 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Cost Black-Box Detection of LLM Hallucinations via Dynamical System Prediction
May 06, 2026Large Language Models (LLMs) frequently generate plausible but non-factual content, a phenomenon known as hallucination. While existing detection methods typically rely on computationally expensive sampling-based consistency checks or external knowledge retrieval, we propose a new method that treats the LLM as a black-box dynamical system. By projecting LLM responses into a high-dimensional manifold via an embedding model, we characterize the resulting vector sequences as observable realizations of the model's latent state-space dynamics. Leveraging Koopman operator theory, we fit the transition operators for both factual and hallucinated regimes and define a differential residual score based on their respective prediction errors. To accommodate varying user requirements and domain-specific sensitivities, we introduce a preference-aware calibration mechanism that optimizes the classification threshold based on a small set of demonstrations. This approach enables low-cost hallucination detection in a single-sample pass, avoiding the need for secondary sampling or external grounding. Extensive testing across three data benchmarks demonstrates that our method achieves state-of-the-art performance with reduced resource overhead.
Signal Processing Foundations of Reconfigurable Antennas in the Tri-Hybrid MIMO Architecture
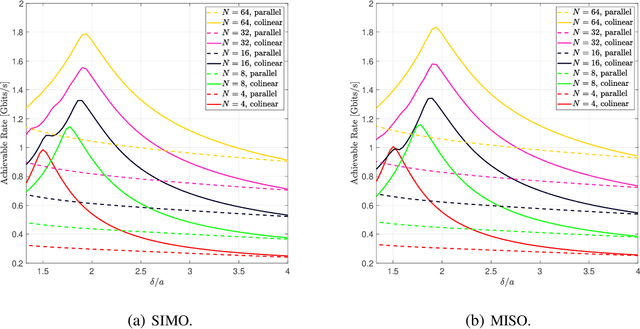
Apr 26, 2026To enable larger apertures in multipleinput multipleoutput MIMO systems the trihybrid MIMO architecture offers a promising lowcost and lowpower solution by introducing reconfigurable antennas as a third layer of precoding on top of conventional digital and analog processing In this paper we develop a unified signal processing framework for trihybrid MIMO that explicitly captures the electromagnetic EM characteristics of diverse reconfigurable antenna technologies We first propose a generic inputoutput model that incorporates the reconfigurable antenna layer into an effective channel representation revealing a fundamental coupling between the channel precoder and radiated power Building on this model we formulate a general optimization problem that jointly accounts for digital analog and antennadomain precoding under hardware and power constraints We then instantiate this framework across seven representative reconfigurable antenna architectures including parasitic arrays dynamic metasurface antennas fluidpixel antennas polarizationreconfigurable antennas stacked intelligent metasurfaces pinching antenna systems and nonradiating wires To systematically compare these heterogeneous architectures we introduce a new metric the reconfigurability efficiency factor REF which quantifies the performance gains achievable through antenna reconfiguration under realistic constraints Numerical results demonstrate the tradeoffs among aperture size power consumption hardware complexity and spectral efficiency Our results establish that EMlevel reconfiguration reshapes the signal processing design space highlighting the need for new architectures and algorithms that jointly optimize across digital analog and electromagnetic domains This work reveals that electromagnetic reconfiguration couples the channel and precoder
Next-slot OFDM-CSI Prediction: Multi-head Self-attention or State Space Model?
