 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Report for CCL25-Eval Task 10: SRAG-MAV for Fine-Grained Chinese Hate Speech Recognition
Jul 24, 2025This paper presents our system for CCL25-Eval Task 10, addressing Fine-Grained Chinese Hate Speech Recognition (FGCHSR). We propose a novel SRAG-MAV framework that synergistically integrates task reformulation(TR), Self-Retrieval-Augmented Generation (SRAG), and Multi-Round Accumulative Voting (MAV). Our method reformulates the quadruplet extraction task into triplet extraction, uses dynamic retrieval from the training set to create contextual prompts, and applies multi-round inference with voting to improve output stability and performance. Our system, based on the Qwen2.5-7B model, achieves a Hard Score of 26.66, a Soft Score of 48.35, and an Average Score of 37.505 on the STATE ToxiCN dataset, significantly outperforming baselines such as GPT-4o (Average Score 15.63) and fine-tuned Qwen2.5-7B (Average Score 35.365). The code is available at https://github.com/king-wang123/CCL25-SRAG-MAV.
Information fusion strategy integrating pre-trained language model and contrastive learning for materials knowledge mining
Jun 14, 2025Machine learning has revolutionized materials design, yet predicting complex properties like alloy ductility remains challenging due to the influence of processing conditions and microstructural features that resist quantification through traditional reductionist approaches. Here, we present an innovative information fusion architecture that integrates domain-specific texts from materials science literature with quantitative physical descriptors to overcome these limitations. Our framework employs MatSciBERT for advanced textual comprehension and incorporates contrastive learning to automatically extract implicit knowledge regarding processing parameters and microstructural characteristics. Through rigorous ablation studies and comparative experiments, the model demonstrates superior performance, achieving coefficient of determination (R2) values of 0.849 and 0.680 on titanium alloy validation set and refractory multi-principal-element alloy test set. This systematic approach provides a holistic framework for property prediction in complex material systems where quantitative descriptors are incomplete and establishes a foundation for knowledge-guided materials design and informatics-driven materials discovery.
Chinese Sequence Labeling with Semi-Supervised Boundary-Aware Language Model Pre-training
Apr 08, 2024



Chinese sequence labeling tasks are heavily reliant on accurate word boundary demarcation. Although current pre-trained language models (PLMs) have achieved substantial gains on these tasks, they rarely explicitly incorporate boundary information into the modeling process. An exception to this is BABERT, which incorporates unsupervised statistical boundary information into Chinese BERT's pre-training objectives. Building upon this approach, we input supervised high-quality boundary information to enhance BABERT's learning, developing a semi-supervised boundary-aware PLM. To assess PLMs' ability to encode boundaries, we introduce a novel ``Boundary Information Metric'' that is both simple and effective. This metric allows comparison of different PLMs without task-specific fine-tuning. Experimental results on Chinese sequence labeling datasets demonstrate that the improved BABERT variant outperforms the vanilla version, not only on these tasks but also more broadly across a range of Chinese natural language understanding tasks. Additionally, our proposed metric offers a convenient and accurate means of evaluating PLMs' boundary awareness.
RankingGPT: Empowering Large Language Models in Text Ranking with Progressive Enhancement
Nov 28, 2023



Text ranking is a critical task in various information retrieval applications, and the recent success of Large Language Models (LLMs) in natural language processing has sparked interest in their application to text ranking. These methods primarily involve combining query and candidate documents and leveraging prompt learning to determine query-document relevance using the LLM's output probabilities for specific tokens or by directly generating a ranked list of candidate documents. Although these approaches have demonstrated promise, a noteworthy disparity arises between the training objective of LLMs, which typically centers around next token prediction, and the objective of evaluating query-document relevance. To address this gap and fully leverage LLM potential in text ranking tasks, we propose a progressive multi-stage training strategy. Firstly, we introduce a large-scale weakly supervised dataset of relevance texts to enable the LLMs to acquire the ability to predict relevant tokens without altering their original training objective. Subsequently, we incorporate supervised training to further enhance LLM ranking capability. Our experimental results on multiple benchmarks demonstrate the superior performance of our proposed method compared to previous competitive approaches, both in in-domain and out-of-domain scenarios.
Hybrid Retrieval and Multi-stage Text Ranking Solution at TREC 2022 Deep Learning Track
Aug 23, 2023



Large-scale text retrieval technology has been widely used in various practical business scenarios. This paper presents our systems for the TREC 2022 Deep Learning Track. We explain the hybrid text retrieval and multi-stage text ranking method adopted in our solution. The retrieval stage combined the two structures of traditional sparse retrieval and neural dense retrieval. In the ranking stage, in addition to the full interaction-based ranking model built on large pre-trained language model, we also proposes a lightweight sub-ranking module to further enhance the final text ranking performance. Evaluation results demonstrate the effectiveness of our proposed approach. Our models achieve the 1st and 4th rank on the test set of passage ranking and document ranking respectively.
