 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Robots Feel Your Touch: Visuo-Tactile Cortical Alignment for Embodied Mirror Resonance
May 14, 2026Observing touch on another's body can elicit corresponding tactile sensations in the observer, a phenomenon termed mirror touch that supports empathy and social perception. This visuo-tactile resonance is thought to rely on structural correspondence between visual and somatosensory cortices, yet robotic systems lack computational frameworks that instantiate this principle. Here we demonstrate that cortical correspondence can be operationalized to endow robots with mirror touch. We introduce Mirror Touch Net, which imposes semantic, distributional and geometric alignment between visual and tactile representations through multi-level constraints, enabling prediction of millimetre-scale tactile signals across 1,140 taxels on a robotic hand from RGB images. Manifold analysis reveals that these constraints reshape visual representations into geometry consistent with the tactile manifold, reducing the complexity of cross-modal mapping. Extending this alignment framework to cross-domain observations of human hands enables tactile prediction and reflexive responses to observed human touch. Our results link a neural principle of visuo-tactile resonance to robotic perception, providing an explainable route towards anticipatory touch and empathic human-robot interaction. Code is available at https://github.com/fun0515/Mirror-Touch-Net.
Joint Optical Neuroimaging Denoising with Semantic Tasks
Sep 22, 2021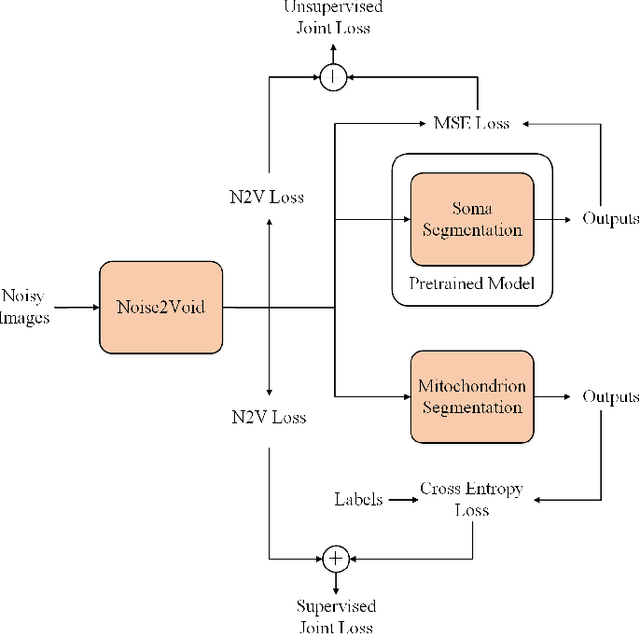
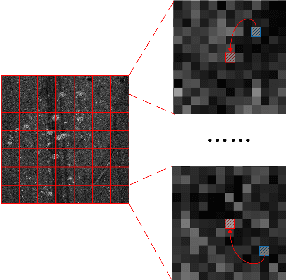
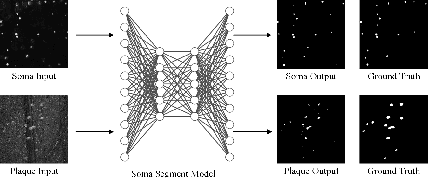
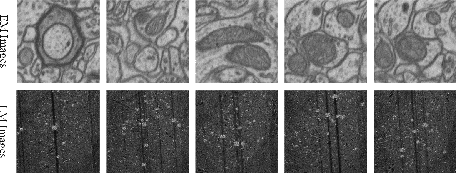
Optical neuroimaging is a vital tool for understanding the brain structure and the connection between regions and nuclei. However, the image noise introduced in the sample preparation and the imaging system hinders the extraction of the possible knowlege from the dataset, thus denoising for the optical neuroimaging is usually necessary. The supervised denoisng methods often outperform the unsupervised ones, but the training of the supervised denoising models needs the corresponding clean labels, which is not always avaiable due to the high labeling cost. On the other hand, those semantic labels, such as the located soma positions, the reconstructed neuronal fibers, and the nuclei segmentation result, are generally available and accumulated from everyday neuroscience research. This work connects a supervised denoising and a semantic segmentation model together to form a end-to-end model, which can make use of the semantic labels while still provides a denoised image as an intermediate product. We use both the supervised and the self-supervised models for the denoising and introduce a new cost term for the joint denoising and the segmentation setup. We test the proposed approach on both the synthetic data and the real-world data, including the optical neuroimaing dataset and the electron microscope dataset. The result shows that the joint denoising result outperforms the one using the denoising method alone and the joint model benefits the segmentation and other downstream task as well.
PointManifoldCut: Point-wise Augmentation in the Manifold for Point Clouds
Sep 15, 2021
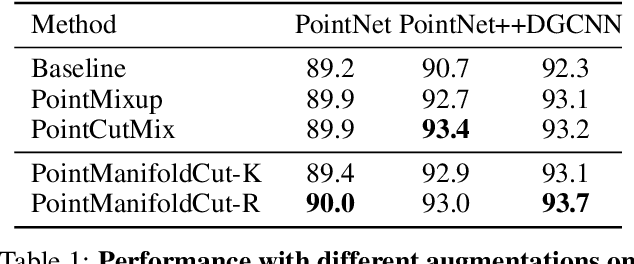
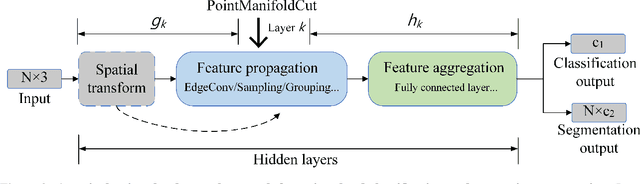
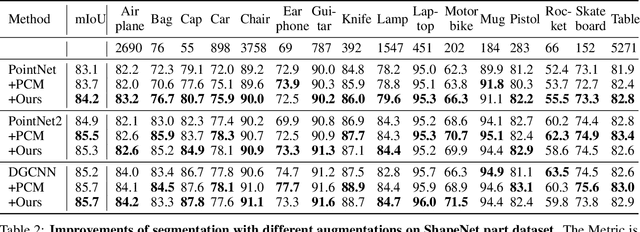
Augmentation can benefit point cloud learning due to the limited availability of large-scale public datasets. This paper proposes a mix-up augmentation approach, PointManifoldCut, which replaces the neural network embedded points, rather than the Euclidean space coordinates. This approach takes the advantage that points at the higher levels of the neural network are already trained to embed its neighbors relations and mixing these representation will not mingle the relation between itself and its label. This allows to regularize the parameter space as the other augmentation methods but without worrying about the proper label of the replaced points. The experiments show that our proposed approach provides a competitive performance on point cloud classification and segmentation when it is combined with the cutting-edge vanilla point cloud networks. The result shows a consistent performance boosting compared to other state-of-the-art point cloud augmentation method, such as PointMixup and PointCutMix. The code of this paper is available at: https://github.com/fun0515/PointManifoldCut.