May 17, 2024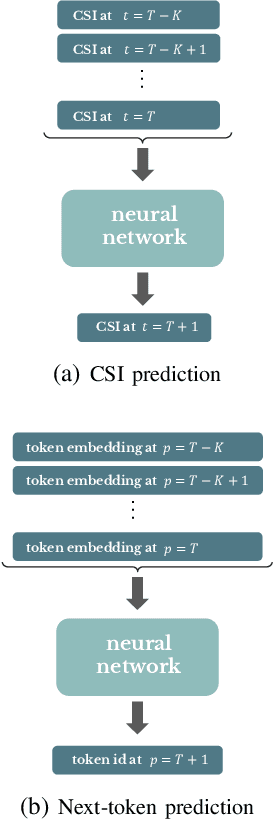
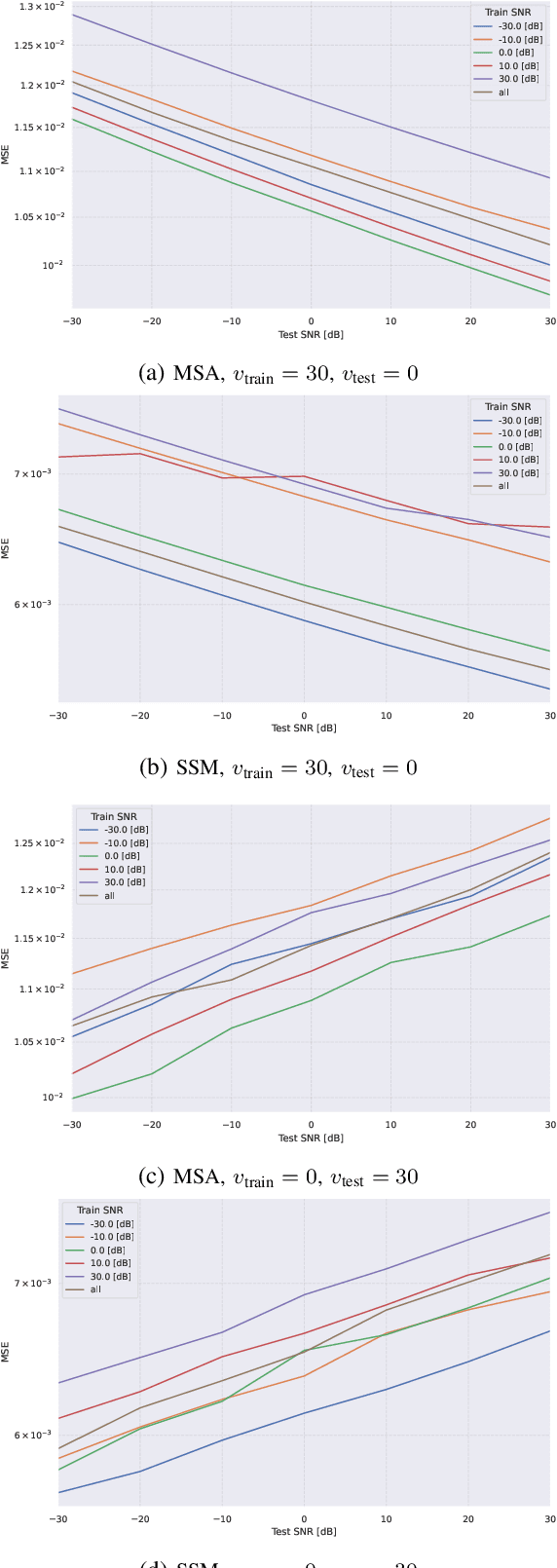
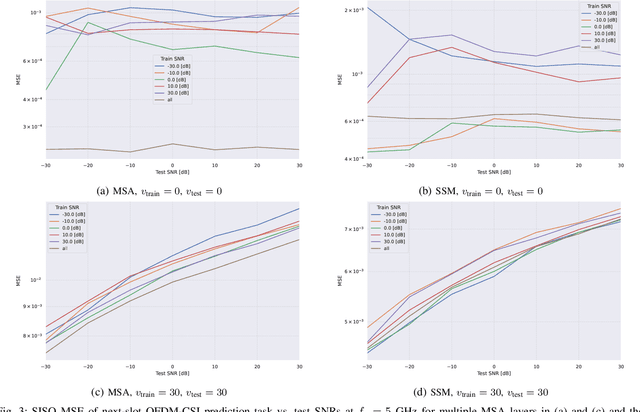
The ongoing fifth-generation (5G) standardization is exploring the use of deep learning (DL) methods to enhance the new radio (NR) interface. Both in academia and industry, researchers are investigating the performance and complexity of multiple DL architecture candidates for specific one-sided and two-sided use cases such as channel state estimation (CSI) feedback, CSI prediction, beam management, and positioning. In this paper, we set focus on the CSI prediction task and study the performance and generalization of the two main DL layers that are being extensively benchmarked within the DL community, namely, multi-head self-attention (MSA) and state-space model (SSM). We train and evaluate MSA and SSM layers to predict the next slot for uplink and downlink communication scenarios over urban microcell (UMi) and urban macrocell (UMa) OFDM 5G channel models. Our numerical results demonstrate that SSMs exhibit better prediction and generalization capabilities than MSAs only for SISO cases. For MIMO scenarios, however, the MSA layer outperforms the SSM one. While both layers represent potential DL architectures for future DL-enabled 5G use cases, the overall investigation of this paper favors MSAs over SSMs.
