 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAN: Stage-Adaptive Network for Multi-Task Recommendation by Learning User Lifecycle-Based Representation
Jun 21, 2023



Recommendation systems play a vital role in many online platforms, with their primary objective being to satisfy and retain users. As directly optimizing user retention is challenging, multiple evaluation metrics are often employed. Existing methods generally formulate the optimization of these evaluation metrics as a multitask learning problem, but often overlook the fact that user preferences for different tasks are personalized and change over time. Identifying and tracking the evolution of user preferences can lead to better user retention. To address this issue, we introduce the concept of "user lifecycle", consisting of multiple stages characterized by users' varying preferences for different tasks. We propose a novel Stage-Adaptive Network (STAN) framework for modeling user lifecycle stages. STAN first identifies latent user lifecycle stages based on learned user preferences, and then employs the stage representation to enhance multi-task learning performance. Our experimental results using both public and industrial datasets demonstrate that the proposed model significantly improves multi-task prediction performance compared to state-of-the-art methods, highlighting the importance of considering user lifecycle stages in recommendation systems. Furthermore, online A/B testing reveals that our model outperforms the existing model, achieving a significant improvement of 3.05% in staytime per user and 0.88% in CVR. These results indicate that our approach effectively improves the overall efficiency of the multi-task recommendation system.
Knowledge Soft Integration for Multimodal Recommendation
May 12, 2023

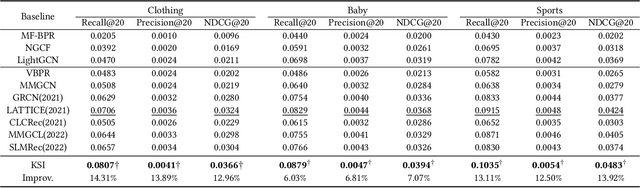

One of the main challenges in modern recommendation systems is how to effectively utilize multimodal content to achieve more personalized recommendations. Despite various proposed solutions, most of them overlook the mismatch between the knowledge gained from independent feature extraction processes and downstream recommendation tasks. Specifically, multimodal feature extraction processes do not incorporate prior knowledge relevant to recommendation tasks, while recommendation tasks often directly use these multimodal features as side information. This mismatch can lead to model fitting biases and performance degradation, which this paper refers to as the \textit{curse of knowledge} problem. To address this issue, we propose using knowledge soft integration to balance the utilization of multimodal features and the curse of knowledge problem it brings about. To achieve this, we put forward a Knowledge Soft Integration framework for the multimodal recommendation, abbreviated as KSI, which is composed of the Structure Efficiently Injection (SEI) module and the Semantic Soft Integration (SSI) module. In the SEI module, we model the modality correlation between items using Refined Graph Neural Network (RGNN), and introduce a regularization term to reduce the redundancy of user/item representations. In the SSI module, we design a self-supervised retrieval task to further indirectly integrate the semantic knowledge of multimodal features, and enhance the semantic discrimination of item representations. Extensive experiments on three benchmark datasets demonstrate the superiority of KSI and validate the effectiveness of its two modules.
