 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualWeaver: Synergistic Feature Weaving Surrogates for Multivariate Forecasting with Univariate Time Series Foundation Models
Feb 25, 2026Time-series foundation models (TSFMs) have achieved strong univariate forecasting through large-scale pre-training, yet effectively extending this success to multivariate forecasting remains challenging. To address this, we propose DualWeaver, a novel framework that adapts univariate TSFMs (Uni-TSFMs) for multivariate forecasting by using a pair of learnable, structurally symmetric surrogate series. Generated by a shared auxiliary feature-fusion module that captures cross-variable dependencies, these surrogates are mapped to TSFM-compatible series via the forecasting objective. The symmetric structure enables parameter-free reconstruction of final predictions directly from the surrogates, without additional parametric decoding. A theoretically grounded regularization term is further introduced to enhance robustness against adaptation collapse. Extensive experiments on diverse real-world datasets show that DualWeaver outperforms state-of-the-art multivariate forecasters in both accuracy and stability. We release the code at https://github.com/li-jinpeng/DualWeaver.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Mist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization
Mar 24, 2025Various parallelism, such as data, tensor, and pipeline parallelism, along with memory optimizations like activation checkpointing, redundancy elimination, and offloading, have been proposed to accelerate distributed training for Large Language Models. To find the best combination of these techniques, automatic distributed training systems are proposed. However, existing systems only tune a subset of optimizations, due to the lack of overlap awareness, inability to navigate the vast search space, and ignoring the inter-microbatch imbalance, leading to sub-optimal performance. To address these shortcomings, we propose Mist, a memory, overlap, and imbalance-aware automatic distributed training system that comprehensively co-optimizes all memory footprint reduction techniques alongside parallelism. Mist is based on three key ideas: (1) fine-grained overlap-centric scheduling, orchestrating optimizations in an overlapped manner, (2) symbolic-based performance analysis that predicts runtime and memory usage using symbolic expressions for fast tuning, and (3) imbalance-aware hierarchical tuning, decoupling the process into an inter-stage imbalance and overlap aware Mixed Integer Linear Programming problem and an intra-stage Dual-Objective Constrained Optimization problem, and connecting them through Pareto frontier sampling. Our evaluation results show that Mist achieves an average of 1.28$\times$ (up to 1.73$\times$) and 1.27$\times$ (up to 2.04$\times$) speedup compared to state-of-the-art manual system Megatron-LM and state-of-the-art automatic system Aceso, respectively.