Representations Matter: Embedding Modes of Large Language Models using Dynamic Mode Decomposition
Sep 03, 2023
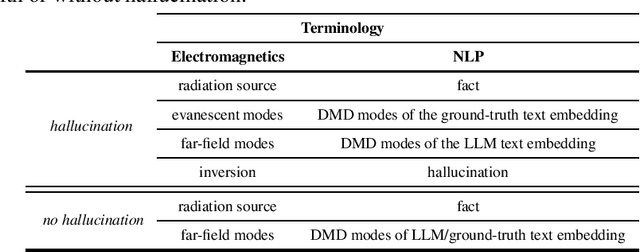
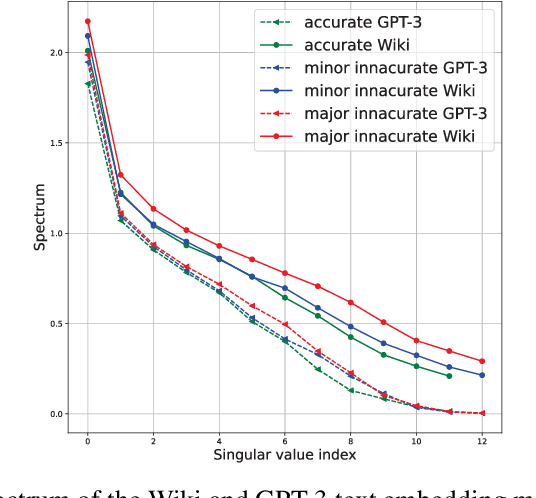
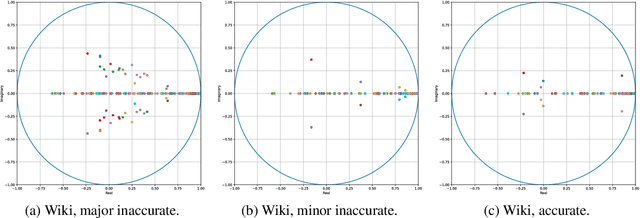
Existing large language models (LLMs) are known for generating "hallucinated" content, namely a fabricated text of plausibly looking, yet unfounded, facts. To identify when these hallucination scenarios occur, we examine the properties of the generated text in the embedding space. Specifically, we draw inspiration from the dynamic mode decomposition (DMD) tool in analyzing the pattern evolution of text embeddings across sentences. We empirically demonstrate how the spectrum of sentence embeddings over paragraphs is constantly low-rank for the generated text, unlike that of the ground-truth text. Importantly, we find that evaluation cases having LLM hallucinations correspond to ground-truth embedding patterns with a higher number of modes being poorly approximated by the few modes associated with LLM embedding patterns. In analogy to near-field electromagnetic evanescent waves, the embedding DMD eigenmodes of the generated text with hallucinations vanishes quickly across sentences as opposed to those of the ground-truth text. This suggests that the hallucinations result from both the generation techniques and the underlying representation.