A Simple but Effective Bidirectional Framework for Relational Triple Extraction
Jan 05, 2022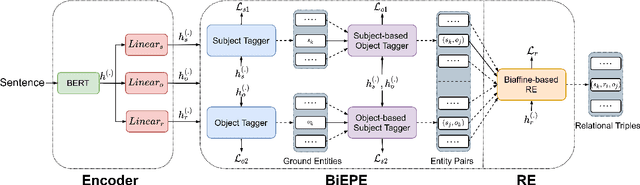
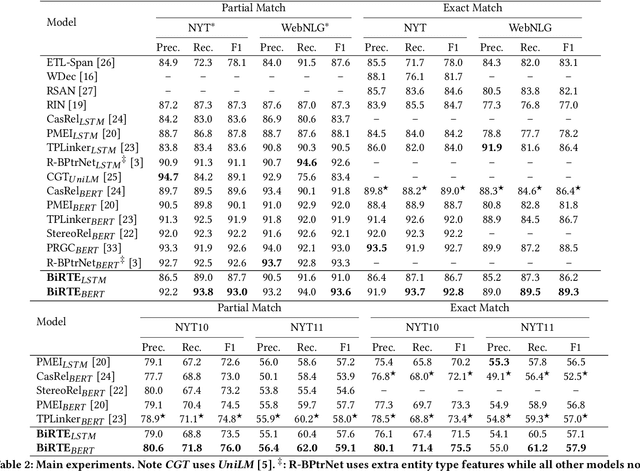
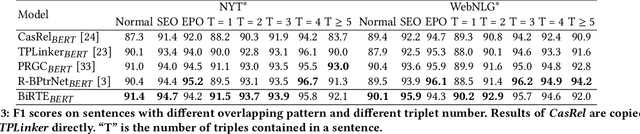
Tagging based relational triple extraction methods are attracting growing research attention recently. However, most of these methods take a unidirectional extraction framework that first extracts all subjects and then extracts objects and relations simultaneously based on the subjects extracted. This framework has an obvious deficiency that it is too sensitive to the extraction results of subjects. To overcome this deficiency, we propose a bidirectional extraction framework based method that extracts triples based on the entity pairs extracted from two complementary directions. Concretely, we first extract all possible subject-object pairs from two paralleled directions. These two extraction directions are connected by a shared encoder component, thus the extraction features from one direction can flow to another direction and vice versa. By this way, the extractions of two directions can boost and complement each other. Next, we assign all possible relations for each entity pair by a biaffine model. During training, we observe that the share structure will lead to a convergence rate inconsistency issue which is harmful to performance. So we propose a share-aware learning mechanism to address it. We evaluate the proposed model on multiple benchmark datasets. Extensive experimental results show that the proposed model is very effective and it achieves state-of-the-art results on all of these datasets. Moreover, experiments show that both the proposed bidirectional extraction framework and the share-aware learning mechanism have good adaptability and can be used to improve the performance of other tagging based methods. The source code of our work is available at: https://github.com/neukg/BiRTE.
A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling
Sep 14, 2021Table filling based relational triple extraction methods are attracting growing research interests due to their promising performance and their abilities on extracting triples from complex sentences. However, this kind of methods are far from their full potential because most of them only focus on using local features but ignore the global associations of relations and of token pairs, which increases the possibility of overlooking some important information during triple extraction. To overcome this deficiency, we propose a global feature-oriented triple extraction model that makes full use of the mentioned two kinds of global associations. Specifically, we first generate a table feature for each relation. Then two kinds of global associations are mined from the generated table features. Next, the mined global associations are integrated into the table feature of each relation. This "generate-mine-integrate" process is performed multiple times so that the table feature of each relation is refined step by step. Finally, each relation's table is filled based on its refined table feature, and all triples linked to this relation are extracted based on its filled table. We evaluate the proposed model on three benchmark datasets. Experimental results show our model is effective and it achieves state-of-the-art results on all of these datasets. The source code of our work is available at: https://github.com/neukg/GRTE.
