frontier of Agent Capability without Supervision
Oct 21, 2025Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents. However, RLVR highly depends on well-crafted task queries and corresponding ground-truth answers to provide accurate rewards, which requires massive human efforts and hinders the RL scaling processes, especially under agentic scenarios. Although a few recent works explore task synthesis methods, the difficulty of generated agentic tasks can hardly be controlled to provide effective RL training advantages. To achieve agentic RLVR with higher scalability, we explore self-play training for deep search agents, in which the learning LLM utilizes multi-turn search engine calling and acts simultaneously as both a task proposer and a problem solver. The task proposer aims to generate deep search queries with well-defined ground-truth answers and increasing task difficulty. The problem solver tries to handle the generated search queries and output the correct answer predictions. To ensure that each generated search query has accurate ground truth, we collect all the searching results from the proposer's trajectory as external knowledge, then conduct retrieval-augmentation generation (RAG) to test whether the proposed query can be correctly answered with all necessary search documents provided. In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation. With substantial experimental results, we find that SSP can significantly improve search agents' performance uniformly on various benchmarks without any supervision under both from-scratch and continuous RL training setups. The code is at https://github.com/Alibaba-Quark/SSP.
Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
Mar 07, 2022
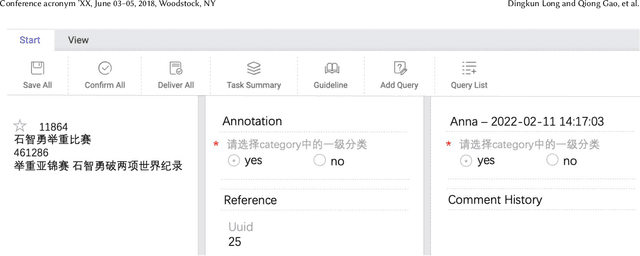
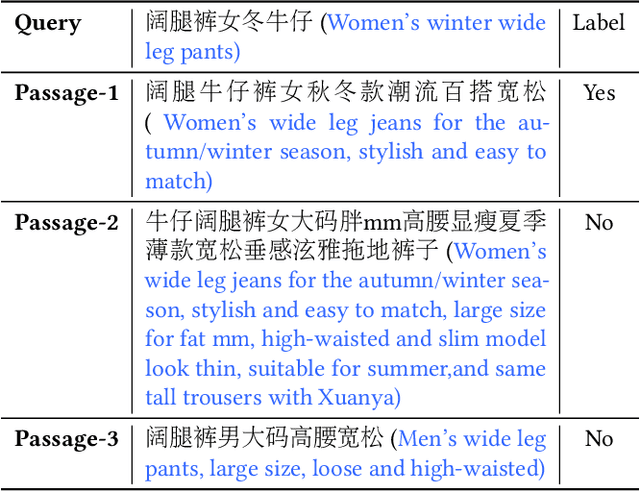
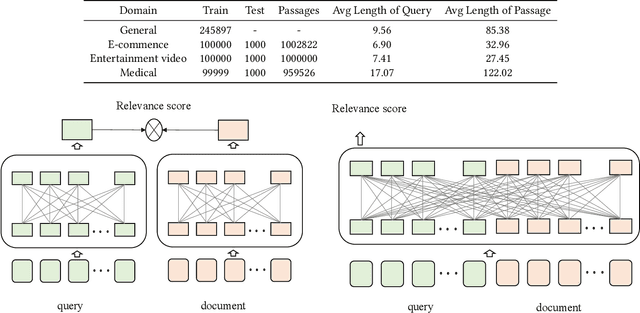
Passage retrieval is a fundamental task in information retrieval (IR) research, which has drawn much attention recently. In English field, the availability of large-scale annotated dataset (e.g, MS MARCO) and the emergence of deep pre-trained language models (e.g, BERT) have resulted in a substantial improvement of existing passage retrieval systems. However, in Chinese field, especially for specific domain, passage retrieval systems are still immature due to quality-annotated dataset being limited by scale. Therefore, in this paper, we present a novel multi-domain Chinese dataset for passage retrieval (Multi-CPR). The dataset is collected from three different domains, including E-commerce, Entertainment video and Medical. Each dataset contains millions of passages and a certain amount of human annotated query-passage related pairs. We implement various representative passage retrieval methods as baselines. We find that the performance of retrieval models trained on dataset from general domain will inevitably decrease on specific domain. Nevertheless, passage retrieval system built on in-domain annotated dataset can achieve significant improvement, which indeed demonstrates the necessity of domain labeled data for further optimization. We hope the release of the Multi-CPR dataset could benchmark Chinese passage retrieval task in specific domain and also make advances for future studies.
