 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSearch-SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Alignment
Feb 19, 2025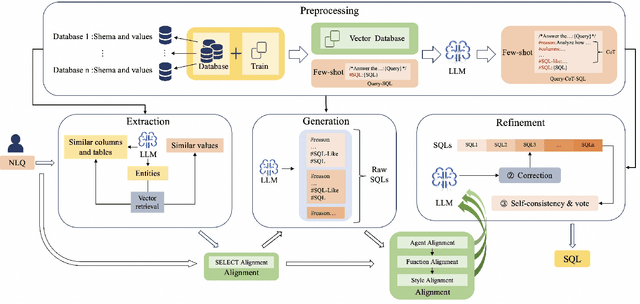
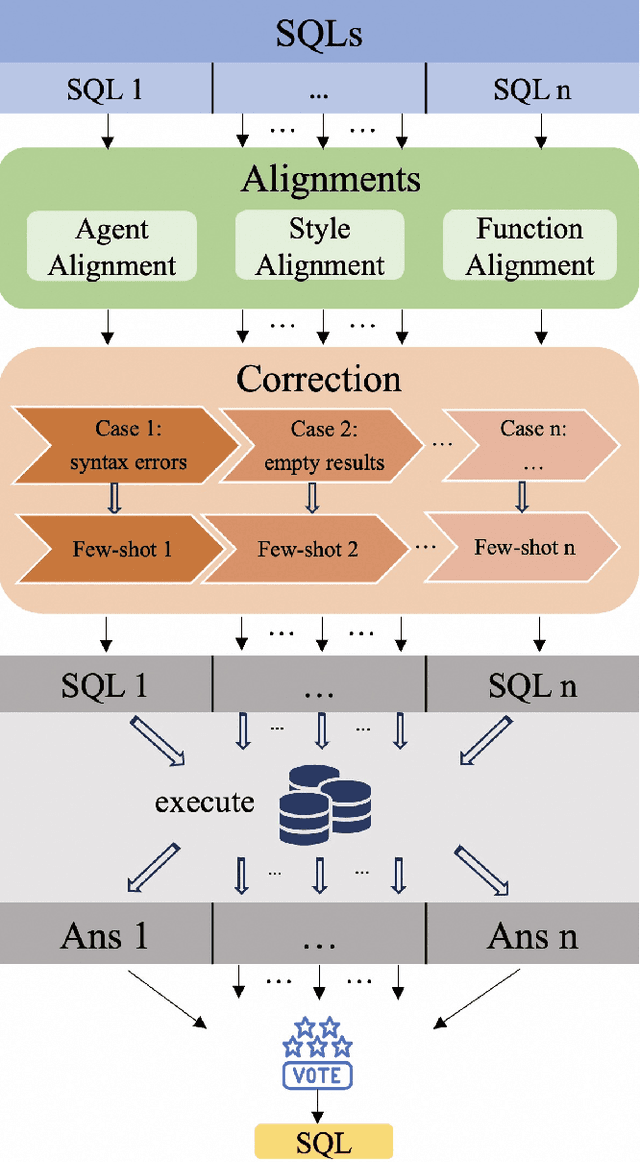
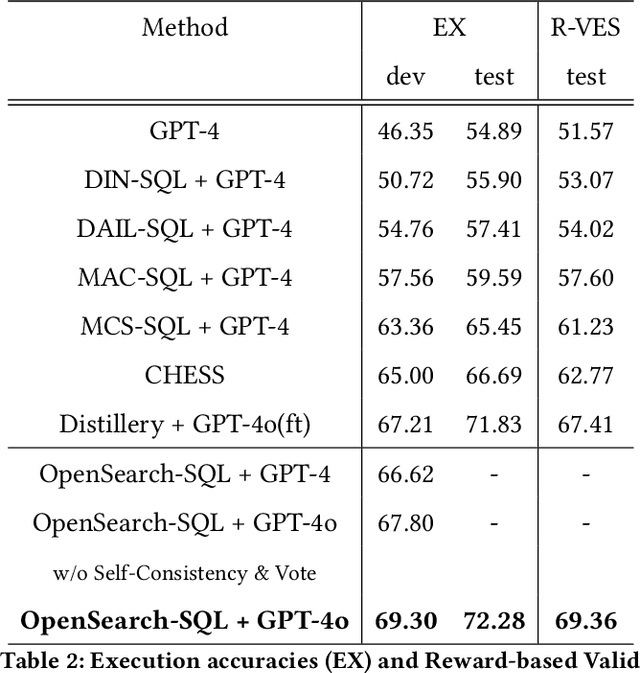
Although multi-agent collaborative Large Language Models (LLMs) have achieved significant breakthroughs in the Text-to-SQL task, their performance is still constrained by various factors. These factors include the incompleteness of the framework, failure to follow instructions, and model hallucination problems. To address these problems, we propose OpenSearch-SQL, which divides the Text-to-SQL task into four main modules: Preprocessing, Extraction, Generation, and Refinement, along with an Alignment module based on a consistency alignment mechanism. This architecture aligns the inputs and outputs of agents through the Alignment module, reducing failures in instruction following and hallucination. Additionally, we designed an intermediate language called SQL-Like and optimized the structured CoT based on SQL-Like. Meanwhile, we developed a dynamic few-shot strategy in the form of self-taught Query-CoT-SQL. These methods have significantly improved the performance of LLMs in the Text-to-SQL task. In terms of model selection, we directly applied the base LLMs without any post-training, thereby simplifying the task chain and enhancing the framework's portability. Experimental results show that OpenSearch-SQL achieves an execution accuracy(EX) of 69.3% on the BIRD development set, 72.28% on the test set, and a reward-based validity efficiency score (R-VES) of 69.36%, with all three metrics ranking first at the time of submission. These results demonstrate the comprehensive advantages of the proposed method in both effectiveness and efficiency.