Tempo: Accelerating Transformer-Based Model Training through Memory Footprint Reduction
Oct 19, 2022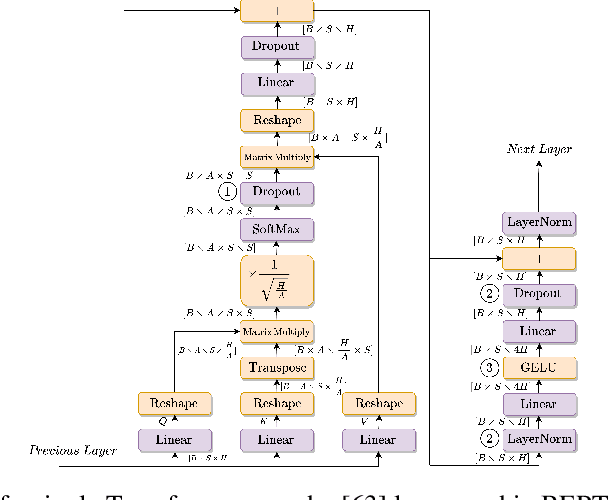

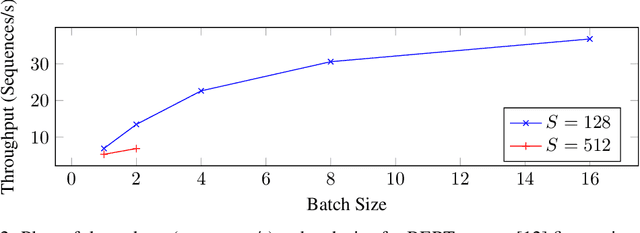

Training deep learning models can be computationally expensive. Prior works have shown that increasing the batch size can potentially lead to better overall throughput. However, the batch size is frequently limited by the accelerator memory capacity due to the activations/feature maps stored for the training backward pass, as larger batch sizes require larger feature maps to be stored. Transformer-based models, which have recently seen a surge in popularity due to their good performance and applicability to a variety of tasks, have a similar problem. To remedy this issue, we propose Tempo, a new approach to efficiently use accelerator (e.g., GPU) memory resources for training Transformer-based models. Our approach provides drop-in replacements for the GELU, LayerNorm, and Attention layers, reducing the memory usage and ultimately leading to more efficient training. We implement Tempo and evaluate the throughput, memory usage, and accuracy/loss on the BERT Large pre-training task. We demonstrate that Tempo enables up to 2x higher batch sizes and 16% higher training throughput over the state-of-the-art baseline. We also evaluate Tempo on GPT2 and RoBERTa models, showing 19% and 26% speedup over the baseline.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022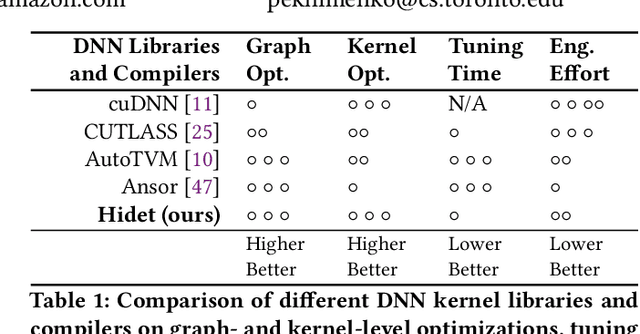
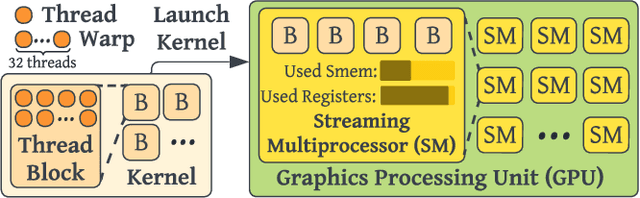
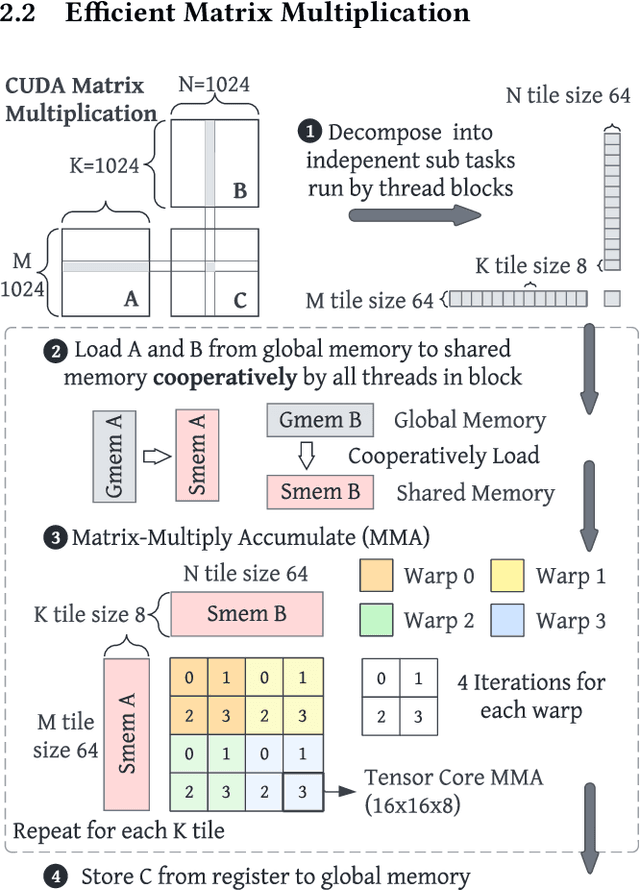
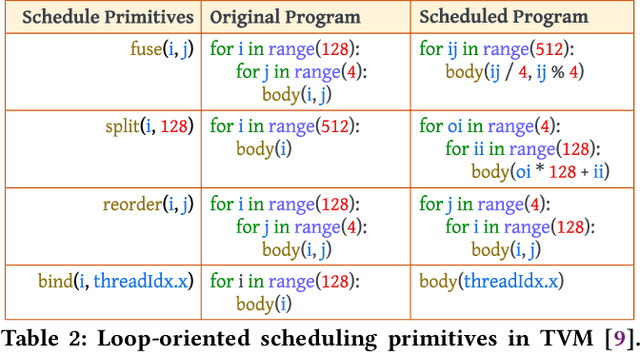
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
EcoRNN: Fused LSTM RNN Implementation with Data Layout Optimization
May 22, 2018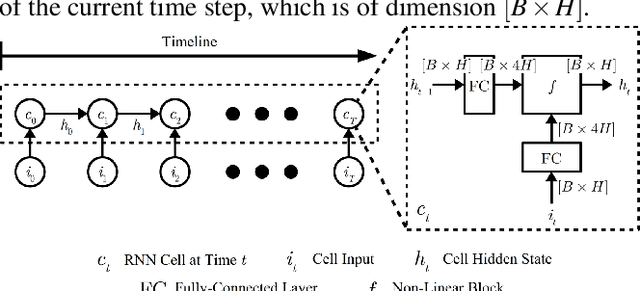



Long-Short-Term-Memory Recurrent Neural Network (LSTM RNN) is a state-of-the-art (SOTA) model for analyzing sequential data. Current implementations of LSTM RNN in machine learning frameworks usually either lack performance or flexibility. For example, default implementations in Tensorflow and MXNet invoke many tiny GPU kernels, leading to excessive overhead in launching GPU threads. Although cuDNN, NVIDIA's deep learning library, can accelerate performance by around 2x, it is closed-source and inflexible, hampering further research and performance