 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust MIMO Semantic Communication with Imperfect CSI via Knowledge Distillation
Sep 04, 2025Semantic communication (SemComm) has emerged as a new communication paradigm. To enhance efficiency, multiple-input-multiple-output (MIMO) technology has been further integrated into SemComm systems. However, existing MIMO SemComm systems assume perfect channel matrix estimation for channel-adaptive joint source-channel coding, which is impractical due to hardware and pilot overhead constraints. In this paper, we propose a semantic image transmission system with channel matrix and channel noise adaptation, named HANA-JSCC, to cope with channel estimation errors in MIMO systems. We propose a channel matrix adaptor that collaborates with the channel codec to adapt to misaligned channel state information, thereby mitigating the impact of estimation errors. Since the relationship between the estimated channel matrix and true channel matrix is ill-posed (one-to-many), we further introduce a two-stage training strategy with knowledge distillation to overcome the convergence difficulties caused by the ill-posed problem. Comparing with the state-of-the-art benchmarks, HANA-JSCC achieves $0.40\sim0.54$dB higher average performance across various noise and estimation error levels in various datasets.
Confidence-Aware Multi-Field Model Calibration
Feb 27, 2024



Accurately predicting the probabilities of user feedback, such as clicks and conversions, is critical for ad ranking and bidding. However, there often exist unwanted mismatches between predicted probabilities and true likelihoods due to the shift of data distributions and intrinsic model biases. Calibration aims to address this issue by post-processing model predictions, and field-aware calibration can adjust model output on different feature field values to satisfy fine-grained advertising demands. Unfortunately, the observed samples corresponding to certain field values can be too limited to make confident calibrations, which may yield bias amplification and online disturbance. In this paper, we propose a confidence-aware multi-field calibration method, which adaptively adjusts the calibration intensity based on the confidence levels derived from sample statistics. It also utilizes multiple feature fields for joint model calibration with awareness of their importance to mitigate the data sparsity effect of a single field. Extensive offline and online experiments show the superiority of our method in boosting advertising performance and reducing prediction deviations.
Differentially Private Over-the-Air Federated Learning Over MIMO Fading Channels
Jun 19, 2023



Federated learning (FL) enables edge devices to collaboratively train machine learning models, with model communication replacing direct data uploading. While over-the-air model aggregation improves communication efficiency, uploading models to an edge server over wireless networks can pose privacy risks. Differential privacy (DP) is a widely used quantitative technique to measure statistical data privacy in FL. Previous research has focused on over-the-air FL with a single-antenna server, leveraging communication noise to enhance user-level DP. This approach achieves the so-called "free DP" by controlling transmit power rather than introducing additional DP-preserving mechanisms at devices, such as adding artificial noise. In this paper, we study differentially private over-the-air FL over a multiple-input multiple-output (MIMO) fading channel. We show that FL model communication with a multiple-antenna server amplifies privacy leakage as the multiple-antenna server employs separate receive combining for model aggregation and information inference. Consequently, relying solely on communication noise, as done in the multiple-input single-output system, cannot meet high privacy requirements, and a device-side privacy-preserving mechanism is necessary for optimal DP design. We analyze the learning convergence and privacy loss of the studied FL system and propose a transceiver design algorithm based on alternating optimization. Numerical results demonstrate that the proposed method achieves a better privacy-learning trade-off compared to prior work.