Click-aware Structure Transfer with Sample Weight Assignment for Post-Click Conversion Rate Estimation
Apr 03, 2023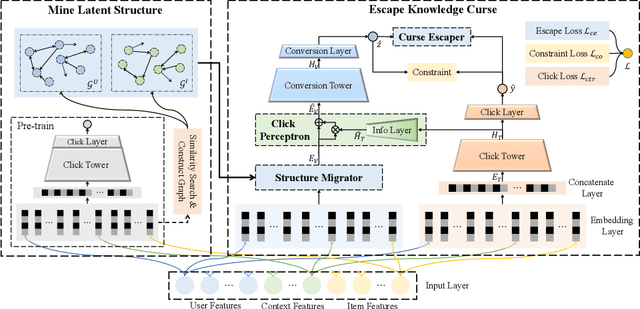

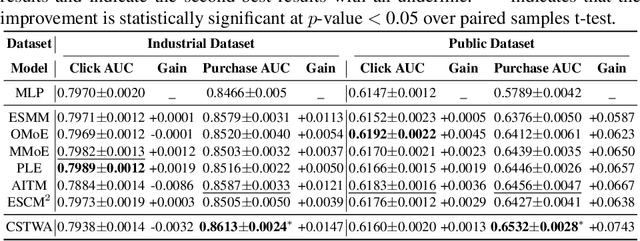
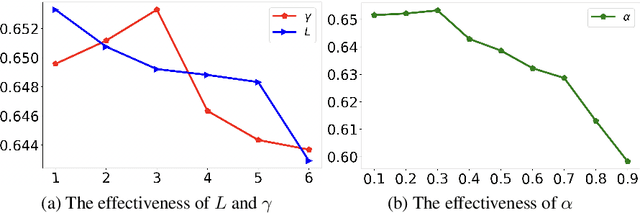
Post-click Conversion Rate (CVR) prediction task plays an essential role in industrial applications, such as recommendation and advertising. Conventional CVR methods typically suffer from the data sparsity problem as they rely only on samples where the user has clicked. To address this problem, researchers have introduced the method of multi-task learning, which utilizes non-clicked samples and shares feature representations of the Click-Through Rate (CTR) task with the CVR task. However, it should be noted that the CVR and CTR tasks are fundamentally different and may even be contradictory. Therefore, introducing a large amount of CTR information without distinction may drown out valuable information related to CVR. This phenomenon is called the curse of knowledge problem in this paper. To tackle this issue, we argue that a trade-off should be achieved between the introduction of large amounts of auxiliary information and the protection of valuable information related to CVR. Hence, we propose a Click-aware Structure Transfer model with sample Weight Assignment, abbreviated as CSTWA. It pays more attention to the latent structure information, which can filter the input information that is related to CVR, instead of directly sharing feature representations. Meanwhile, to capture the representation conflict between CTR and CVR, we calibrate the representation layer and reweight the discriminant layer to excavate the click bias information from the CTR tower. Moreover, it incorporates a sample weight assignment algorithm biased towards CVR modeling, to make the knowledge from CTR would not mislead the CVR. Extensive experiments on industrial and public datasets have demonstrated that CSTWA significantly outperforms widely used and competitive models.
Social4Rec: Distilling User Preference from Social Graph for Video Recommendation in Tencent
Feb 23, 2023Despite recommender systems play a key role in network content platforms, mining the user's interests is still a significant challenge. Existing works predict the user interest by utilizing user behaviors, i.e., clicks, views, etc., but current solutions are ineffective when users perform unsettled activities. The latter ones involve new users, which have few activities of any kind, and sparse users who have low-frequency behaviors. We uniformly describe both these user-types as "cold users", which are very common but often neglected in network content platforms. To address this issue, we enhance the representation of the user interest by combining his social interest, e.g., friendship, following bloggers, interest groups, etc., with the activity behaviors. Thus, in this work, we present a novel algorithm entitled SocialNet, which adopts a two-stage method to progressively extract the coarse-grained and fine-grained social interest. Our technique then concatenates SocialNet's output with the original user representation to get the final user representation that combines behavior interests and social interests. Offline experiments on Tencent video's recommender system demonstrate the superiority over the baseline behavior-based model. The online experiment also shows a significant performance improvement in clicks and view time in the real-world recommendation system. The source code is available at https://github.com/Social4Rec/SocialNet.
