 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSearch-SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Alignment
Feb 19, 2025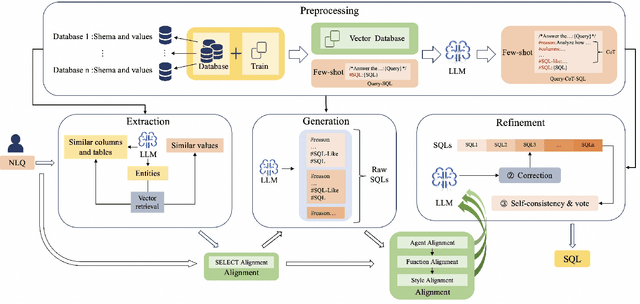
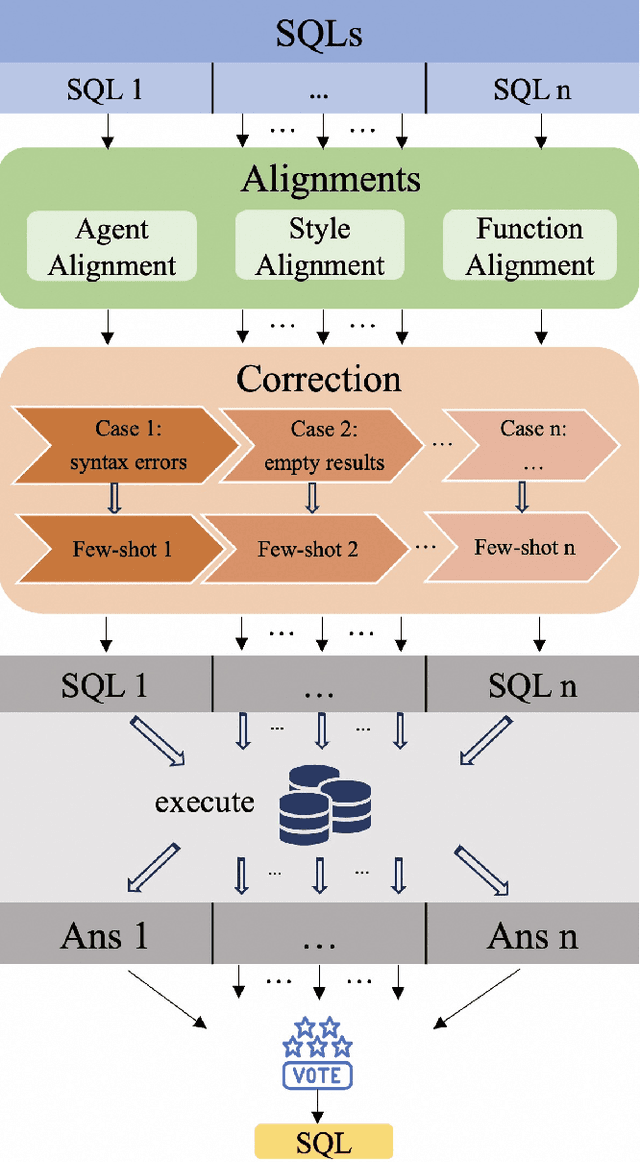
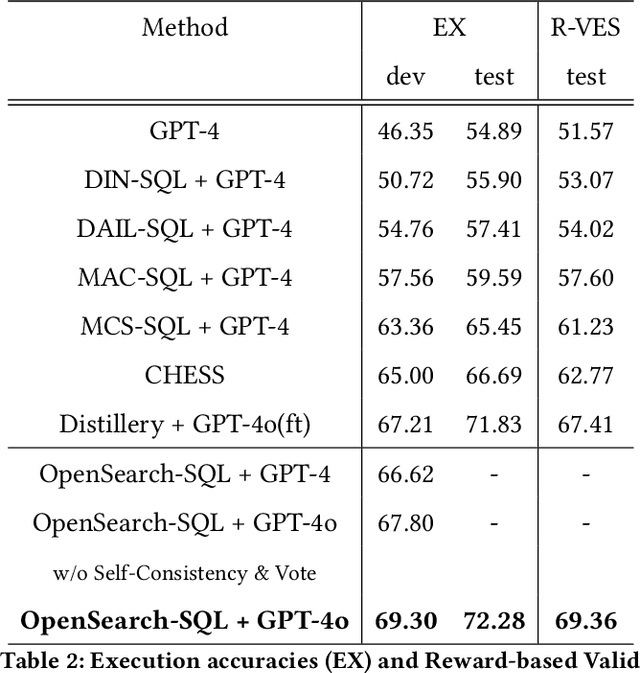
Although multi-agent collaborative Large Language Models (LLMs) have achieved significant breakthroughs in the Text-to-SQL task, their performance is still constrained by various factors. These factors include the incompleteness of the framework, failure to follow instructions, and model hallucination problems. To address these problems, we propose OpenSearch-SQL, which divides the Text-to-SQL task into four main modules: Preprocessing, Extraction, Generation, and Refinement, along with an Alignment module based on a consistency alignment mechanism. This architecture aligns the inputs and outputs of agents through the Alignment module, reducing failures in instruction following and hallucination. Additionally, we designed an intermediate language called SQL-Like and optimized the structured CoT based on SQL-Like. Meanwhile, we developed a dynamic few-shot strategy in the form of self-taught Query-CoT-SQL. These methods have significantly improved the performance of LLMs in the Text-to-SQL task. In terms of model selection, we directly applied the base LLMs without any post-training, thereby simplifying the task chain and enhancing the framework's portability. Experimental results show that OpenSearch-SQL achieves an execution accuracy(EX) of 69.3% on the BIRD development set, 72.28% on the test set, and a reward-based validity efficiency score (R-VES) of 69.36%, with all three metrics ranking first at the time of submission. These results demonstrate the comprehensive advantages of the proposed method in both effectiveness and efficiency.
MixDec Sampling: A Soft Link-based Sampling Method of Graph Neural Network for Recommendation
Feb 12, 2025Graph neural networks have been widely used in recent recommender systems, where negative sampling plays an important role. Existing negative sampling methods restrict the relationship between nodes as either hard positive pairs or hard negative pairs. This leads to the loss of structural information, and lacks the mechanism to generate positive pairs for nodes with few neighbors. To overcome limitations, we propose a novel soft link-based sampling method, namely MixDec Sampling, which consists of Mixup Sampling