 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBD: Benchmarking and Analyzing Deep Neural Network Training
Apr 14, 2018
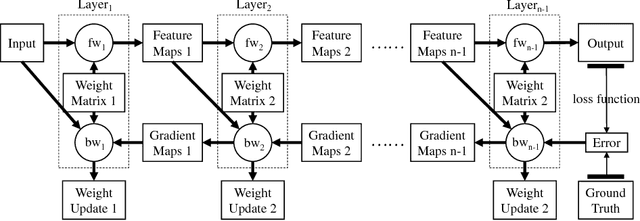


The recent popularity of deep neural networks (DNNs) has generated a lot of research interest in performing DNN-related computation efficiently. However, the primary focus is usually very narrow and limited to (i) inference -- i.e. how to efficiently execute already trained models and (ii) image classification networks as the primary benchmark for evaluation. Our primary goal in this work is to break this myopic view by (i) proposing a new benchmark for DNN training, called TBD (TBD is short for Training Benchmark for DNNs), that uses a representative set of DNN models that cover a wide range of machine learning applications: image classification, machine translation, speech recognition, object detection, adversarial networks, reinforcement learning, and (ii) by performing an extensive performance analysis of training these different applications on three major deep learning frameworks (TensorFlow, MXNet, CNTK) across different hardware configurations (single-GPU, multi-GPU, and multi-machine). TBD currently covers six major application domains and eight different state-of-the-art models. We present a new toolchain for performance analysis for these models that combines the targeted usage of existing performance analysis tools, careful selection of new and existing metrics and methodologies to analyze the results, and utilization of domain specific characteristics of DNN training. We also build a new set of tools for memory profiling in all three major frameworks; much needed tools that can finally shed some light on precisely how much memory is consumed by different data structures (weights, activations, gradients, workspace) in DNN training. By using our tools and methodologies, we make several important observations and recommendations on where the future research and optimization of DNN training should be focused.