 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNesting Forward Automatic Differentiation for Memory-Efficient Deep Neural Network Training
Sep 22, 2022



An activation function is an element-wise mathematical function and plays a crucial role in deep neural networks (DNN). Many novel and sophisticated activation functions have been proposed to improve the DNN accuracy but also consume massive memory in the training process with back-propagation. In this study, we propose the nested forward automatic differentiation (Forward-AD), specifically for the element-wise activation function for memory-efficient DNN training. We deploy nested Forward-AD in two widely-used deep learning frameworks, TensorFlow and PyTorch, which support the static and dynamic computation graph, respectively. Our evaluation shows that nested Forward-AD reduces the memory footprint by up to 1.97x than the baseline model and outperforms the recomputation by 20% under the same memory reduction ratio.
Efficient Activation Quantization via Adaptive Rounding Border for Post-Training Quantization
Aug 25, 2022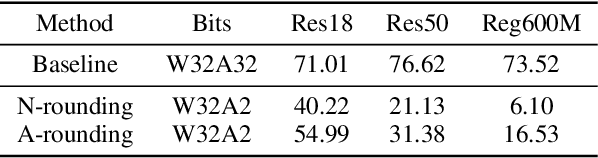
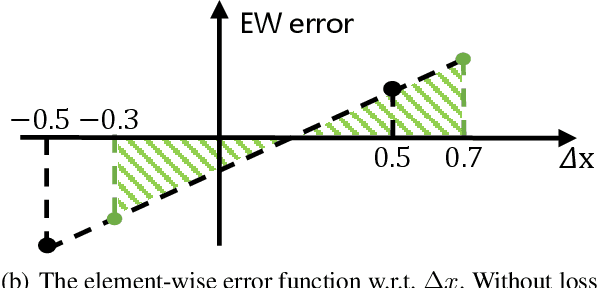
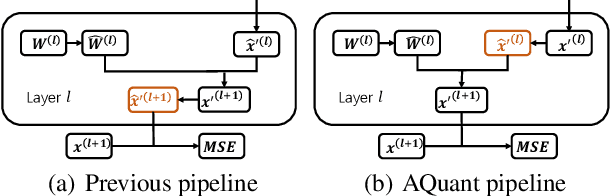
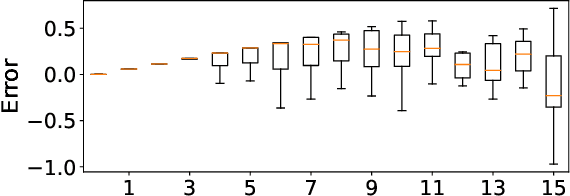
Post-training quantization (PTQ) attracts increasing attention due to its convenience in deploying quantized neural networks. Rounding, the primary source of quantization error, is optimized only for model weights, while activations still use the rounding-to-nearest operation. In this work, for the first time, we demonstrate that well-chosen rounding schemes for activations can improve the final accuracy. To deal with the challenge of the dynamicity of the activation rounding scheme, we adaptively adjust the rounding border through a simple function to generate rounding schemes at the inference stage. The border function covers the impact of weight errors, activation errors, and propagated errors to eliminate the bias of the element-wise error, which further benefits model accuracy. We also make the border aware of global errors to better fit different arriving activations. Finally, we propose the AQuant framework to learn the border function. Extensive experiments show that AQuant achieves noticeable improvements with negligible overhead compared with state-of-the-art works and pushes the accuracy of ResNet-18 up to 60.3\% under the 2-bit weight and activation post-training quantization.