A Three-Stage Learning Framework for Low-Resource Knowledge-Grounded Dialogue Generation
Sep 09, 2021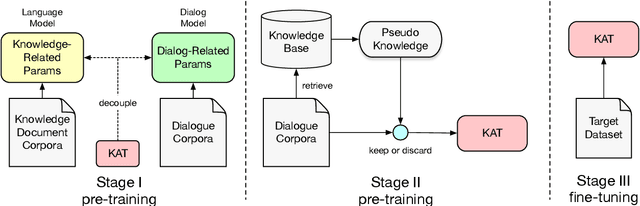
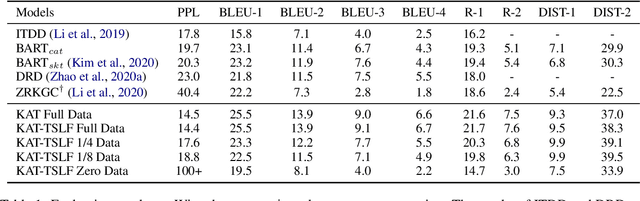
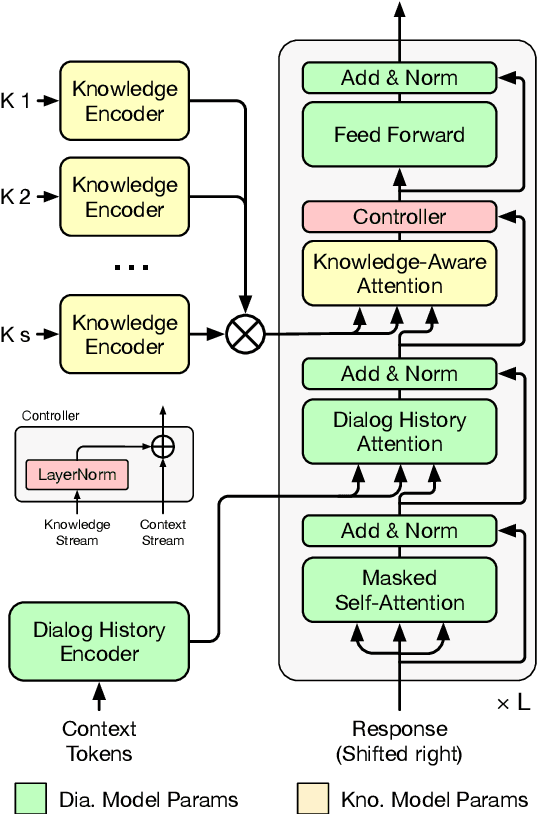
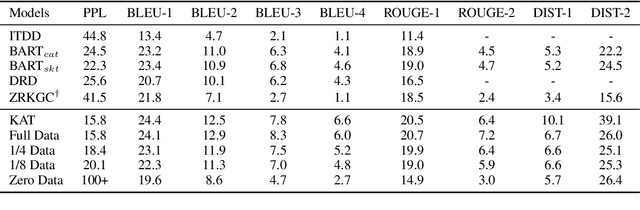
Neural conversation models have shown great potentials towards generating fluent and informative responses by introducing external background knowledge. Nevertheless, it is laborious to construct such knowledge-grounded dialogues, and existing models usually perform poorly when transfer to new domains with limited training samples. Therefore, building a knowledge-grounded dialogue system under the low-resource setting is a still crucial issue. In this paper, we propose a novel three-stage learning framework based on weakly supervised learning which benefits from large scale ungrounded dialogues and unstructured knowledge base. To better cooperate with this framework, we devise a variant of Transformer with decoupled decoder which facilitates the disentangled learning of response generation and knowledge incorporation. Evaluation results on two benchmarks indicate that our approach can outperform other state-of-the-art methods with less training data, and even in zero-resource scenario, our approach still performs well.