Domain Generalization in Machine Learning Models for Wireless Communications: Concepts, State-of-the-Art, and Open Issues
Mar 13, 2023



Data-driven machine learning (ML) is promoted as one potential technology to be used in next-generations wireless systems. This led to a large body of research work that applies ML techniques to solve problems in different layers of the wireless transmission link. However, most of these applications rely on supervised learning which assumes that the source (training) and target (test) data are independent and identically distributed (i.i.d). This assumption is often violated in the real world due to domain or distribution shifts between the source and the target data. Thus, it is important to ensure that these algorithms generalize to out-of-distribution (OOD) data. In this context, domain generalization (DG) tackles the OOD-related issues by learning models on different and distinct source domains/datasets with generalization capabilities to unseen new domains without additional finetuning. Motivated by the importance of DG requirements for wireless applications, we present a comprehensive overview of the recent developments in DG and the different sources of domain shift. We also summarize the existing DG methods and review their applications in selected wireless communication problems, and conclude with insights and open questions.
Diffusion-based Data Augmentation for Skin Disease Classification: Impact Across Original Medical Datasets to Fully Synthetic Images
Jan 12, 2023



Despite continued advancement in recent years, deep neural networks still rely on large amounts of training data to avoid overfitting. However, labeled training data for real-world applications such as healthcare is limited and difficult to access given longstanding privacy, and strict data sharing policies. By manipulating image datasets in the pixel or feature space, existing data augmentation techniques represent one of the effective ways to improve the quantity and diversity of training data. Here, we look to advance augmentation techniques by building upon the emerging success of text-to-image diffusion probabilistic models in augmenting the training samples of our macroscopic skin disease dataset. We do so by enabling fine-grained control of the image generation process via input text prompts. We demonstrate that this generative data augmentation approach successfully maintains a similar classification accuracy of the visual classifier even when trained on a fully synthetic skin disease dataset. Similar to recent applications of generative models, our study suggests that diffusion models are indeed effective in generating high-quality skin images that do not sacrifice the classifier performance, and can improve the augmentation of training datasets after curation.
Continual Learning-Based MIMO Channel Estimation: A Benchmarking Study
Nov 19, 2022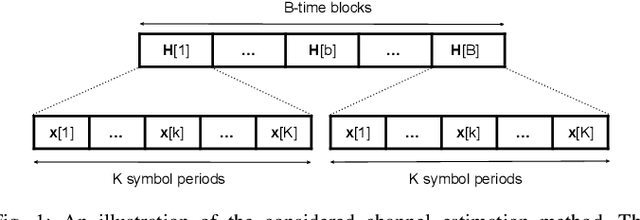
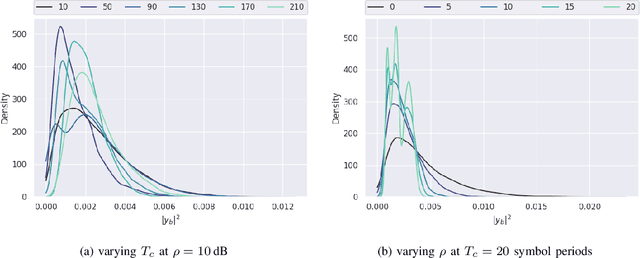
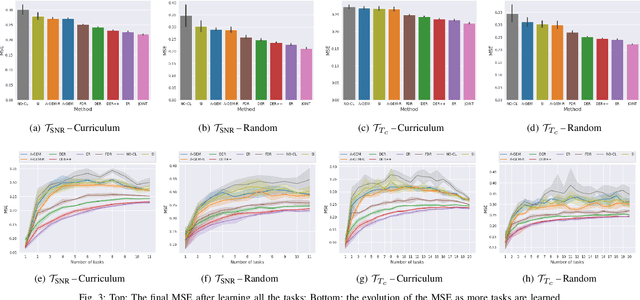
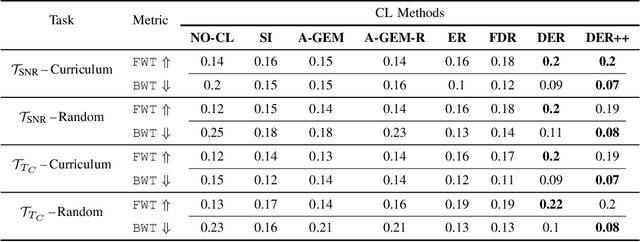
