 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTDrive: Multi-turn Interactive Reinforcement Learning for Autonomous Driving
Jan 30, 2026Trajectory planning is a core task in autonomous driving, requiring the prediction of safe and comfortable paths across diverse scenarios. Integrating Multi-modal Large Language Models (MLLMs) with Reinforcement Learning (RL) has shown promise in addressing "long-tail" scenarios. However, existing methods are constrained to single-turn reasoning, limiting their ability to handle complex tasks requiring iterative refinement. To overcome this limitation, we present MTDrive, a multi-turn framework that enables MLLMs to iteratively refine trajectories based on environmental feedback. MTDrive introduces Multi-Turn Group Relative Policy Optimization (mtGRPO), which mitigates reward sparsity by computing relative advantages across turns. We further construct an interactive trajectory understanding dataset from closed-loop simulation to support multi-turn training. Experiments on the NAVSIM benchmark demonstrate superior performance compared to existing methods, validating the effectiveness of our multi-turn reasoning paradigm. Additionally, we implement system-level optimizations to reduce data transfer overhead caused by high-resolution images and multi-turn sequences, achieving 2.5x training throughput. Our data, models, and code will be made available soon.
TDACNN: Target-domain-free Domain Adaptation Convolutional Neural Network for Drift Compensation in Gas Sensors
Oct 15, 2021
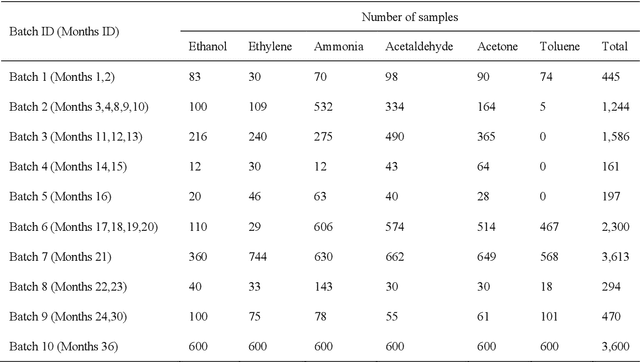
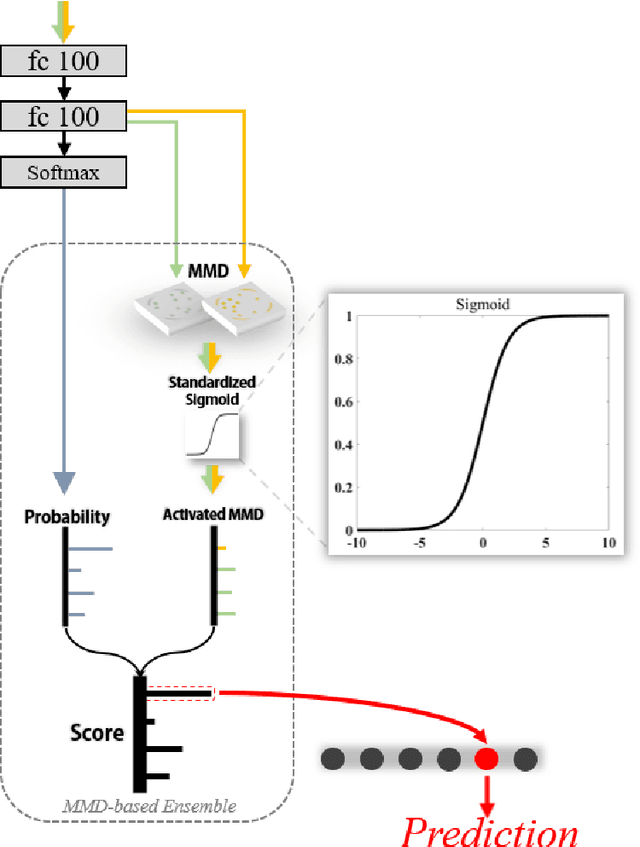

Sensor drift is a long-existing unpredictable problem that deteriorates the performance of gaseous substance recognition, calling for an antidrift domain adaptation algorithm. However, the prerequisite for traditional methods to achieve fine results is to have data from both nondrift distributions (source domain) and drift distributions (target domain) for domain alignment, which is usually unrealistic and unachievable in real-life scenarios. To compensate for this, in this paper, deep learning based on a target-domain-free domain adaptation convolutional neural network (TDACNN) is proposed. The main concept is that CNNs extract not only the domain-specific features of samples but also the domain-invariant features underlying both the source and target domains. Making full use of these various levels of embedding features can lead to comprehensive utilization of different levels of characteristics, thus achieving drift compensation by the extracted intermediate features between two domains. In the TDACNN, a flexible multibranch backbone with a multiclassifier structure is proposed under the guidance of bionics, which utilizes multiple embedding features comprehensively without involving target domain data during training. A classifier ensemble method based on maximum mean discrepancy (MMD) is proposed to evaluate all the classifiers jointly based on the credibility of the pseudolabel. To optimize network training, an additive angular margin softmax loss with parameter dynamic adjustment is utilized. Experiments on two drift datasets under different settings demonstrate the superiority of TDACNN compared with several state-of-the-art methods.
