 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
Paper and Code
Mar 03, 2021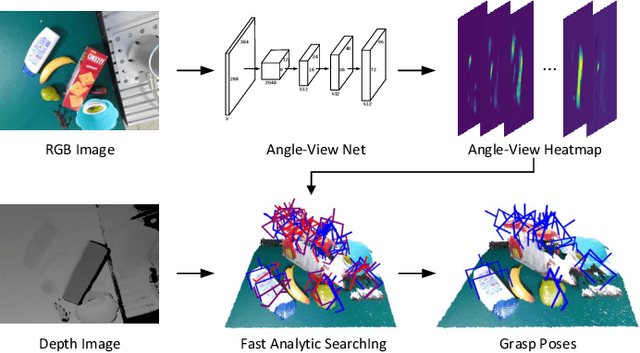
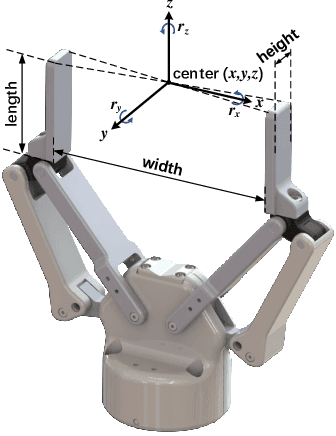
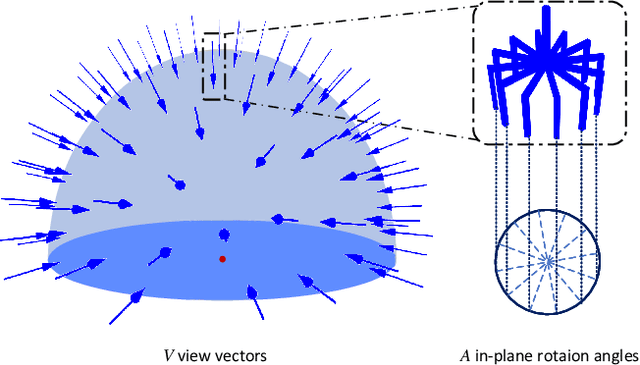
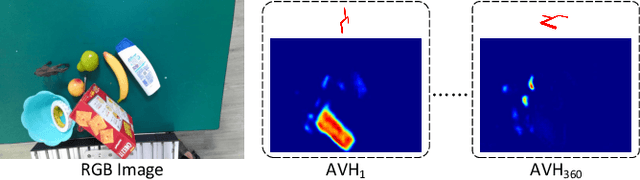
General object grasping is an important yet unsolved problem in the field of robotics. Most of the current methods either generate grasp poses with few DoF that fail to cover most of the success grasps, or only take the unstable depth image or point cloud as input which may lead to poor results in some cases. In this paper, we propose RGBD-Grasp, a pipeline that solves this problem by decoupling 7-DoF grasp detection into two sub-tasks where RGB and depth information are processed separately. In the first stage, an encoder-decoder like convolutional neural network Angle-View Net(AVN) is proposed to predict the SO(3) orientation of the gripper at every location of the image. Consequently, a Fast Analytic Searching(FAS) module calculates the opening width and the distance of the gripper to the grasp point. By decoupling the grasp detection problem and introducing the stable RGB modality, our pipeline alleviates the requirement for the high-quality depth image and is robust to depth sensor noise. We achieve state-of-the-art results on GraspNet-1Billion dataset compared with several baselines. Real robot experiments on a UR5 robot with an Intel Realsense camera and a Robotiq two-finger gripper show high success rates for both single object scenes and cluttered scenes. Our code and trained model will be made publicly available.