 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexus: Taming Throughput-Latency Tradeoff in LLM Serving via Efficient GPU Sharing
Jul 09, 2025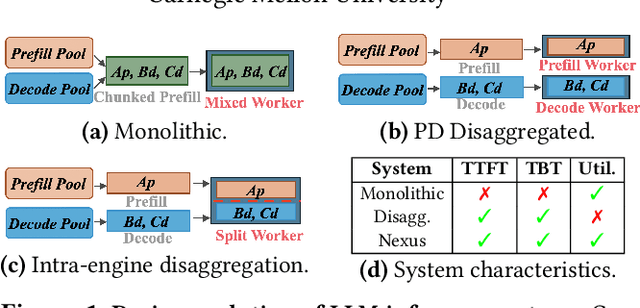
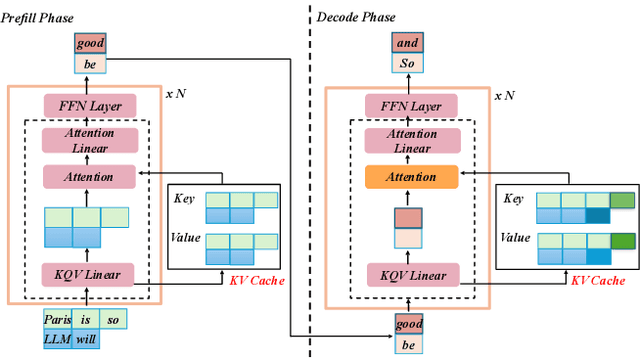
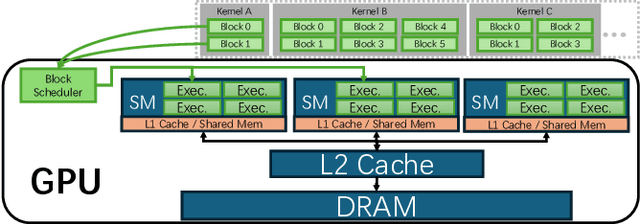
Current prefill-decode (PD) disaggregation is typically deployed at the level of entire serving engines, assigning separate GPUs to handle prefill and decode phases. While effective at reducing latency, this approach demands more hardware. To improve GPU utilization, Chunked Prefill mixes prefill and decode requests within the same batch, but introduces phase interference between prefill and decode. While existing PD disaggregation solutions separate the phases across GPUs, we ask: can the same decoupling be achieved within a single serving engine? The key challenge lies in managing the conflicting resource requirements of prefill and decode when they share the same hardware. In this paper, we first show that chunked prefill requests cause interference with decode requests due to their distinct requirements for GPU resources. Second, we find that GPU resources exhibit diminishing returns. Beyond a saturation point, increasing GPU allocation yields negligible latency improvements. This insight enables us to split a single GPU's resources and dynamically allocate them to prefill and decode on the fly, effectively disaggregating the two phases within the same GPU. Across a range of models and workloads, our system Nexus achieves up to 2.2x higher throughput, 20x lower TTFT, and 2.5x lower TBT than vLLM. It also outperforms SGLang with up to 2x higher throughput, 2x lower TTFT, and 1.7x lower TBT, and achieves 1.4x higher throughput than vLLM-disaggregation using only half the number of GPUs.
Mist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization
Mar 24, 2025Various parallelism, such as data, tensor, and pipeline parallelism, along with memory optimizations like activation checkpointing, redundancy elimination, and offloading, have been proposed to accelerate distributed training for Large Language Models. To find the best combination of these techniques, automatic distributed training systems are proposed. However, existing systems only tune a subset of optimizations, due to the lack of overlap awareness, inability to navigate the vast search space, and ignoring the inter-microbatch imbalance, leading to sub-optimal performance. To address these shortcomings, we propose Mist, a memory, overlap, and imbalance-aware automatic distributed training system that comprehensively co-optimizes all memory footprint reduction techniques alongside parallelism. Mist is based on three key ideas: (1) fine-grained overlap-centric scheduling, orchestrating optimizations in an overlapped manner, (2) symbolic-based performance analysis that predicts runtime and memory usage using symbolic expressions for fast tuning, and (3) imbalance-aware hierarchical tuning, decoupling the process into an inter-stage imbalance and overlap aware Mixed Integer Linear Programming problem and an intra-stage Dual-Objective Constrained Optimization problem, and connecting them through Pareto frontier sampling. Our evaluation results show that Mist achieves an average of 1.28$\times$ (up to 1.73$\times$) and 1.27$\times$ (up to 2.04$\times$) speedup compared to state-of-the-art manual system Megatron-LM and state-of-the-art automatic system Aceso, respectively.