Accelerating Sparse DNN Models without Hardware-Support via Tile-Wise Sparsity
Aug 29, 2020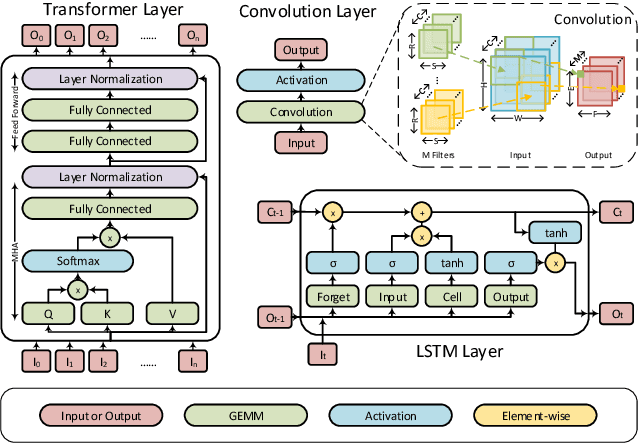
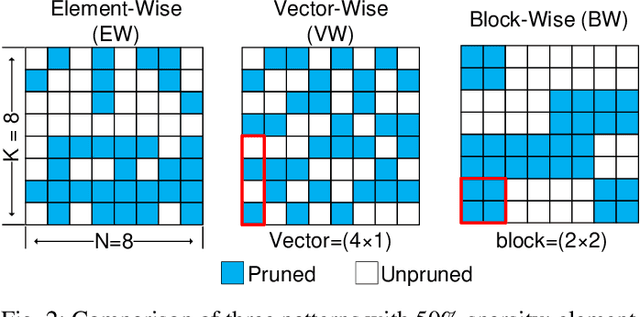
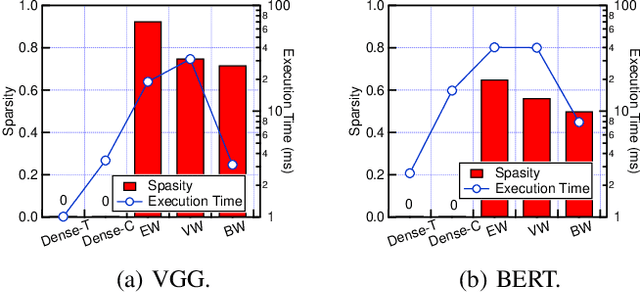
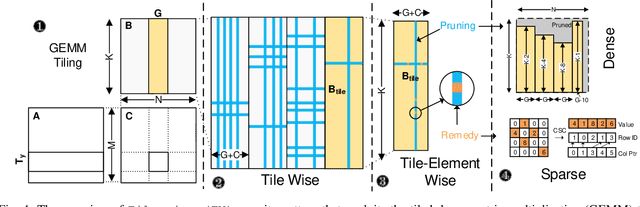
Network pruning can reduce the high computation cost of deep neural network (DNN) models. However, to maintain their accuracies, sparse models often carry randomly-distributed weights, leading to irregular computations. Consequently, sparse models cannot achieve meaningful speedup on commodity hardware (e.g., GPU) built for dense matrix computations. As such, prior works usually modify or design completely new sparsity-optimized architectures for exploiting sparsity. We propose an algorithm-software co-designed pruning method that achieves latency speedups on existing dense architectures. Our work builds upon the insight that the matrix multiplication generally breaks the large matrix into multiple smaller tiles for parallel execution. We propose a tiling-friendly "tile-wise" sparsity pattern, which maintains a regular pattern at the tile level for efficient execution but allows for irregular, arbitrary pruning at the global scale to maintain the high accuracy. We implement and evaluate the sparsity pattern on GPU tensor core, achieving a 1.95x speedup over the dense model.