 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLRQ: Faster LLM Quantization with Flexible Low-Rank Matrix Sketching
Jan 09, 2026Traditional post-training quantization (PTQ) is considered an effective approach to reduce model size and accelerate inference of large-scale language models (LLMs). However, existing low-rank PTQ methods require costly fine-tuning to determine a compromise rank for diverse data and layers in large models, failing to exploit their full potential. Additionally, the current SVD-based low-rank approximation compounds the computational overhead. In this work, we thoroughly analyze the varying effectiveness of low-rank approximation across different layers in representative models. Accordingly, we introduce \underline{F}lexible \underline{L}ow-\underline{R}ank \underline{Q}uantization (FLRQ), a novel solution designed to quickly identify the accuracy-optimal ranks and aggregate them to achieve minimal storage combinations. FLRQ comprises two powerful components, Rank1-Sketch-based Flexible Rank Selection (R1-FLR) and Best Low-rank Approximation under Clipping (BLC). R1-FLR applies the R1-Sketch with Gaussian projection for the fast low-rank approximation, enabling outlier-aware rank extraction for each layer. Meanwhile, BLC aims at minimizing the low-rank quantization error under the scaling and clipping strategy through an iterative method. FLRQ demonstrates strong effectiveness and robustness in comprehensive experiments, achieving state-of-the-art performance in both quantization quality and algorithm efficiency.
Factorization-in-Loop: Proximal Fill-in Minimization for Sparse Matrix Reordering
Nov 12, 2025Fill-ins are new nonzero elements in the summation of the upper and lower triangular factors generated during LU factorization. For large sparse matrices, they will increase the memory usage and computational time, and be reduced through proper row or column arrangement, namely matrix reordering. Finding a row or column permutation with the minimal fill-ins is NP-hard, and surrogate objectives are designed to derive fill-in reduction permutations or learn a reordering function. However, there is no theoretical guarantee between the golden criterion and these surrogate objectives. Here we propose to learn a reordering network by minimizing \(l_1\) norm of triangular factors of the reordered matrix to approximate the exact number of fill-ins. The reordering network utilizes a graph encoder to predict row or column node scores. For inference, it is easy and fast to derive the permutation from sorting algorithms for matrices. For gradient based optimization, there is a large gap between the predicted node scores and resultant triangular factors in the optimization objective. To bridge the gap, we first design two reparameterization techniques to obtain the permutation matrix from node scores. The matrix is reordered by multiplying the permutation matrix. Then we introduce the factorization process into the objective function to arrive at target triangular factors. The overall objective function is optimized with the alternating direction method of multipliers and proximal gradient descent. Experimental results on benchmark sparse matrix collection SuiteSparse show the fill-in number and LU factorization time reduction of our proposed method is 20% and 17.8% compared with state-of-the-art baselines.
Social4Rec: Distilling User Preference from Social Graph for Video Recommendation in Tencent
Feb 23, 2023Despite recommender systems play a key role in network content platforms, mining the user's interests is still a significant challenge. Existing works predict the user interest by utilizing user behaviors, i.e., clicks, views, etc., but current solutions are ineffective when users perform unsettled activities. The latter ones involve new users, which have few activities of any kind, and sparse users who have low-frequency behaviors. We uniformly describe both these user-types as "cold users", which are very common but often neglected in network content platforms. To address this issue, we enhance the representation of the user interest by combining his social interest, e.g., friendship, following bloggers, interest groups, etc., with the activity behaviors. Thus, in this work, we present a novel algorithm entitled SocialNet, which adopts a two-stage method to progressively extract the coarse-grained and fine-grained social interest. Our technique then concatenates SocialNet's output with the original user representation to get the final user representation that combines behavior interests and social interests. Offline experiments on Tencent video's recommender system demonstrate the superiority over the baseline behavior-based model. The online experiment also shows a significant performance improvement in clicks and view time in the real-world recommendation system. The source code is available at https://github.com/Social4Rec/SocialNet.
Incorporating Explicit Knowledge in Pre-trained Language Models for Passage Re-ranking
Apr 25, 2022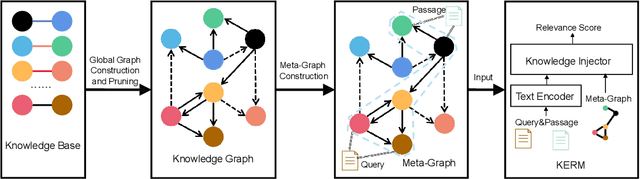