module and Decay Sampling module. The Mixup Sampling augments node features by synthesizing new nodes and soft links, which provides sufficient number of samples for nodes with few neighbors. The Decay Sampling strengthens the digestion of graph structure information by generating soft links for node embedding learning. To the best of our knowledge, we are the first to model sampling relationships between nodes by soft links in GNN-based recommender systems. Extensive experiments demonstrate that the proposed MixDec Sampling can significantly and consistently improve the recommendation performance of several representative GNN-based models on various recommendation benchmarks.
Knowledge Soft Integration for Multimodal Recommendation
May 12, 2023

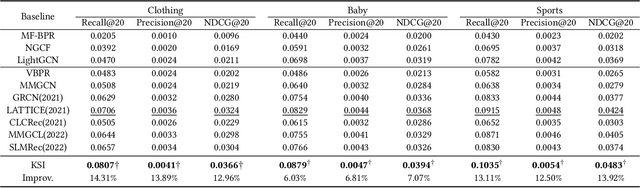

One of the main challenges in modern recommendation systems is how to effectively utilize multimodal content to achieve more personalized recommendations. Despite various proposed solutions, most of them overlook the mismatch between the knowledge gained from independent feature extraction processes and downstream recommendation tasks. Specifically, multimodal feature extraction processes do not incorporate prior knowledge relevant to recommendation tasks, while recommendation tasks often directly use these multimodal features as side information. This mismatch can lead to model fitting biases and performance degradation, which this paper refers to as the \textit{curse of knowledge} problem. To address this issue, we propose using knowledge soft integration to balance the utilization of multimodal features and the curse of knowledge problem it brings about. To achieve this, we put forward a Knowledge Soft Integration framework for the multimodal recommendation, abbreviated as KSI, which is composed of the Structure Efficiently Injection (SEI) module and the Semantic Soft Integration (SSI) module. In the SEI module, we model the modality correlation between items using Refined Graph Neural Network (RGNN), and introduce a regularization term to reduce the redundancy of user/item representations. In the SSI module, we design a self-supervised retrieval task to further indirectly integrate the semantic knowledge of multimodal features, and enhance the semantic discrimination of item representations. Extensive experiments on three benchmark datasets demonstrate the superiority of KSI and validate the effectiveness of its two modules.
