 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHesitation and Tolerance in Recommender Systems
Dec 13, 2024User interactions in recommender systems are inherently complex, often involving behaviors that go beyond simple acceptance or rejection. One particularly common behavior is hesitation, where users deliberate over recommended items, signaling uncertainty. Our large-scale surveys, with 6,644 and 3,864 responses respectively, confirm that hesitation is not only widespread but also has a profound impact on user experiences. When users spend additional time engaging with content they are ultimately uninterested in, this can lead to negative emotions, a phenomenon we term as tolerance. The surveys reveal that such tolerance behaviors often arise after hesitation and can erode trust, satisfaction, and long-term loyalty to the platform. For instance, a click might reflect a need for more information rather than genuine interest, and prolonged exposure to unsuitable content amplifies frustration. This misalignment between user intent and system interpretation introduces noise into recommendation training, resulting in suggestions that increase uncertainty and disengagement. To address these issues, we identified signals indicative of tolerance behavior and analyzed datasets from both e-commerce and short-video platforms. The analysis shows a strong correlation between increased tolerance behavior and decreased user activity. We integrated these insights into the training process of a recommender system for a major short-video platform. Results from four independent online A/B experiments demonstrated significant improvements in user retention, achieved with minimal additional computational costs. These findings underscore the importance of recognizing hesitation as a ubiquitous user behavior and addressing tolerance to enhance satisfaction, build trust, and sustain long-term engagement in recommender systems.
Our Model Achieves Excellent Performance on MovieLens: What Does it Mean?
Jul 19, 2023



A typical benchmark dataset for recommender system (RecSys) evaluation consists of user-item interactions generated on a platform within a time period. The interaction generation mechanism partially explains why a user interacts with (e.g.,like, purchase, rate) an item, and the context of when a particular interaction happened. In this study, we conduct a meticulous analysis on the MovieLens dataset and explain the potential impact on using the dataset for evaluating recommendation algorithms. We make a few main findings from our analysis. First, there are significant differences in user interactions at the different stages when a user interacts with the MovieLens platform. The early interactions largely define the user portrait which affect the subsequent interactions. Second, user interactions are highly affected by the candidate movies that are recommended by the platform's internal recommendation algorithm(s). Removal of interactions that happen nearer to the last few interactions of a user leads to increasing difficulty in learning user preference, thus deteriorating recommendation accuracy. Third, changing the order of user interactions makes it more difficult for sequential algorithms to capture the progressive interaction process. Based on these findings, we further discuss the discrepancy between the interaction generation mechanism that is employed by the MovieLens system and that of typical real world recommendation scenarios. In summary, models that achieve excellent recommendation accuracy on the MovieLens dataset may not demonstrate superior performance in practice for at least two kinds of differences: (i) the differences in the contexts of user-item interaction generation, and (ii) the differences in user knowledge about the item collections.
Retraining A Graph-based Recommender with Interests Disentanglement
May 05, 2023



In a practical recommender system, new interactions are continuously observed. Some interactions are expected, because they largely follow users' long-term preferences. Some other interactions are indications of recent trends in user preference changes or marketing positions of new items. Accordingly, the recommender needs to be periodically retrained or updated to capture the new trends, and yet not to forget the long-term preferences. In this paper, we propose a novel and generic retraining framework called Disentangled Incremental Learning (DIL) for graph-based recommenders. We assume that long-term preferences are well captured in the existing model, in the form of model parameters learned from past interactions. New preferences can be learned from the user-item bipartite graph constructed using the newly observed interactions. In DIL, we design an Information Extraction Module to extract historical preferences from the existing model. Then we blend the historical and new preferences in the form of node embeddings in the new graph, through a Disentanglement Module. The essence of the disentanglement module is to decorrelate the historical and new preferences so that both can be well captured, via carefully designed losses. Through experiments on three benchmark datasets, we show the effectiveness of DIL in capturing dynamics of useritem interactions. We also demonstrate the robustness of DIL by attaching it to two base models - LightGCN and NGCF.
Recommender May Not Favor Loyal Users
Apr 12, 2022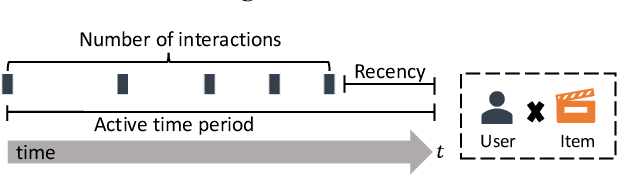

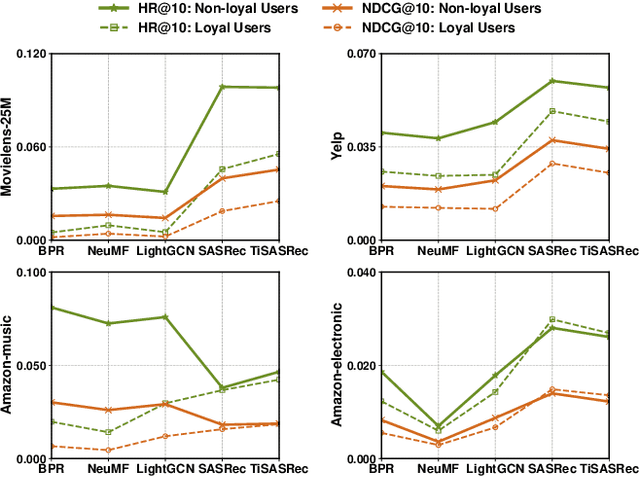
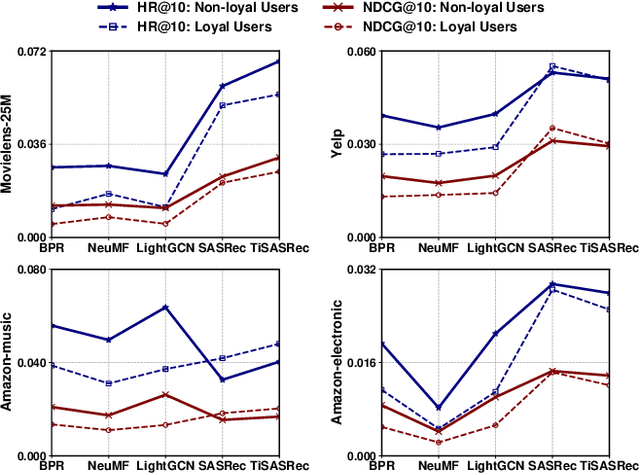
In academic research, recommender systems are often evaluated on benchmark datasets, without much consideration about the global timeline. Hence, we are unable to answer questions like: Do loyal users enjoy better recommendations than non-loyal users? Loyalty can be defined by the time period a user has been active in a recommender system, or by the number of historical interactions a user has. In this paper, we offer a comprehensive analysis of recommendation results along global timeline. We conduct experiments with five widely used models, i.e., BPR, NeuMF, LightGCN, SASRec and TiSASRec, on four benchmark datasets, i.e., MovieLens-25M, Yelp, Amazon-music, and Amazon-electronic. Our experiment results give an answer "No" to the above question. Users with many historical interactions suffer from relatively poorer recommendations. Users who stay with the system for a short time period enjoy better recommendations. Both findings are counter-intuitive. Interestingly, users who have recently interacted with the system, with respect to the time point of the test instance, enjoy better recommendations. The finding on recency applies to all users, regardless of users' loyalty. Our study offers a different perspective to understand recommender performance, and our findings could trigger a revisit of recommender model design.