SQuant: On-the-Fly Data-Free Quantization via Diagonal Hessian Approximation
Feb 14, 2022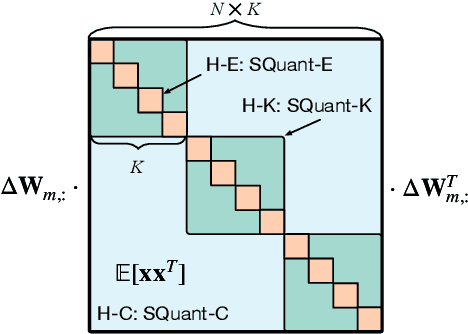
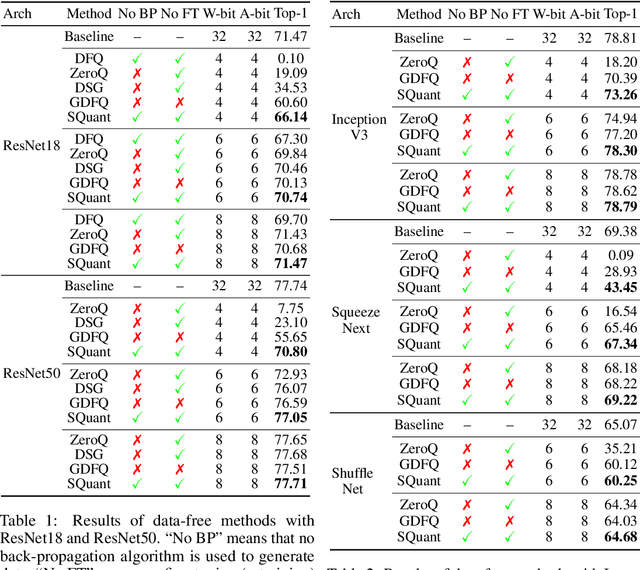
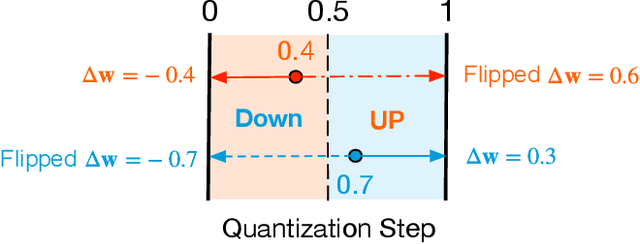
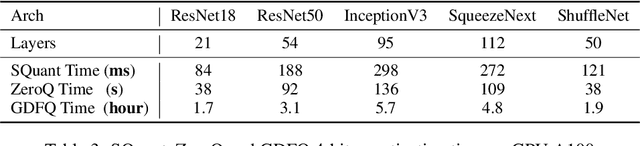
Quantization of deep neural networks (DNN) has been proven effective for compressing and accelerating DNN models. Data-free quantization (DFQ) is a promising approach without the original datasets under privacy-sensitive and confidential scenarios. However, current DFQ solutions degrade accuracy, need synthetic data to calibrate networks, and are time-consuming and costly. This paper proposes an on-the-fly DFQ framework with sub-second quantization time, called SQuant, which can quantize networks on inference-only devices with low computation and memory requirements. With the theoretical analysis of the second-order information of DNN task loss, we decompose and approximate the Hessian-based optimization objective into three diagonal sub-items, which have different areas corresponding to three dimensions of weight tensor: element-wise, kernel-wise, and output channel-wise. Then, we progressively compose sub-items and propose a novel data-free optimization objective in the discrete domain, minimizing Constrained Absolute Sum of Error (or CASE in short), which surprisingly does not need any dataset and is even not aware of network architecture. We also design an efficient algorithm without back-propagation to further reduce the computation complexity of the objective solver. Finally, without fine-tuning and synthetic datasets, SQuant accelerates the data-free quantization process to a sub-second level with >30% accuracy improvement over the existing data-free post-training quantization works, with the evaluated models under 4-bit quantization. We have open-sourced the SQuant framework at https://github.com/clevercool/SQuant.