TDACNN: Target-domain-free Domain Adaptation Convolutional Neural Network for Drift Compensation in Gas Sensors
Oct 15, 2021
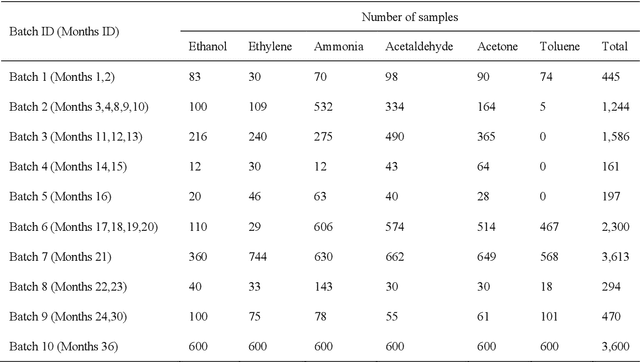
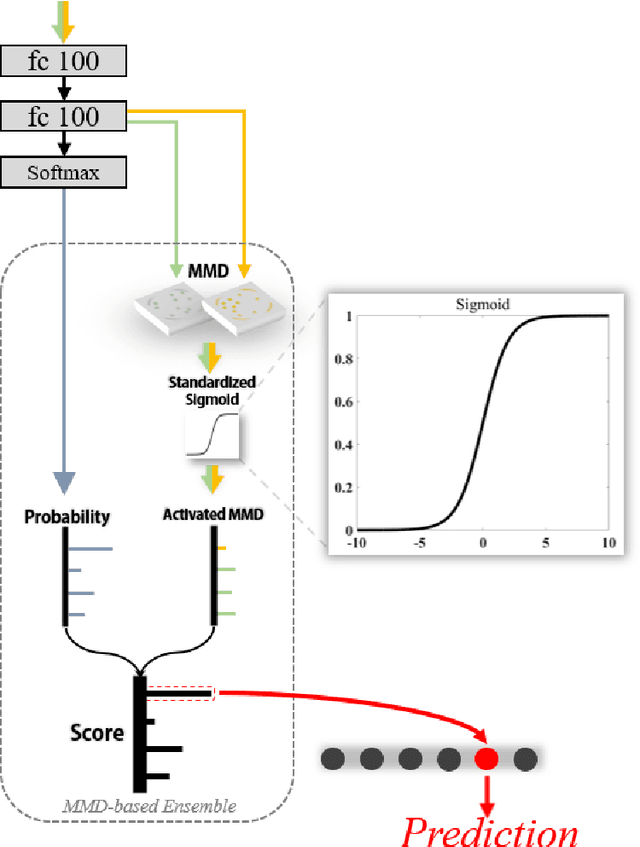

Sensor drift is a long-existing unpredictable problem that deteriorates the performance of gaseous substance recognition, calling for an antidrift domain adaptation algorithm. However, the prerequisite for traditional methods to achieve fine results is to have data from both nondrift distributions (source domain) and drift distributions (target domain) for domain alignment, which is usually unrealistic and unachievable in real-life scenarios. To compensate for this, in this paper, deep learning based on a target-domain-free domain adaptation convolutional neural network (TDACNN) is proposed. The main concept is that CNNs extract not only the domain-specific features of samples but also the domain-invariant features underlying both the source and target domains. Making full use of these various levels of embedding features can lead to comprehensive utilization of different levels of characteristics, thus achieving drift compensation by the extracted intermediate features between two domains. In the TDACNN, a flexible multibranch backbone with a multiclassifier structure is proposed under the guidance of bionics, which utilizes multiple embedding features comprehensively without involving target domain data during training. A classifier ensemble method based on maximum mean discrepancy (MMD) is proposed to evaluate all the classifiers jointly based on the credibility of the pseudolabel. To optimize network training, an additive angular margin softmax loss with parameter dynamic adjustment is utilized. Experiments on two drift datasets under different settings demonstrate the superiority of TDACNN compared with several state-of-the-art methods.
A framework for massive scale personalized promotion
Aug 27, 2021

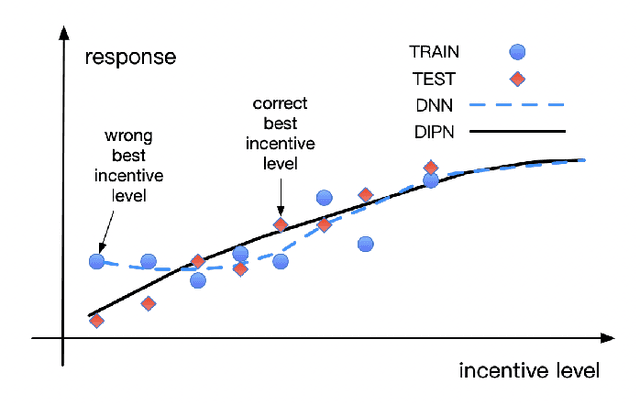
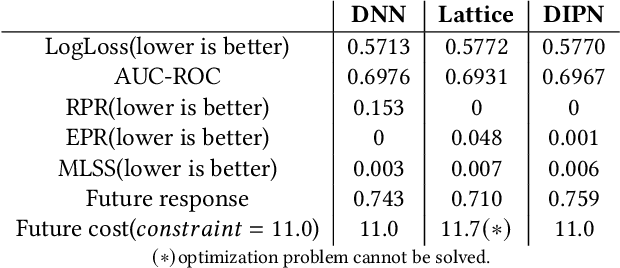
Technology companies building consumer-facing platforms may have access to massive-scale user population. In recent years, promotion with quantifiable incentive has become a popular approach for increasing active users on such platforms. On one hand, increased user activities can introduce network effect, bring in advertisement audience, and produce other benefits. On the other hand, massive-scale promotion causes massive cost. Therefore making promotion campaigns efficient in terms of return-on-investment (ROI) is of great interest to many companies. This paper proposes a practical two-stage framework that can optimize the ROI of various massive-scale promotion campaigns. In the first stage, users' personal promotion-response curves are modeled by machine learning techniques. In the second stage, business objectives and resource constraints are formulated into an optimization problem, the decision variables of which are how much incentive to give to each user. In order to do effective optimization in the second stage, counterfactual prediction and noise-reduction are essential for the first stage. We leverage existing counterfactual prediction techniques to correct treatment bias in data. We also introduce a novel deep neural network (DNN) architecture, the deep-isotonic-promotion-network (DIPN), to reduce noise in the promotion response curves. The DIPN architecture incorporates our prior knowledge of response curve shape, by enforcing isotonicity and smoothness. It out-performed regular DNN and other state-of-the-art shape-constrained models in our experiments.