improvements in frameworks, such as PyTorch, that use cuDNN as their backend. In this paper, we introduce a new RNN implementation called EcoRNN that is significantly faster than the SOTA open-source implementation in MXNet and is competitive with the closed-source cuDNN. We show that (1) fusing tiny GPU kernels and (2) applying data layout optimization can give us a maximum performance boost of 3x over MXNet default and 1.5x over cuDNN implementations. Our optimizations also apply to other RNN cell types such as LSTM variants and Gated Recurrent Units (GRUs). We integrate EcoRNN into MXNet Python library and open-source it to benefit machine learning practitioners.
TBD: Benchmarking and Analyzing Deep Neural Network Training
Apr 14, 2018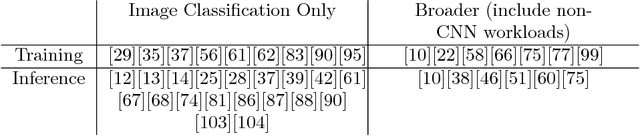
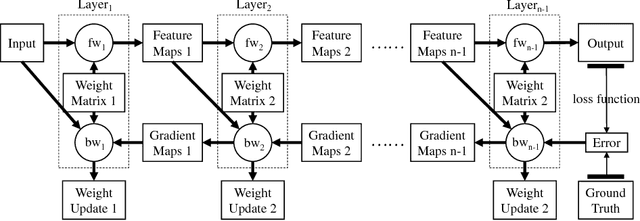


The recent popularity of deep neural networks (DNNs) has generated a lot of research interest in performing DNN-related computation efficiently. However, the primary focus is usually very narrow and limited to (i) inference -- i.e. how to efficiently execute already trained models and (ii) image classification networks as the primary benchmark for evaluation. Our primary goal in this work is to break this myopic view by (i) proposing a new benchmark for DNN training, called TBD (TBD is short for Training Benchmark for DNNs), that uses a representative set of DNN models that cover a wide range of machine learning applications: image classification, machine translation, speech recognition, object detection, adversarial networks, reinforcement learning, and (ii) by performing an extensive performance analysis of training these different applications on three major deep learning frameworks (TensorFlow, MXNet, CNTK) across different hardware configurations (single-GPU, multi-GPU, and multi-machine). TBD currently covers six major application domains and eight different state-of-the-art models. We present a new toolchain for performance analysis for these models that combines the targeted usage of existing performance analysis tools, careful selection of new and existing metrics and methodologies to analyze the results, and utilization of domain specific characteristics of DNN training. We also build a new set of tools for memory profiling in all three major frameworks; much needed tools that can finally shed some light on precisely how much memory is consumed by different data structures (weights, activations, gradients, workspace) in DNN training. By using our tools and methodologies, we make several important observations and recommendations on where the future research and optimization of DNN training should be focused.