Neighbor Based Enhancement for the Long-Tail Ranking Problem in Video Rank Models
Feb 16, 2023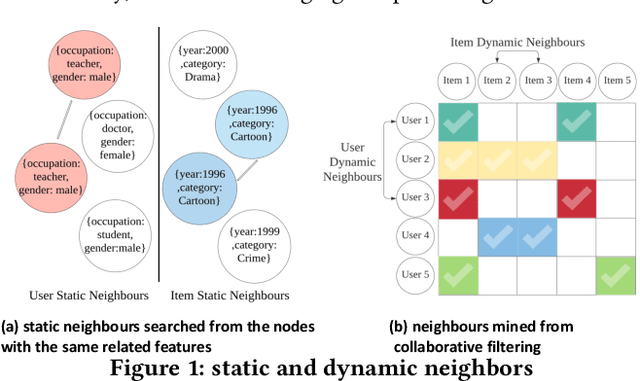
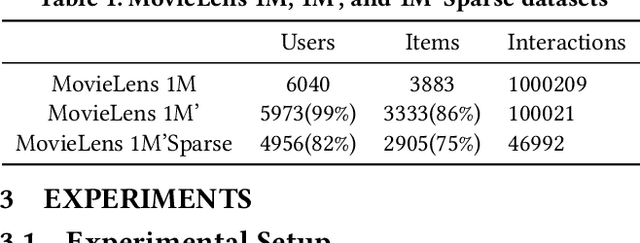
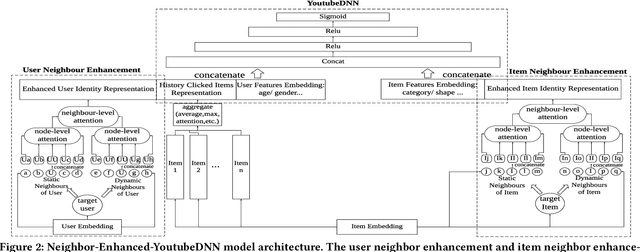
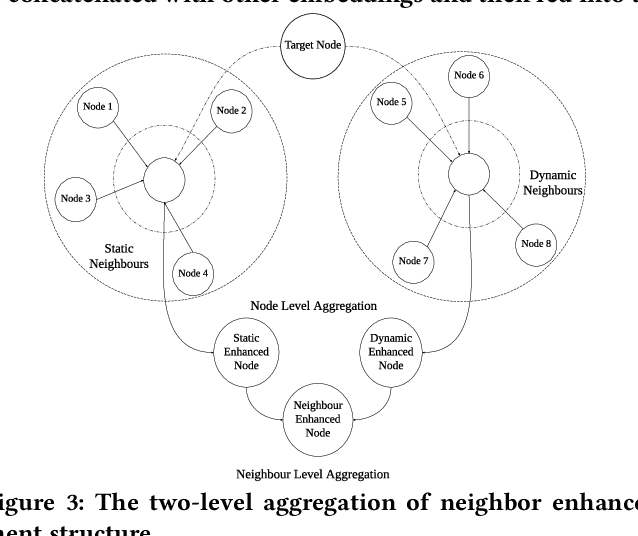
Rank models play a key role in industrial recommender systems, advertising, and search engines. Existing works utilize semantic tags and user-item interaction behaviors, e.g., clicks, views, etc., to predict the user interest and the item hidden representation for estimating the user-item preference score. However, these behavior-tag-based models encounter great challenges and reduced effectiveness when user-item interaction activities are insufficient, which we called "the long-tail ranking problem". Existing rank models ignore this problem, but its common and important because any user or item can be long-tailed once they are not consistently active for a short period. In this paper, we propose a novel neighbor enhancement structure to help train the representation of the target user or item. It takes advantage of similar neighbors (static or dynamic similarity) with multi-level attention operations balancing the weights of different neighbors. Experiments on the well-known public dataset MovieLens 1M demonstrate the efficiency of the method over the baseline behavior-tag-based model with an absolute CTR AUC gain of 0.0259 on the long-tail user dataset.
On Modeling Long-Term User Engagement from Stochastic Feedback
Feb 13, 2023An ultimate goal of recommender systems is to improve user engagement. Reinforcement learning (RL) is a promising paradigm for this goal, as it directly optimizes overall performance of sequential recommendation. However, many existing RL-based approaches induce huge computational overhead, because they require not only the recommended items but also all other candidate items to be stored. This paper proposes an efficient alternative that does not require the candidate items. The idea is to model the correlation between user engagement and items directly from data. Moreover, the proposed approach consider randomness in user feedback and termination behavior, which are ubiquitous for RS but rarely discussed in RL-based prior work. With online A/B experiments on real-world RS, we confirm the efficacy of the proposed approach and the importance of modeling the two types of randomness.