Optimal Model Placement and Online Model Splitting for Device-Edge Co-Inference
May 28, 2021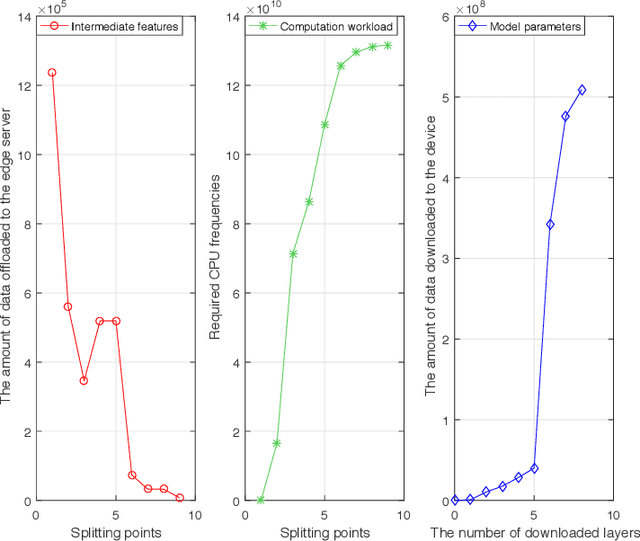
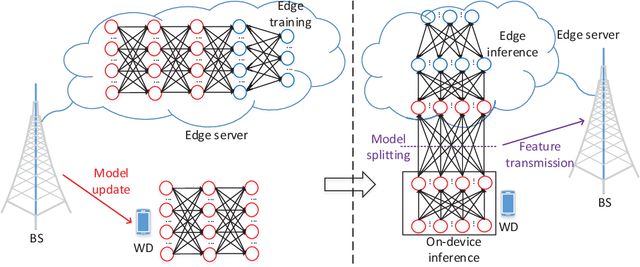
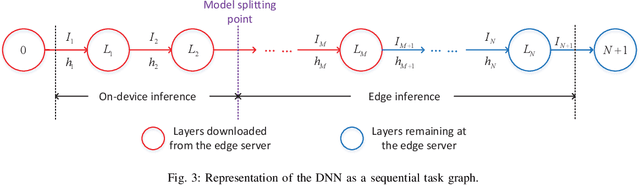
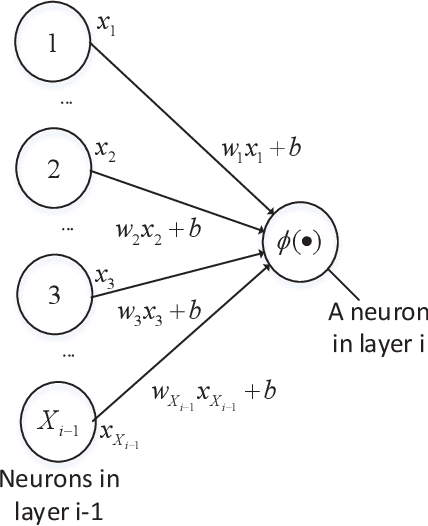
Device-edge co-inference opens up new possibilities for resource-constrained wireless devices (WDs) to execute deep neural network (DNN)-based applications with heavy computation workloads. In particular, the WD executes the first few layers of the DNN and sends the intermediate features to the edge server that processes the remaining layers of the DNN. By adapting the model splitting decision, there exists a tradeoff between local computation cost and communication overhead. In practice, the DNN model is re-trained and updated periodically at the edge server. Once the DNN parameters are regenerated, part of the updated model must be placed at the WD to facilitate on-device inference. In this paper, we study the joint optimization of the model placement and online model splitting decisions to minimize the energy-and-time cost of device-edge co-inference in presence of wireless channel fading. The problem is challenging because the model placement and model splitting decisions are strongly coupled, while involving two different time scales. We first tackle online model splitting by formulating an optimal stopping problem, where the finite horizon of the problem is determined by the model placement decision. In addition to deriving the optimal model splitting rule based on backward induction, we further investigate a simple one-stage look-ahead rule, for which we are able to obtain analytical expressions of the model splitting decision. The analysis is useful for us to efficiently optimize the model placement decision in a larger time scale. In particular, we obtain a closed-form model placement solution for the fully-connected multilayer perceptron with equal neurons. Simulation results validate the superior performance of the joint optimal model placement and splitting with various DNN structures.
