 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoRNN: Fused LSTM RNN Implementation with Data Layout Optimization
May 22, 2018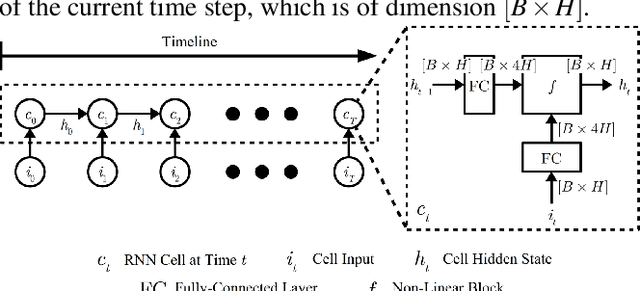



Long-Short-Term-Memory Recurrent Neural Network (LSTM RNN) is a state-of-the-art (SOTA) model for analyzing sequential data. Current implementations of LSTM RNN in machine learning frameworks usually either lack performance or flexibility. For example, default implementations in Tensorflow and MXNet invoke many tiny GPU kernels, leading to excessive overhead in launching GPU threads. Although cuDNN, NVIDIA's deep learning library, can accelerate performance by around 2x, it is closed-source and inflexible, hampering further research and performance improvements in frameworks, such as PyTorch, that use cuDNN as their backend. In this paper, we introduce a new RNN implementation called EcoRNN that is significantly faster than the SOTA open-source implementation in MXNet and is competitive with the closed-source cuDNN. We show that (1) fusing tiny GPU kernels and (2) applying data layout optimization can give us a maximum performance boost of 3x over MXNet default and 1.5x over cuDNN implementations. Our optimizations also apply to other RNN cell types such as LSTM variants and Gated Recurrent Units (GRUs). We integrate EcoRNN into MXNet Python library and open-source it to benefit machine learning practitioners.