Accelerating Sparse DNN Models without Hardware-Support via Tile-Wise Sparsity
Aug 29, 2020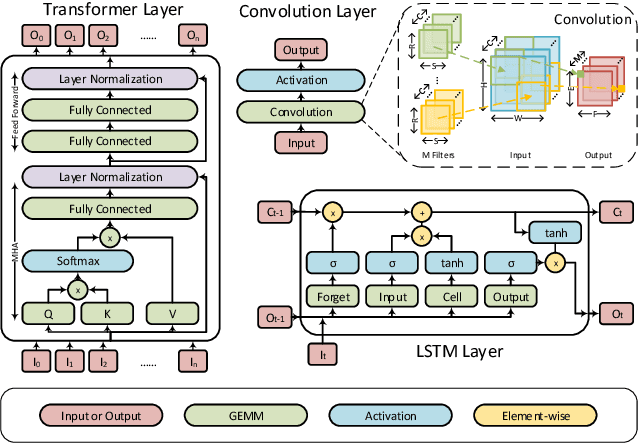
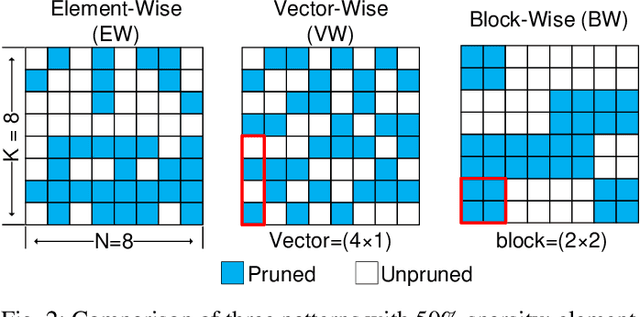
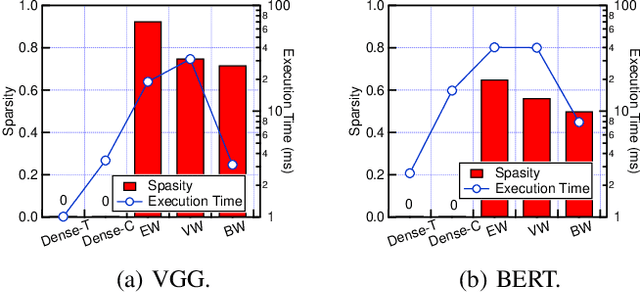
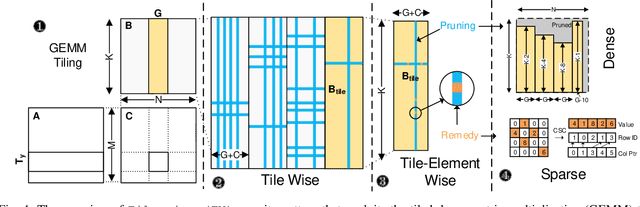
Network pruning can reduce the high computation cost of deep neural network (DNN) models. However, to maintain their accuracies, sparse models often carry randomly-distributed weights, leading to irregular computations. Consequently, sparse models cannot achieve meaningful speedup on commodity hardware (e.g., GPU) built for dense matrix computations. As such, prior works usually modify or design completely new sparsity-optimized architectures for exploiting sparsity. We propose an algorithm-software co-designed pruning method that achieves latency speedups on existing dense architectures. Our work builds upon the insight that the matrix multiplication generally breaks the large matrix into multiple smaller tiles for parallel execution. We propose a tiling-friendly "tile-wise" sparsity pattern, which maintains a regular pattern at the tile level for efficient execution but allows for irregular, arbitrary pruning at the global scale to maintain the high accuracy. We implement and evaluate the sparsity pattern on GPU tensor core, achieving a 1.95x speedup over the dense model.
Adversarial Defense Through Network Profiling Based Path Extraction
May 09, 2019


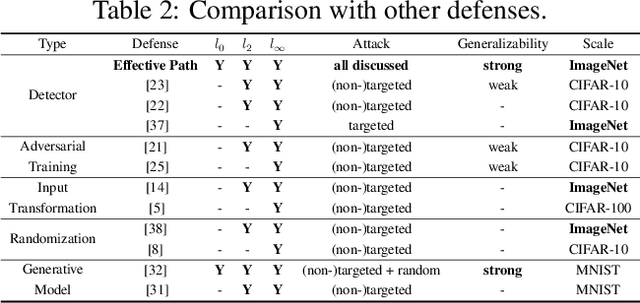
Recently, researchers have started decomposing deep neural network models according to their semantics or functions. Recent work has shown the effectiveness of decomposed functional blocks for defending adversarial attacks, which add small input perturbation to the input image to fool the DNN models. This work proposes a profiling-based method to decompose the DNN models to different functional blocks, which lead to the effective path as a new approach to exploring DNNs' internal organization. Specifically, the per-image effective path can be aggregated to the class-level effective path, through which we observe that adversarial images activate effective path different from normal images. We propose an effective path similarity-based method to detect adversarial images with an interpretable model, which achieve better accuracy and broader applicability than the state-of-the-art technique.