Investigating Graph Structure Information for Entity Alignment with Dangling Cases
Apr 10, 2023Entity alignment (EA) aims to discover the equivalent entities in different knowledge graphs (KGs), which play an important role in knowledge engineering. Recently, EA with dangling entities has been proposed as a more realistic setting, which assumes that not all entities have corresponding equivalent entities. In this paper, we focus on this setting. Some work has explored this problem by leveraging translation API, pre-trained word embeddings, and other off-the-shelf tools. However, these approaches over-rely on the side information (e.g., entity names), and fail to work when the side information is absent. On the contrary, they still insufficiently exploit the most fundamental graph structure information in KG. To improve the exploitation of the structural information, we propose a novel entity alignment framework called Weakly-Optimal Graph Contrastive Learning (WOGCL), which is refined on three dimensions : (i) Model. We propose a novel Gated Graph Attention Network to capture local and global graph structure similarity. (ii) Training. Two learning objectives: contrastive learning and optimal transport learning are designed to obtain distinguishable entity representations via the optimal transport plan. (iii) Inference. In the inference phase, a PageRank-based method is proposed to calculate higher-order structural similarity. Extensive experiments on two dangling benchmarks demonstrate that our WOGCL outperforms the current state-of-the-art methods with pure structural information in both traditional (relaxed) and dangling (consolidated) settings. The code will be public soon.
Global Mixup: Eliminating Ambiguity with Clustering
Jun 06, 2022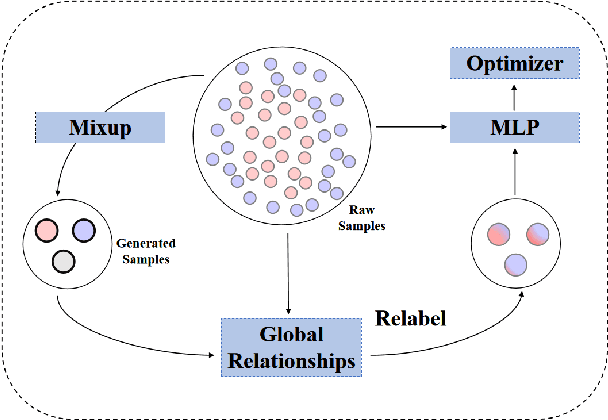
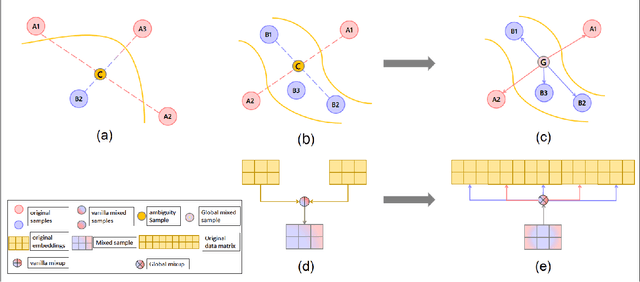
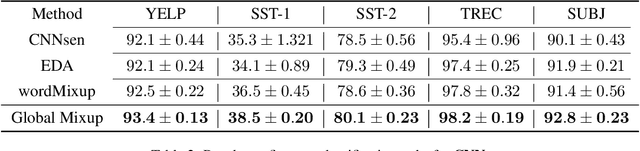
Data augmentation with \textbf{Mixup} has been proven an effective method to regularize the current deep neural networks. Mixup generates virtual samples and corresponding labels at once through linear interpolation. However, this one-stage generation paradigm and the use of linear interpolation have the following two defects: (1) The label of the generated sample is directly combined from the labels of the original sample pairs without reasonable judgment, which makes the labels likely to be ambiguous. (2) linear combination significantly limits the sampling space for generating samples. To tackle these problems, we propose a novel and effective augmentation method based on global clustering relationships named \textbf{Global Mixup}. Specifically, we transform the previous one-stage augmentation process into two-stage, decoupling the process of generating virtual samples from the labeling. And for the labels of the generated samples, relabeling is performed based on clustering by calculating the global relationships of the generated samples. In addition, we are no longer limited to linear relationships but generate more reliable virtual samples in a larger sampling space. Extensive experiments for \textbf{CNN}, \textbf{LSTM}, and \textbf{BERT} on five tasks show that Global Mixup significantly outperforms previous state-of-the-art baselines. Further experiments also demonstrate the advantage of Global Mixup in low-resource scenarios.