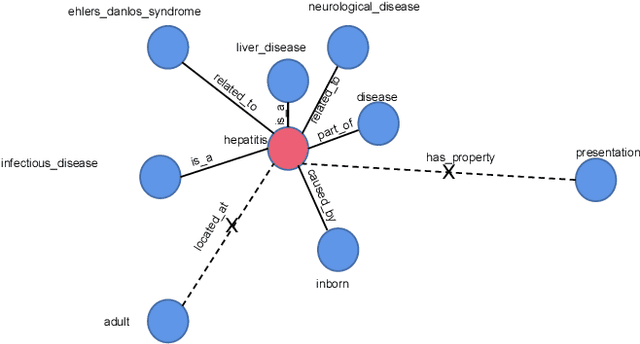
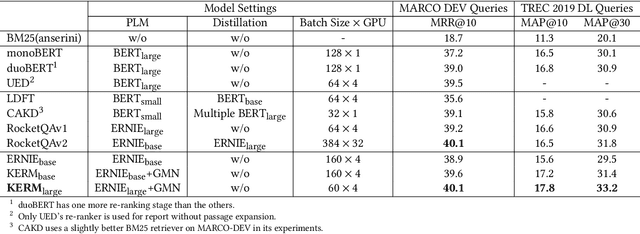
Passage re-ranking is to obtain a permutation over the candidate passage set from retrieval stage. Re-rankers have been boomed by Pre-trained Language Models (PLMs) due to their overwhelming advantages in natural language understanding. However, existing PLM based re-rankers may easily suffer from vocabulary mismatch and lack of domain specific knowledge. To alleviate these problems, explicit knowledge contained in knowledge graph is carefully introduced in our work. Specifically, we employ the existing knowledge graph which is incomplete and noisy, and first apply it in passage re-ranking task. To leverage a reliable knowledge, we propose a novel knowledge graph distillation method and obtain a knowledge meta graph as the bridge between query and passage. To align both kinds of embedding in the latent space, we employ PLM as text encoder and graph neural network over knowledge meta graph as knowledge encoder. Besides, a novel knowledge injector is designed for the dynamic interaction between text and knowledge encoder. Experimental results demonstrate the effectiveness of our method especially in queries requiring in-depth domain knowledge.
Improving Variational Encoder-Decoders in Dialogue Generation
Feb 06, 2018

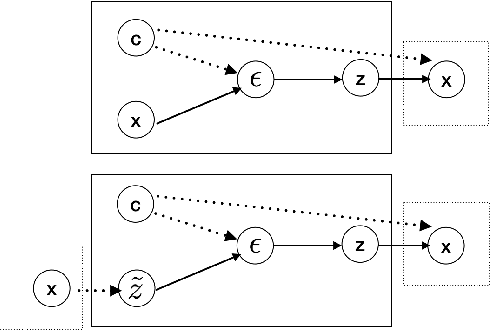

Variational encoder-decoders (VEDs) have shown promising results in dialogue generation. However, the latent variable distributions are usually approximated by a much simpler model than the powerful RNN structure used for encoding and decoding, yielding the KL-vanishing problem and inconsistent training objective. In this paper, we separate the training step into two phases: The first phase learns to autoencode discrete texts into continuous embeddings, from which the second phase learns to generalize latent representations by reconstructing the encoded embedding. In this case, latent variables are sampled by transforming Gaussian noise through multi-layer perceptrons and are trained with a separate VED model, which has the potential of realizing a much more flexible distribution. We compare our model with current popular models and the experiment demonstrates substantial improvement in both metric-based and human evaluations.
DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset
Oct 11, 2017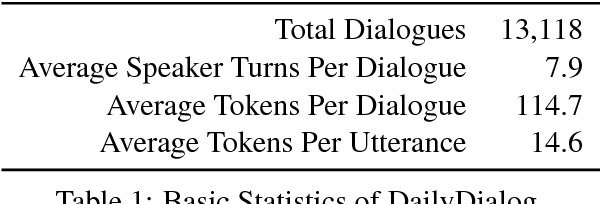
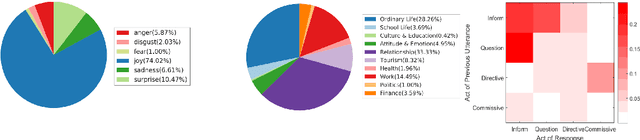