Visualizing and Understanding Vision System
Jun 11, 2020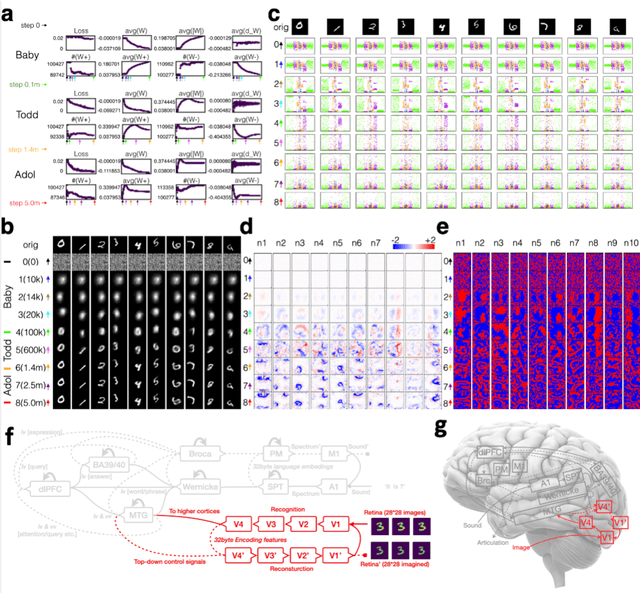

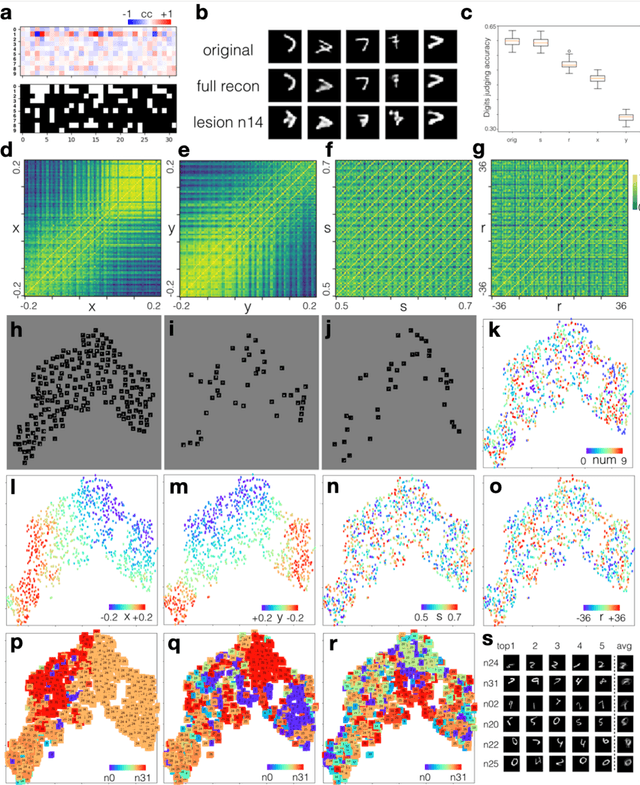
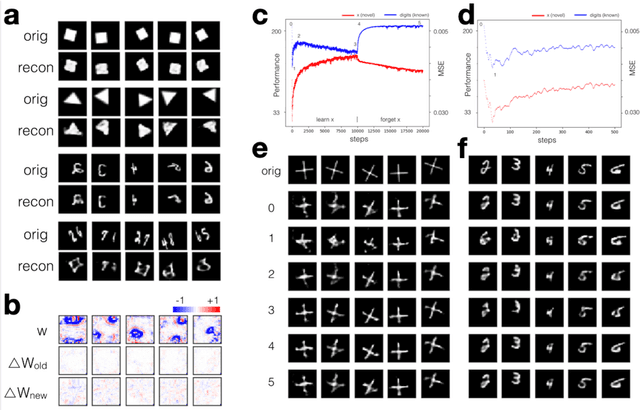
How the human vision system addresses the object identity-preserving recognition problem is largely unknown. Here, we use a vision recognition-reconstruction network (RRN) to investigate the development, recognition, learning and forgetting mechanisms, and achieve similar characteristics to electrophysiological measurements in monkeys. First, in network development study, the RRN also experiences critical developmental stages characterized by specificities in neuron types, synapse and activation patterns, and visual task performance from the early stage of coarse salience map recognition to mature stage of fine structure recognition. In digit recognition study, we witness that the RRN could maintain object invariance representation under various viewing conditions by coordinated adjustment of responses of population neurons. And such concerted population responses contained untangled object identity and properties information that could be accurately extracted via high-level cortices or even a simple weighted summation decoder. In the learning and forgetting study, novel structure recognition is implemented by adjusting entire synapses in low magnitude while