Seesaw: High-throughput LLM Inference via Model Re-sharding
Mar 09, 2025To improve the efficiency of distributed large language model (LLM) inference, various parallelization strategies, such as tensor and pipeline parallelism, have been proposed. However, the distinct computational characteristics inherent in the two stages of LLM inference-prefilling and decoding-render a single static parallelization strategy insufficient for the effective optimization of both stages. In this work, we present Seesaw, an LLM inference engine optimized for throughput-oriented tasks. The key idea behind Seesaw is dynamic model re-sharding, a technique that facilitates the dynamic reconfiguration of parallelization strategies across stages, thereby maximizing throughput at both phases. To mitigate re-sharding overhead and optimize computational efficiency, we employ tiered KV cache buffering and transition-minimizing scheduling. These approaches work synergistically to reduce the overhead caused by frequent stage transitions while ensuring maximum batching efficiency. Our evaluation demonstrates that Seesaw achieves a throughput increase of up to 1.78x (1.36x on average) compared to vLLM, the most widely used state-of-the-art LLM inference engine.
Tempo: Accelerating Transformer-Based Model Training through Memory Footprint Reduction
Oct 19, 2022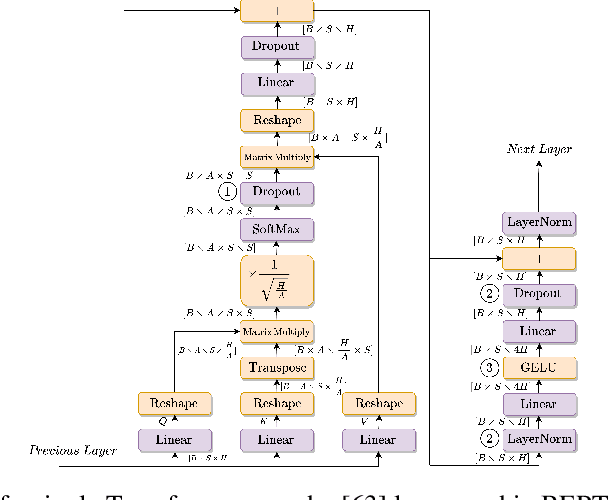

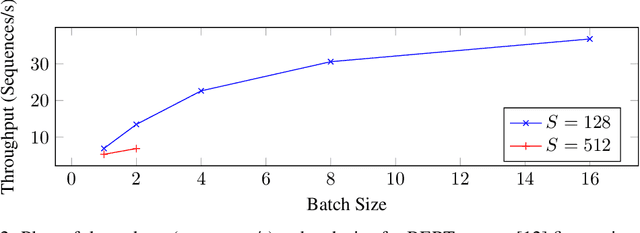

Training deep learning models can be computationally expensive. Prior works have shown that increasing the batch size can potentially lead to better overall throughput. However, the batch size is frequently limited by the accelerator memory capacity due to the activations/feature maps stored for the training backward pass, as larger batch sizes require larger feature maps to be stored. Transformer-based models, which have recently seen a surge in popularity due to their good performance and applicability to a variety of tasks, have a similar problem. To remedy this issue, we propose Tempo, a new approach to efficiently use accelerator (e.g., GPU) memory resources for training Transformer-based models. Our approach provides drop-in replacements for the GELU, LayerNorm, and Attention layers, reducing the memory usage and ultimately leading to more efficient training. We implement Tempo and evaluate the throughput, memory usage, and accuracy/loss on the BERT Large pre-training task. We demonstrate that Tempo enables up to 2x higher batch sizes and 16% higher training throughput over the state-of-the-art baseline. We also evaluate Tempo on GPT2 and RoBERTa models, showing 19% and 26% speedup over the baseline.
Efficient Activation Quantization via Adaptive Rounding Border for Post-Training Quantization
Aug 25, 2022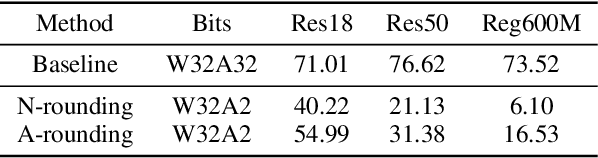
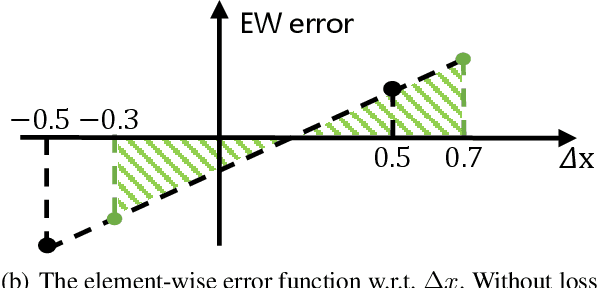
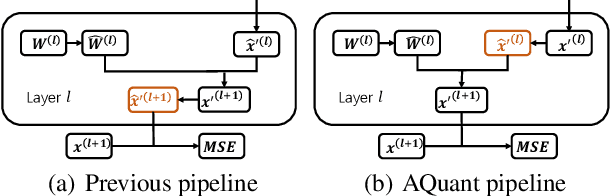
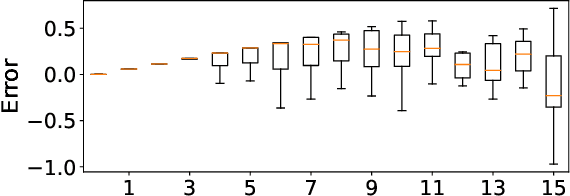
Post-training quantization (PTQ) attracts increasing attention due to its convenience in deploying quantized neural networks. Rounding, the primary source of quantization error, is optimized only for model weights, while activations still use the rounding-to-nearest operation. In this work, for the first time, we demonstrate that well-chosen rounding schemes for activations can improve the final accuracy. To deal with the challenge of the dynamicity of the activation rounding scheme, we adaptively adjust the rounding border through a simple function to generate rounding schemes at the inference stage. The border function covers the impact of weight errors, activation errors, and propagated errors to eliminate the bias of the element-wise error, which further benefits model accuracy. We also make the border aware of global errors to better fit different arriving activations. Finally, we propose the AQuant framework to learn the border function. Extensive experiments show that AQuant achieves noticeable improvements with negligible overhead compared with state-of-the-art works and pushes the accuracy of ResNet-18 up to 60.3\% under the 2-bit weight and activation post-training quantization.
RGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
Mar 03, 2021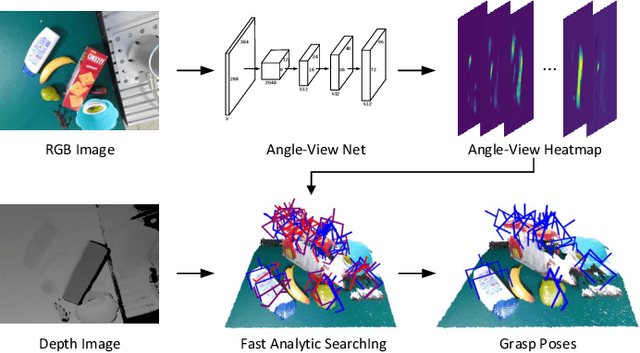
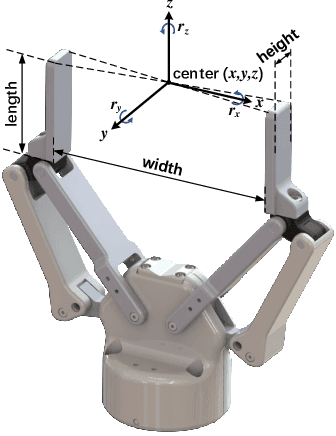
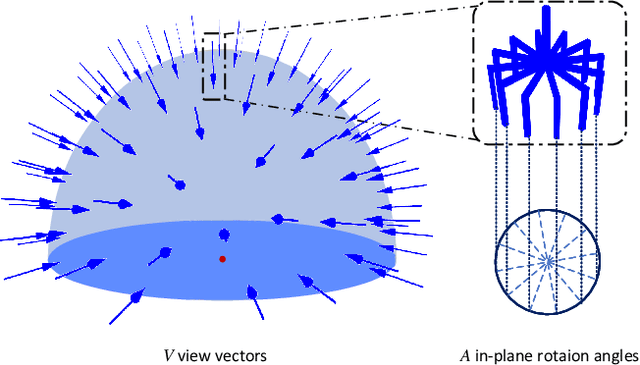
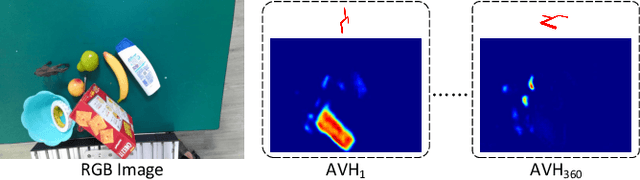
General object grasping is an important yet unsolved problem in the field of robotics. Most of the current methods either generate grasp poses with few DoF that fail to cover most of the success grasps, or only take the unstable depth image or point cloud as input which may lead to poor results in some cases. In this paper, we propose RGBD-Grasp, a pipeline that solves this problem by decoupling 7-DoF grasp detection into two sub-tasks where RGB and depth information are processed separately. In the first stage, an encoder-decoder like convolutional neural network Angle-View Net(AVN) is proposed to predict the SO(3) orientation of the gripper at every location of the image. Consequently, a Fast Analytic Searching(FAS) module calculates the opening width and the distance of the gripper to the grasp point. By decoupling the grasp detection problem and introducing the stable RGB modality, our pipeline alleviates the requirement for the high-quality depth image and is robust to depth sensor noise. We achieve state-of-the-art results on GraspNet-1Billion dataset compared with several baselines. Real robot experiments on a UR5 robot with an Intel Realsense camera and a Robotiq two-finger gripper show high success rates for both single object scenes and cluttered scenes. Our code and trained model will be made publicly available.