 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance-Driven Environment Abstraction with Multi-Timescale Learning
Jun 16, 2026We study performance-driven environment abstraction for decision-making in large Markov decision processes. Rather than preserving geometric or topological structure, we seek abstractions that directly optimize decision quality. We model abstraction as a controlled approximation obtained by aggregating the state space and enforcing a shared action distribution within each aggregated state. For a fixed partition, we establish a performance guarantee that separates value-function approximation error from the loss introduced by action sharing. Guided by this analysis, we develop a multi-timescale reinforcement learning framework that jointly adapts the policy and a tree-structured environment abstraction. The resulting algorithm refines and coarsens regions of the state space based on Q-value discrepancies, balancing performance against abstraction size and complexity. Empirical results demonstrate substantial state compression, improved sample efficiency, and faster replanning compared to actor-critic baselines.
FlashCP: Load-Balanced Communication-Efficient Context Parallelism for LLM Training
Jun 07, 2026Context parallelism (CP) is essential for training large-scale, long-context language models, as it partitions sequences to reduce memory overhead. However, existing CP methods suffer from workload imbalance, inefficient kernels, and redundant communication due to static sequence sharding and key-value (KV) tensor communication. We present FlashCP, a load-balanced and communication-efficient framework for CP training. FlashCP introduces a sharding-aware communication mechanism to eliminate redundant KV communication and proposes a novel Whole-Doc sharding strategy that maximizes communication savings while maintaining balanced workloads. To efficiently combine Whole-Doc and Per-Doc sharding, FlashCP further designs a heuristic algorithm to search for near-optimal sharding plans. Extensive experiments show that FlashCP achieves up to 1.63x speedup over state-of-the-art CP frameworks across diverse datasets.
JigsawRL: Assembling RL Pipelines for Efficient LLM Post-Training
Apr 26, 2026We present JigsawRL, a cost-efficient framework that explores Pipeline Multiplexing as a new dimension of RL parallelism. JigsawRL decomposes each pipeline into a Sub-Stage Graph that exposes the intra-stage and inter-worker imbalance hidden by stage-level systems. On this abstraction, JigsawRL resolves multiplexing interference through dynamic resource allocation, eliminates fragmented utilization by migrating long-tail rollouts across workers, and formulates their coordination as a graph scheduling problem solved with a look-ahead heuristic. On 4-64 H100/A100 GPUs across different agentic RL pipelines and models, JigsawRL achieves up to 1.85x throughput over Verl on synchronous RL, 1.54x over StreamRL and AReaL on asynchronous RL, and supports heterogeneous pipelines with moderate latency trade-off.
ScaleSim: Serving Large-Scale Multi-Agent Simulation with Invocation Distance-Based Memory Management
Jan 29, 2026LLM-based multi-agent simulations are increasingly adopted across application domains, but remain difficult to scale due to GPU memory pressure. Each agent maintains private GPU-resident states, including models, prefix caches, and adapters, which quickly exhaust device memory as the agent count grows. We identify two key properties of these workloads: sparse agent activation and an estimable agent invocation order. Based on an analysis of representative workload classes, we introduce invocation distance, a unified abstraction that estimates the relative order in which agents will issue future LLM requests. Leveraging this abstraction, we present ScaleSim, a memory-efficient LLM serving system for large-scale multi-agent simulations. ScaleSim enables proactive prefetching and priority-based eviction, supports diverse agent-specific memory through a modular interface, and achieves up to 1.74x speedup over SGLang on simulation benchmarks.
Yggdrasil: Bridging Dynamic Speculation and Static Runtime for Latency-Optimal Tree-Based LLM Decoding
Dec 29, 2025Speculative decoding improves LLM inference by generating and verifying multiple tokens in parallel, but existing systems suffer from suboptimal performance due to a mismatch between dynamic speculation and static runtime assumptions. We present Yggdrasil, a co-designed system that enables latency-optimal speculative decoding through context-aware tree drafting and compiler-friendly execution. Yggdrasil introduces an equal-growth tree structure for static graph compatibility, a latency-aware optimization objective for draft selection, and stage-based scheduling to reduce overhead. Yggdrasil supports unmodified LLMs and achieves up to $3.98\times$ speedup over state-of-the-art baselines across multiple hardware setups.
