 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuitoBench: A High-Quality Open Time Series Forecasting Benchmark
Mar 27, 2026Time series forecasting is critical across finance, healthcare, and cloud computing, yet progress is constrained by a fundamental bottleneck: the scarcity of large-scale, high-quality benchmarks. To address this gap, we introduce \textsc{QuitoBench}, a regime-balanced benchmark for time series forecasting with coverage across eight trend$\times$seasonality$\times$forecastability (TSF) regimes, designed to capture forecasting-relevant properties rather than application-defined domain labels. The benchmark is built upon \textsc{Quito}, a billion-scale time series corpus of application traffic from Alipay spanning nine business domains. Benchmarking 10 models from deep learning, foundation models, and statistical baselines across 232,200 evaluation instances, we report four key findings: (i) a context-length crossover where deep learning models lead at short context ($L=96$) but foundation models dominate at long context ($L \ge 576$); (ii) forecastability is the dominant difficulty driver, producing a $3.64 \times$ MAE gap across regimes; (iii) deep learning models match or surpass foundation models at $59 \times$ fewer parameters; and (iv) scaling the amount of training data provides substantially greater benefit than scaling model size for both model families. These findings are validated by strong cross-benchmark and cross-metric consistency. Our open-source release enables reproducible, regime-aware evaluation for time series forecasting research.
A framework for massive scale personalized promotion
Aug 27, 2021

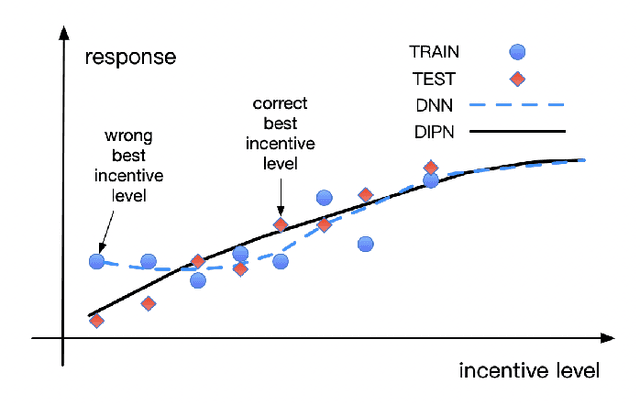
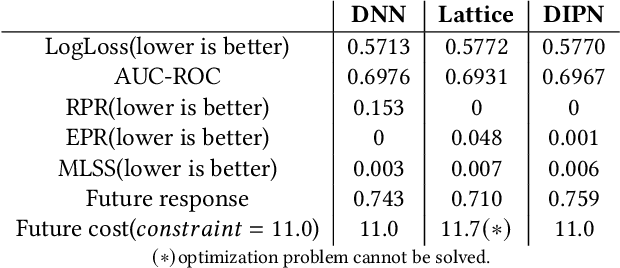
Technology companies building consumer-facing platforms may have access to massive-scale user population. In recent years, promotion with quantifiable incentive has become a popular approach for increasing active users on such platforms. On one hand, increased user activities can introduce network effect, bring in advertisement audience, and produce other benefits. On the other hand, massive-scale promotion causes massive cost. Therefore making promotion campaigns efficient in terms of return-on-investment (ROI) is of great interest to many companies. This paper proposes a practical two-stage framework that can optimize the ROI of various massive-scale promotion campaigns. In the first stage, users' personal promotion-response curves are modeled by machine learning techniques. In the second stage, business objectives and resource constraints are formulated into an optimization problem, the decision variables of which are how much incentive to give to each user. In order to do effective optimization in the second stage, counterfactual prediction and noise-reduction are essential for the first stage. We leverage existing counterfactual prediction techniques to correct treatment bias in data. We also introduce a novel deep neural network (DNN) architecture, the deep-isotonic-promotion-network (DIPN), to reduce noise in the promotion response curves. The DIPN architecture incorporates our prior knowledge of response curve shape, by enforcing isotonicity and smoothness. It out-performed regular DNN and other state-of-the-art shape-constrained models in our experiments.
Adaptive Optimizers with Sparse Group Lasso for Neural Networks in CTR Prediction
Jul 30, 2021
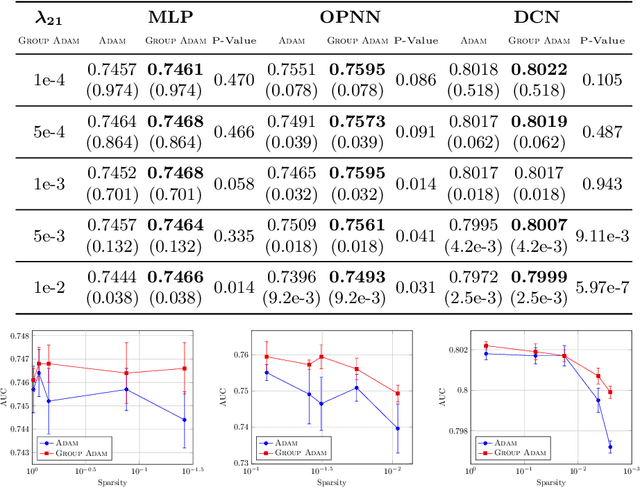
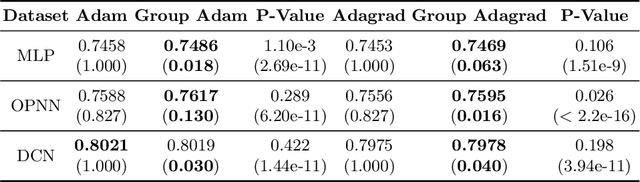
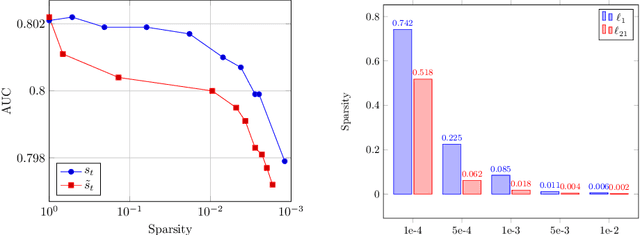
We develop a novel framework that adds the regularizers of the sparse group lasso to a family of adaptive optimizers in deep learning, such as Momentum, Adagrad, Adam, AMSGrad, AdaHessian, and create a new class of optimizers, which are named Group Momentum, Group Adagrad, Group Adam, Group AMSGrad and Group AdaHessian, etc., accordingly. We establish theoretically proven convergence guarantees in the stochastic convex settings, based on primal-dual methods. We evaluate the regularized effect of our new optimizers on three large-scale real-world ad click datasets with state-of-the-art deep learning models. The experimental results reveal that compared with the original optimizers with the post-processing procedure which uses the magnitude pruning method, the performance of the models can be significantly improved on the same sparsity level. Furthermore, in comparison to the cases without magnitude pruning, our methods can achieve extremely high sparsity with significantly better or highly competitive performance.