We develop a high-quality multi-turn dialog dataset, DailyDialog, which is intriguing in several aspects. The language is human-written and less noisy. The dialogues in the dataset reflect our daily communication way and cover various topics about our daily life. We also manually label the developed dataset with communication intention and emotion information. Then, we evaluate existing approaches on DailyDialog dataset and hope it benefit the research field of dialog systems.
A Conditional Variational Framework for Dialog Generation
Jul 06, 2017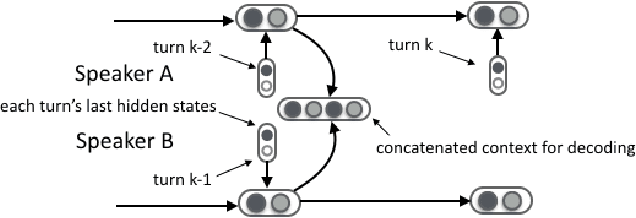
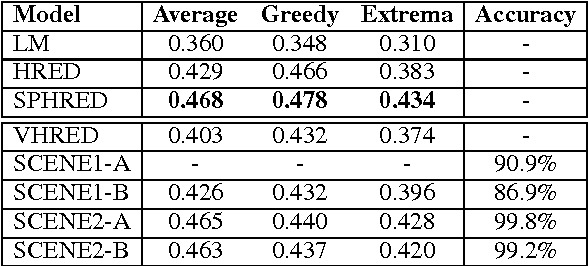
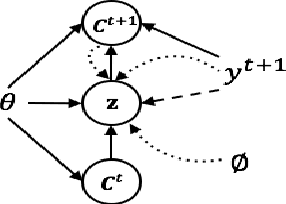

Deep latent variable models have been shown to facilitate the response generation for open-domain dialog systems. However, these latent variables are highly randomized, leading to uncontrollable generated responses. In this paper, we propose a framework allowing conditional response generation based on specific attributes. These attributes can be either manually assigned or automatically detected. Moreover, the dialog states for both speakers are modeled separately in order to reflect personal features. We validate this framework on two different scenarios, where the attribute refers to genericness and sentiment states respectively. The experiment result testified the potential of our model, where meaningful responses can be generated in accordance with the specified attributes.
Stochastic Rank Aggregation
Sep 26, 2013
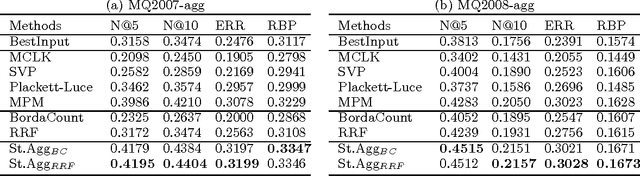


This paper addresses the problem of rank aggregation, which aims to find a consensus ranking among multiple ranking inputs. Traditional rank aggregation methods are deterministic, and can be categorized into explicit and implicit methods depending on whether rank information is explicitly or implicitly utilized. Surprisingly, experimental results on real data sets show that explicit rank aggregation methods would not work as well as implicit methods, although rank information is critical for the task. Our analysis indicates that the major reason might be the unreliable rank information from incomplete ranking inputs. To solve this problem, we propose to incorporate uncertainty into rank aggregation and tackle the problem in both unsupervised and supervised scenario. We call this novel framework {stochastic rank aggregation} (St.Agg for short). Specifically, we introduce a prior distribution on ranks, and transform the ranking functions or objectives in traditional explicit methods to their expectations over this distribution. Our experiments on benchmark data sets show that the proposed St.Agg outperforms the baselines in both unsupervised and supervised scenarios.