Hesitation and Tolerance in Recommender Systems
Dec 13, 2024User interactions in recommender systems are inherently complex, often involving behaviors that go beyond simple acceptance or rejection. One particularly common behavior is hesitation, where users deliberate over recommended items, signaling uncertainty. Our large-scale surveys, with 6,644 and 3,864 responses respectively, confirm that hesitation is not only widespread but also has a profound impact on user experiences. When users spend additional time engaging with content they are ultimately uninterested in, this can lead to negative emotions, a phenomenon we term as tolerance. The surveys reveal that such tolerance behaviors often arise after hesitation and can erode trust, satisfaction, and long-term loyalty to the platform. For instance, a click might reflect a need for more information rather than genuine interest, and prolonged exposure to unsuitable content amplifies frustration. This misalignment between user intent and system interpretation introduces noise into recommendation training, resulting in suggestions that increase uncertainty and disengagement. To address these issues, we identified signals indicative of tolerance behavior and analyzed datasets from both e-commerce and short-video platforms. The analysis shows a strong correlation between increased tolerance behavior and decreased user activity. We integrated these insights into the training process of a recommender system for a major short-video platform. Results from four independent online A/B experiments demonstrated significant improvements in user retention, achieved with minimal additional computational costs. These findings underscore the importance of recognizing hesitation as a ubiquitous user behavior and addressing tolerance to enhance satisfaction, build trust, and sustain long-term engagement in recommender systems.
Hybrid Retrieval and Multi-stage Text Ranking Solution at TREC 2022 Deep Learning Track
Aug 23, 2023



Large-scale text retrieval technology has been widely used in various practical business scenarios. This paper presents our systems for the TREC 2022 Deep Learning Track. We explain the hybrid text retrieval and multi-stage text ranking method adopted in our solution. The retrieval stage combined the two structures of traditional sparse retrieval and neural dense retrieval. In the ranking stage, in addition to the full interaction-based ranking model built on large pre-trained language model, we also proposes a lightweight sub-ranking module to further enhance the final text ranking performance. Evaluation results demonstrate the effectiveness of our proposed approach. Our models achieve the 1st and 4th rank on the test set of passage ranking and document ranking respectively.
Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
Mar 07, 2022
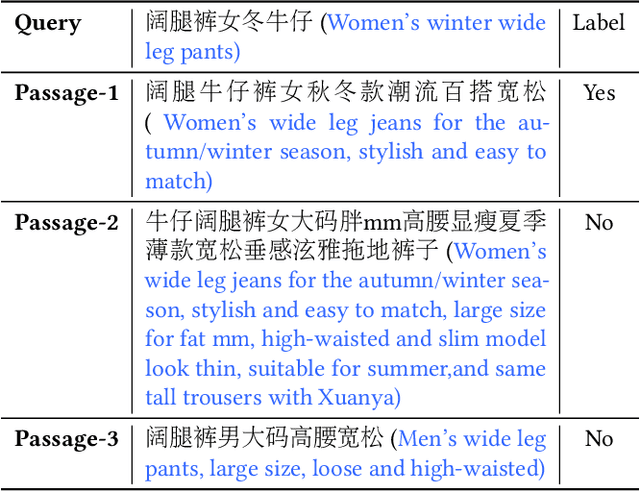
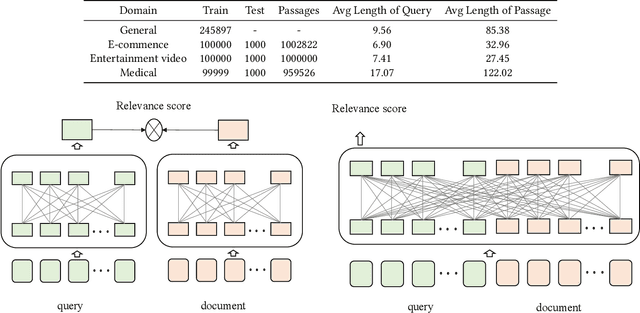
Passage retrieval is a fundamental task in information retrieval (IR) research, which has drawn much attention recently. In English field, the availability of large-scale annotated dataset (e.g, MS MARCO) and the emergence of deep pre-trained language models (e.g, BERT) have resulted in a substantial improvement of existing passage retrieval systems. However, in Chinese field, especially for specific domain, passage retrieval systems are still immature due to quality-annotated dataset being limited by scale. Therefore, in this paper, we present a novel multi-domain Chinese dataset for passage retrieval (Multi-CPR). The dataset is collected from three different domains, including E-commerce, Entertainment video and Medical. Each dataset contains millions of passages and a certain amount of human annotated query-passage related pairs. We implement various representative passage retrieval methods as baselines. We find that the performance of retrieval models trained on dataset from general domain will inevitably decrease on specific domain. Nevertheless, passage retrieval system built on in-domain annotated dataset can achieve significant improvement, which indeed demonstrates the necessity of domain labeled data for further optimization. We hope the release of the Multi-CPR dataset could benchmark Chinese passage retrieval task in specific domain and also make advances for future studies.