A Conditional Cascade Model for Relational Triple Extraction
Aug 20, 2021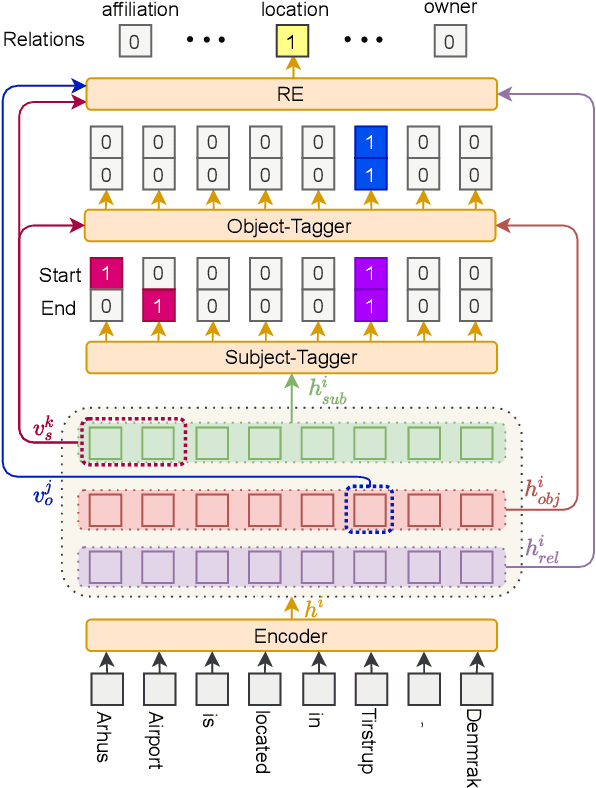
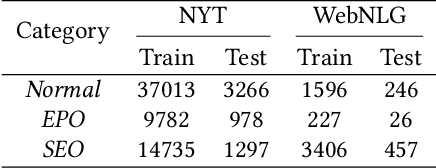
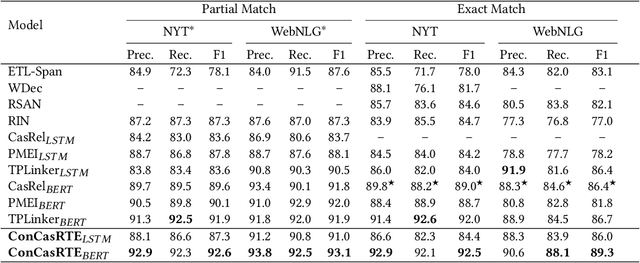

Tagging based methods are one of the mainstream methods in relational triple extraction. However, most of them suffer from the class imbalance issue greatly. Here we propose a novel tagging based model that addresses this issue from following two aspects. First, at the model level, we propose a three-step extraction framework that can reduce the total number of samples greatly, which implicitly decreases the severity of the mentioned issue. Second, at the intra-model level, we propose a confidence threshold based cross entropy loss that can directly neglect some samples in the major classes. We evaluate the proposed model on NYT and WebNLG. Extensive experiments show that it can address the mentioned issue effectively and achieves state-of-the-art results on both datasets. The source code of our model is available at: https://github.com/neukg/ConCasRTE.
An Effective System for Multi-format Information Extraction
Aug 16, 2021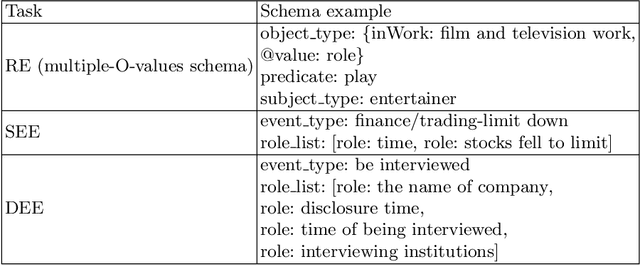
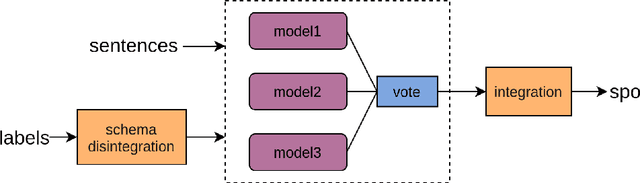
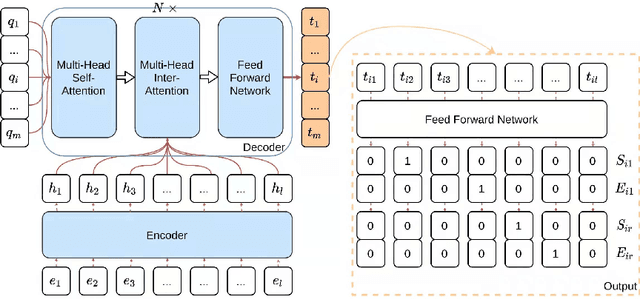

The multi-format information extraction task in the 2021 Language and Intelligence Challenge is designed to comprehensively evaluate information extraction from different dimensions. It consists of an multiple slots relation extraction subtask and two event extraction subtasks that extract events from both sentence-level and document-level. Here we describe our system for this multi-format information extraction competition task. Specifically, for the relation extraction subtask, we convert it to a traditional triple extraction task and design a voting based method that makes full use of existing models. For the sentence-level event extraction subtask, we convert it to a NER task and use a pointer labeling based method for extraction. Furthermore, considering the annotated trigger information may be helpful for event extraction, we design an auxiliary trigger recognition model and use the multi-task learning mechanism to integrate the trigger features into the event extraction model. For the document-level event extraction subtask, we design an Encoder-Decoder based method and propose a Transformer-alike decoder. Finally,our system ranks No.4 on the test set leader-board of this multi-format information extraction task, and its F1 scores for the subtasks of relation extraction, event extractions of sentence-level and document-level are 79.887%, 85.179%, and 70.828% respectively. The codes of our model are available at {https://github.com/neukg/MultiIE}.