An Efficient Private GPT Never Autoregressively Decodes
May 21, 2025The wide deployment of the generative pre-trained transformer (GPT) has raised privacy concerns for both clients and servers. While cryptographic primitives can be employed for secure GPT inference to protect the privacy of both parties, they introduce considerable performance overhead.To accelerate secure inference, this study proposes a public decoding and secure verification approach that utilizes public GPT models, motivated by the observation that securely decoding one and multiple tokens takes a similar latency. The client uses the public model to generate a set of tokens, which are then securely verified by the private model for acceptance. The efficiency of our approach depends on the acceptance ratio of tokens proposed by the public model, which we improve from two aspects: (1) a private sampling protocol optimized for cryptographic primitives and (2) model alignment using knowledge distillation. Our approach improves the efficiency of secure decoding while maintaining the same level of privacy and generation quality as standard secure decoding. Experiments demonstrate a $2.1\times \sim 6.0\times$ speedup compared to standard decoding across three pairs of public-private models and different network conditions.
Transkimmer: Transformer Learns to Layer-wise Skim
May 15, 2022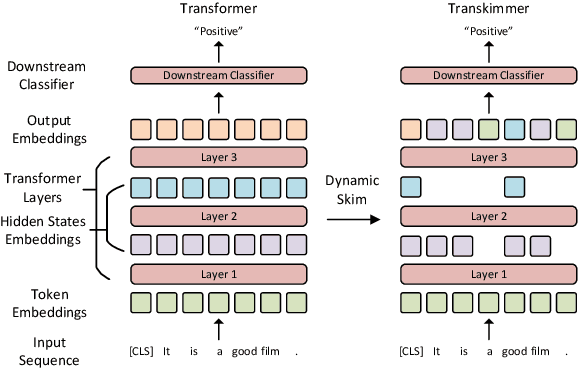
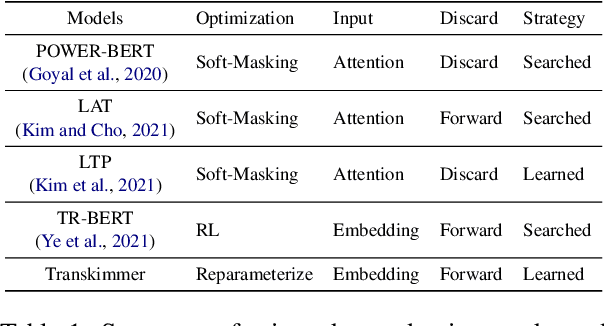
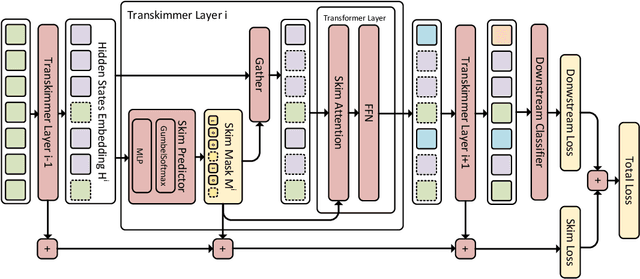

Transformer architecture has become the de-facto model for many machine learning tasks from natural language processing and computer vision. As such, improving its computational efficiency becomes paramount. One of the major computational inefficiency of Transformer-based models is that they spend the identical amount of computation throughout all layers. Prior works have proposed to augment the Transformer model with the capability of skimming tokens to improve its computational efficiency. However, they suffer from not having effectual and end-to-end optimization of the discrete skimming predictor. To address the above limitations, we propose the Transkimmer architecture, which learns to identify hidden state tokens that are not required by each layer. The skimmed tokens are then forwarded directly to the final output, thus reducing the computation of the successive layers. The key idea in Transkimmer is to add a parameterized predictor before each layer that learns to make the skimming decision. We also propose to adopt reparameterization trick and add skim loss for the end-to-end training of Transkimmer. Transkimmer achieves 10.97x average speedup on GLUE benchmark compared with vanilla BERT-base baseline with less than 1% accuracy degradation.
