 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT4REC:A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System
Paper and Code
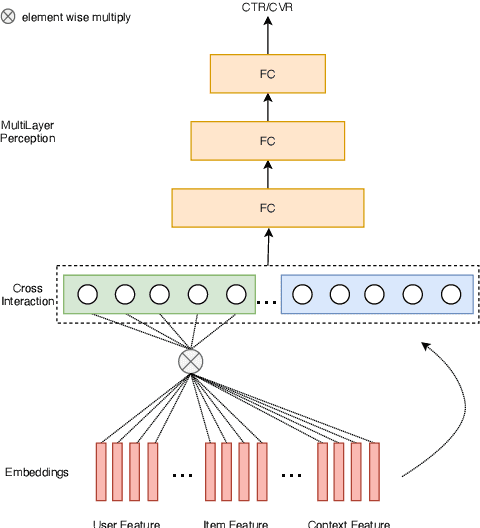

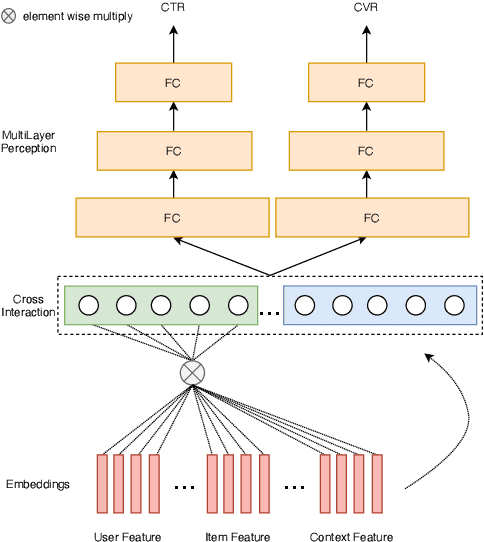
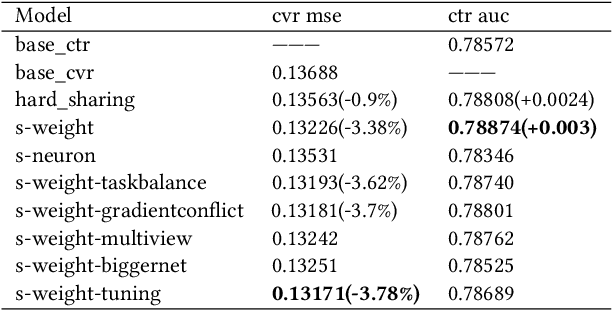
Click-through rate prediction (CTR) and post-click conversion rate prediction (CVR) play key roles across all industrial ranking systems, such as recommendation systems, online advertising, and search engines. Different from the extensive research on CTR, there is much less research on CVR estimation, whose main challenge is extreme data sparsity with one or two orders of magnitude reduction in the number of samples than CTR. People try to solve this problem with the paradigm of multi-task learning with the sufficient samples of CTR, but the typical hard sharing method can't effectively solve this problem, because it is difficult to analyze which parts of network components can be shared and which parts are in conflict, i.e., there is a large inaccuracy with artificially designed neurons sharing. In this paper, we model CVR in a brand-new method by adopting the lottery-ticket-hypothesis-based sparse sharing multi-task learning, which can automatically and flexibly learn which neuron weights to be shared without artificial experience. Experiments on the dataset gathered from traffic logs of Tencent video's recommendation system demonstrate that sparse sharing in the CVR model significantly outperforms competitive methods. Due to the nature of weight sparsity in sparse sharing, it can also significantly reduce computational complexity and memory usage which are very important in the industrial recommendation system.