Blind Image Quality Assessment Using A Deep Bilinear Convolutional Neural Network
Jul 05, 2019


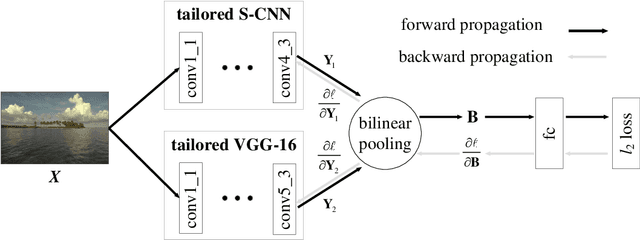
We propose a deep bilinear model for blind image quality assessment (BIQA) that handles both synthetic and authentic distortions. Our model consists of two convolutional neural networks (CNN), each of which specializes in one distortion scenario. For synthetic distortions, we pre-train a CNN to classify image distortion type and level, where we enjoy large-scale training data. For authentic distortions, we adopt a pre-trained CNN for image classification. The features from the two CNNs are pooled bilinearly into a unified representation for final quality prediction. We then fine-tune the entire model on target subject-rated databases using a variant of stochastic gradient descent. Extensive experiments demonstrate that the proposed model achieves superior performance on both synthetic and authentic databases. Furthermore, we verify the generalizability of our method on the Waterloo Exploration Database using the group maximum differentiation competition.
No-Reference Quality Assessment of Contrast-Distorted Images using Contrast Enhancement
Apr 18, 2019



No-reference image quality assessment (NR-IQA) aims to measure the image quality without reference image. However, contrast distortion has been overlooked in the current research of NR-IQA. In this paper, we propose a very simple but effective metric for predicting quality of contrast-altered images based on the fact that a high-contrast image is often more similar to its contrast enhanced image. Specifically, we first generate an enhanced image through histogram equalization. We then calculate the similarity of the original image and the enhanced one by using structural-similarity index (SSIM) as the first feature. Further, we calculate the histogram based entropy and cross entropy between the original image and the enhanced one respectively, to gain a sum of 4 features. Finally, we learn a regression module to fuse the aforementioned 5 features for inferring the quality score. Experiments on four publicly available databases validate the superiority and efficiency of the proposed technique.
Image Aesthetics Assessment Using Composite Features from off-the-Shelf Deep Models
Feb 22, 2019
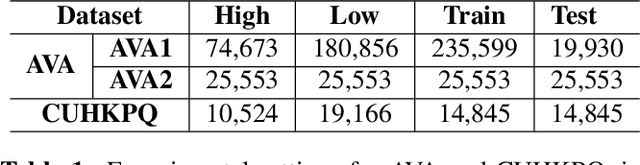
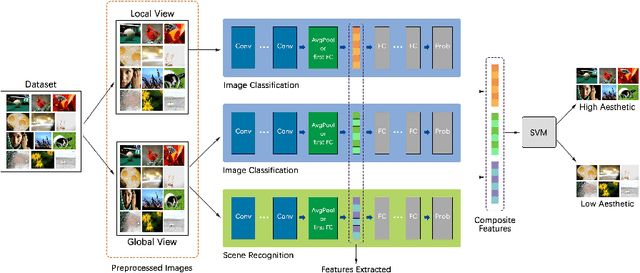
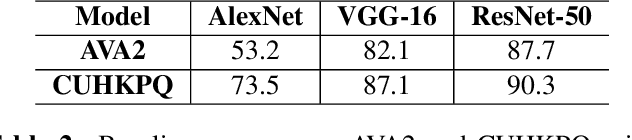
Deep convolutional neural networks have recently achieved great success on image aesthetics assessment task. In this paper, we propose an efficient method which takes the global, local and scene-aware information of images into consideration and exploits the composite features extracted from corresponding pretrained deep learning models to classify the derived features with support vector machine. Contrary to popular methods that require fine-tuning or training a new model from scratch, our training-free method directly takes the deep features generated by off-the-shelf models for image classification and scene recognition. Also, we analyzed the factors that could influence the performance from two aspects: the architecture of the deep neural network and the contribution of local and scene-aware information. It turns out that deep residual network could produce more aesthetics-aware image representation and composite features lead to the improvement of overall performance. Experiments on common large-scale aesthetics assessment benchmarks demonstrate that our method outperforms the state-of-the-art results in photo aesthetics assessment.