Block-Skim: Efficient Question Answering for Transformer
Dec 16, 2021

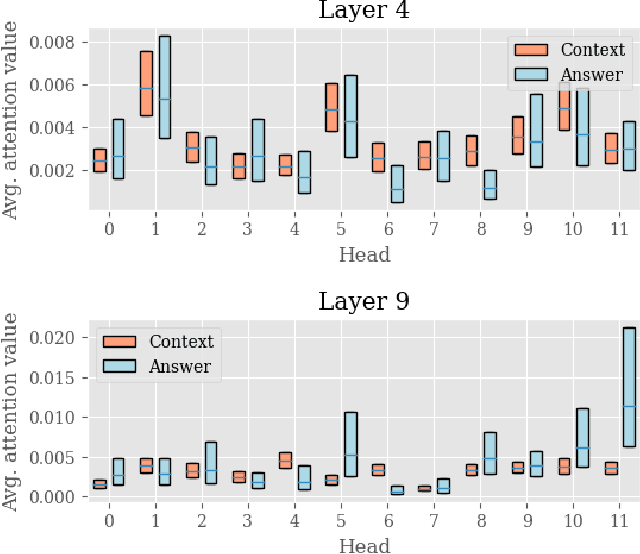
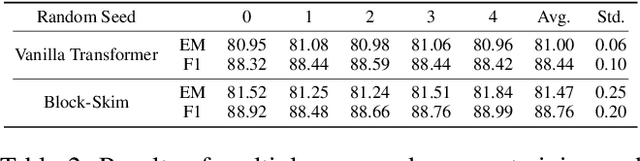
Transformer models have achieved promising results on natural language processing (NLP) tasks including extractive question answering (QA). Common Transformer encoders used in NLP tasks process the hidden states of all input tokens in the context paragraph throughout all layers. However, different from other tasks such as sequence classification, answering the raised question does not necessarily need all the tokens in the context paragraph. Following this motivation, we propose Block-skim, which learns to skim unnecessary context in higher hidden layers to improve and accelerate the Transformer performance. The key idea of Block-Skim is to identify the context that must be further processed and those that could be safely discarded early on during inference. Critically, we find that such information could be sufficiently derived from the self-attention weights inside the Transformer model. We further prune the hidden states corresponding to the unnecessary positions early in lower layers, achieving significant inference-time speedup. To our surprise, we observe that models pruned in this way outperform their full-size counterparts. Block-Skim improves QA models' accuracy on different datasets and achieves 3 times speedup on BERT-base model.
Joint Optical Neuroimaging Denoising with Semantic Tasks
Sep 22, 2021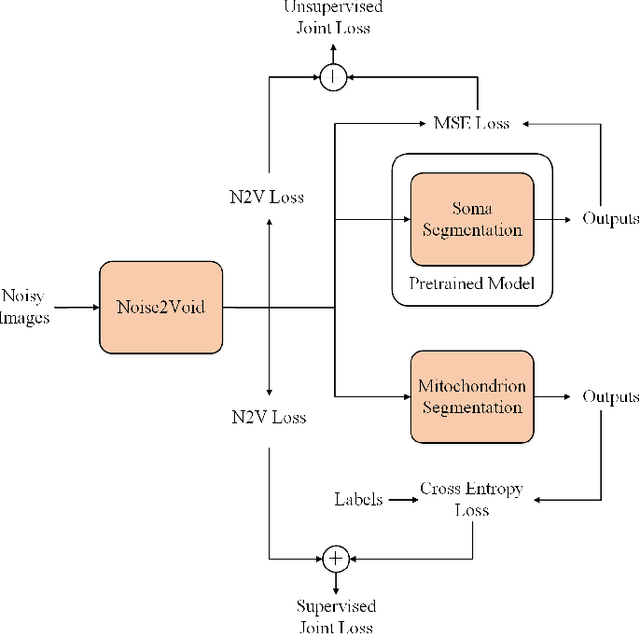
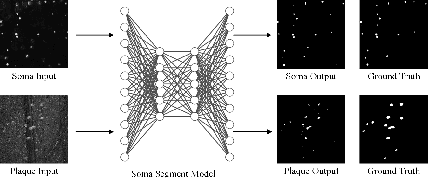
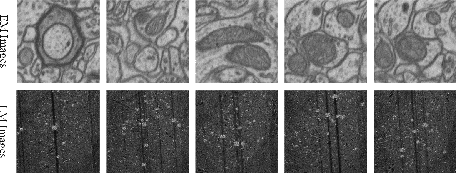
Optical neuroimaging is a vital tool for understanding the brain structure and the connection between regions and nuclei. However, the image noise introduced in the sample preparation and the imaging system hinders the extraction of the possible knowlege from the dataset, thus denoising for the optical neuroimaging is usually necessary. The supervised denoisng methods often outperform the unsupervised ones, but the training of the supervised denoising models needs the corresponding clean labels, which is not always avaiable due to the high labeling cost. On the other hand, those semantic labels, such