 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
Paper and Code

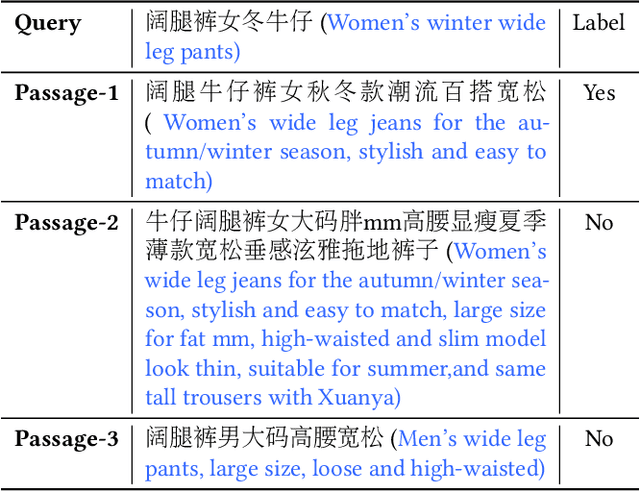
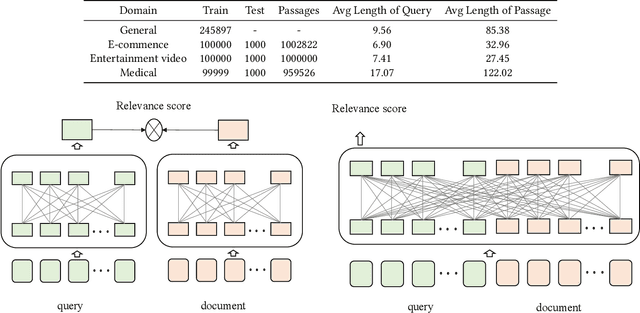
Passage retrieval is a fundamental task in information retrieval (IR) research, which has drawn much attention recently. In English field, the availability of large-scale annotated dataset (e.g, MS MARCO) and the emergence of deep pre-trained language models (e.g, BERT) have resulted in a substantial improvement of existing passage retrieval systems. However, in Chinese field, especially for specific domain, passage retrieval systems are still immature due to quality-annotated dataset being limited by scale. Therefore, in this paper, we present a novel multi-domain Chinese dataset for passage retrieval (Multi-CPR). The dataset is collected from three different domains, including E-commerce, Entertainment video and Medical. Each dataset contains millions of passages and a certain amount of human annotated query-passage related pairs. We implement various representative passage retrieval methods as baselines. We find that the performance of retrieval models trained on dataset from general domain will inevitably decrease on specific domain. Nevertheless, passage retrieval system built on in-domain annotated dataset can achieve significant improvement, which indeed demonstrates the necessity of domain labeled data for further optimization. We hope the release of the Multi-CPR dataset could benchmark Chinese passage retrieval task in specific domain and also make advances for future studies.