pattern specificities of original synaptic connectivity are preserved, which guaranteed a learning process without disrupting the existing functionalities. This work benefits the understanding of the human visual processing mechanism and the development of human-like machine intelligence.
Human-like general language processing
May 29, 2020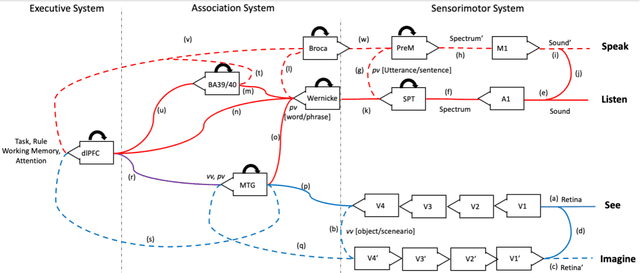

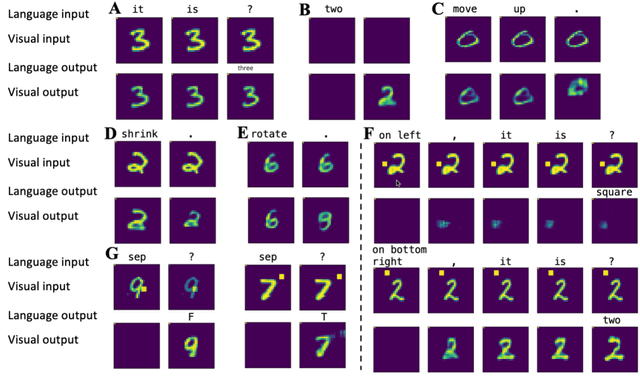

Using language makes human beings surpass animals in wisdom. To let machines understand, learn, and use language flexibly, we propose a human-like general language processing (HGLP) architecture, which contains sensorimotor, association, and cognitive systems. The HGLP network learns from easy to hard like a child, understands word meaning by coactivating multimodal neurons, comprehends and generates sentences by real-time constructing a virtual world model, and can express the whole thinking process verbally. HGLP rapidly learned 10+ different tasks including object recognition, sentence comprehension, imagination, attention control, query, inference, motion judgement, mixed arithmetic operation, digit tracing and writing, and human-like iterative thinking process guided by language. Language in the HGLP framework is not matching nor correlation statistics, but a script that can describe and control the imagination.