LT4REC:A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System
Aug 22, 2020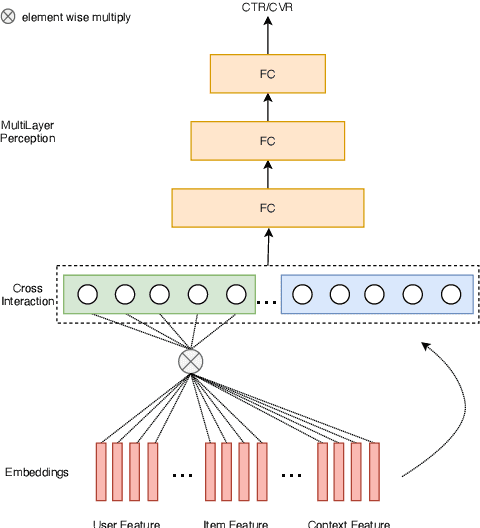

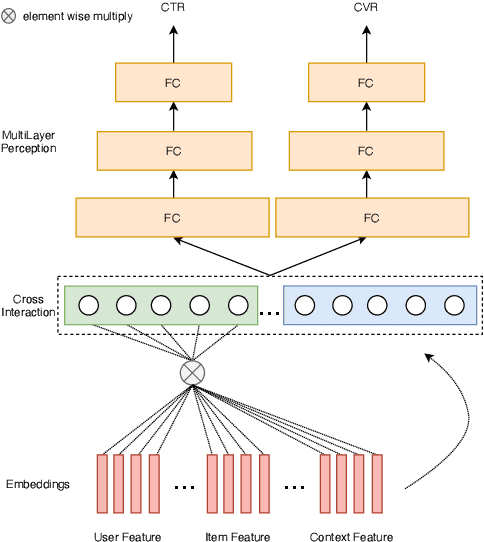
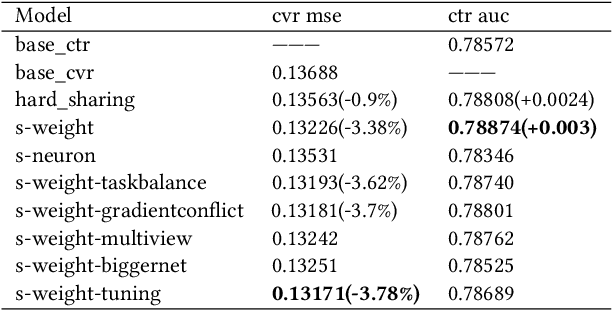
Click-through rate prediction (CTR) and post-click conversion rate prediction (CVR) play key roles across all industrial ranking systems, such as recommendation systems, online advertising, and search engines. Different from the extensive research on CTR, there is much less research on CVR estimation, whose main challenge is extreme data sparsity with one or two orders of magnitude reduction in the number of samples than CTR. People try to solve this problem with the paradigm of multi-task learning with the sufficient samples of CTR, but the typical hard sharing method can't effectively solve this problem, because it is difficult to analyze which parts of network components can be shared and which parts are in conflict, i.e., there is a large inaccuracy with artificially designed neurons sharing. In this paper, we model CVR in a brand-new method by adopting the lottery-ticket-hypothesis-based sparse sharing multi-task learning, which can automatically and flexibly learn which neuron weights to be shared without artificial experience. Experiments on the dataset gathered from traffic logs of Tencent video's recommendation system demonstrate that sparse sharing in the CVR model significantly outperforms competitive methods. Due to the nature of weight sparsity in sparse sharing, it can also significantly reduce computational complexity and memory usage which are very important in the industrial recommendation system.