as the located soma positions, the reconstructed neuronal fibers, and the nuclei segmentation result, are generally available and accumulated from everyday neuroscience research. This work connects a supervised denoising and a semantic segmentation model together to form a end-to-end model, which can make use of the semantic labels while still provides a denoised image as an intermediate product. We use both the supervised and the self-supervised models for the denoising and introduce a new cost term for the joint denoising and the segmentation setup. We test the proposed approach on both the synthetic data and the real-world data, including the optical neuroimaing dataset and the electron microscope dataset. The result shows that the joint denoising result outperforms the one using the denoising method alone and the joint model benefits the segmentation and other downstream task as well.
PointManifoldCut: Point-wise Augmentation in the Manifold for Point Clouds
Sep 15, 2021
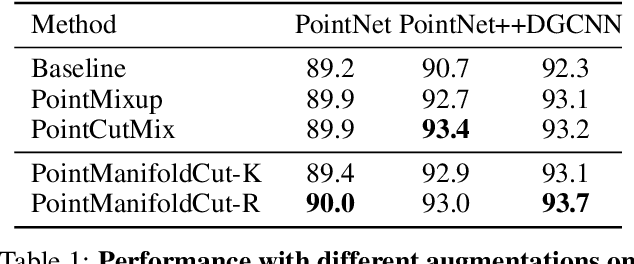
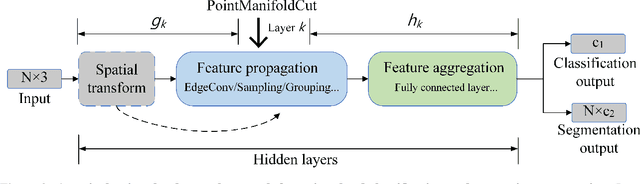
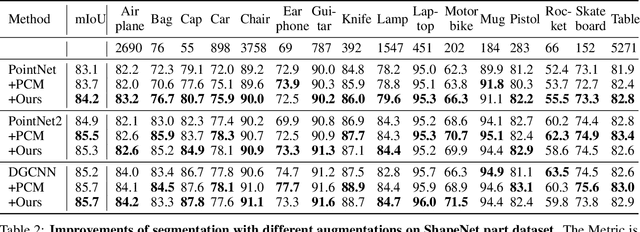
Augmentation can benefit point cloud learning due to the limited availability of large-scale public datasets. This paper proposes a mix-up augmentation approach, PointManifoldCut, which replaces the neural network embedded points, rather than the Euclidean space coordinates. This approach takes the advantage that points at the higher levels of the neural network are already trained to embed its neighbors relations and mixing these representation will not mingle the relation between itself and its label. This allows to regularize the parameter space as the other augmentation methods but without worrying about the proper label of the replaced points. The experiments show that our proposed approach provides a competitive performance on point cloud classification and segmentation when it is combined with the cutting-edge vanilla point cloud networks. The result shows a consistent performance boosting compared to other state-of-the-art point cloud augmentation method, such as PointMixup and PointCutMix. The code of this paper is available at: https://github.com/fun0515/PointManifoldCut.