With the proliferation of deep learning techniques for wireless communication, several works have adopted learning-based approaches to solve the channel estimation problem. While these methods are usually promoted for their computational efficiency at inference time, their use is restricted to specific stationary training settings in terms of communication system parameters, e.g., signal-to-noise ratio (SNR) and coherence time. Therefore, the performance of these learning-based solutions will degrade when the models are tested on different settings than the ones used for training. This motivates our work in which we investigate continual supervised learning (CL) to mitigate the shortcomings of the current approaches. In particular, we design a set of channel estimation tasks wherein we vary different parameters of the channel model. We focus on Gauss-Markov Rayleigh fading channel estimation to assess the impact of non-stationarity on performance in terms of the mean square error (MSE) criterion. We study a selection of state-of-the-art CL methods and we showcase empirically the importance of catastrophic forgetting in continuously evolving channel settings. Our results demonstrate that the CL algorithms can improve the interference performance in two channel estimation tasks governed by changes in the SNR level and coherence time.
Super-Wideband Massive MIMO
Aug 02, 2022
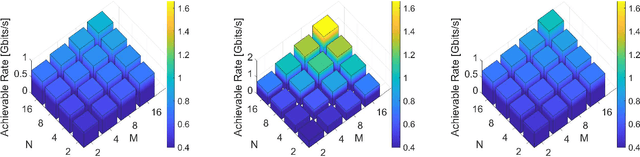
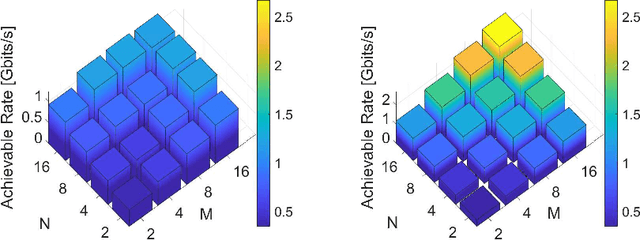
We present a unified model for connected antenna arrays with a massive (but finite) number of tightly integrated (i.e., coupled) antennas in a compact space within the context of massive multiple-input multiple-output (MIMO) communication. We refer to this system as tightly-coupled massive MIMO. From an information-theoretic perspective, scaling the design of tightly-coupled massive MIMO systems in terms of the number of antennas, the operational bandwidth, and form factor was not addressed in prior art and hence not clearly understood. We investigate this open research problem using a physically consistent modeling approach for far-field (FF) MIMO communication based on multi-port circuit theory. In doing so, we turn mutual coupling (MC) from a foe to a friend of MIMO systems design, thereby challenging a basic percept in antenna systems engineering that promotes MC mitigation/compensation. We show that tight MC widens the operational bandwidth of antenna arrays thereby unleashing a missing MIMO gain that we coin "bandwidth gain". Furthermore, we derive analytically the asymptotically optimum spacing-to-antenna-size ratio by establishing a condition for tight coupling in the limit of large-size antenna arrays with quasi-continuous apertures. We also optimize the antenna array size while maximizing the achievable rate under fixed transmit power and inter-element spacing. Then, we study the impact of MC on the achievable rate of MIMO systems under light-of-sight (LoS) and Rayleigh fading channels. These results reveal new insights into the design of tightly-coupled massive antenna arrays as opposed to the widely-adopted "disconnected" designs that disregard MC by putting faith in the half-wavelength spacing rule.
On Bock's Conjecture Regarding the Adam Optimizer
Nov 16, 2021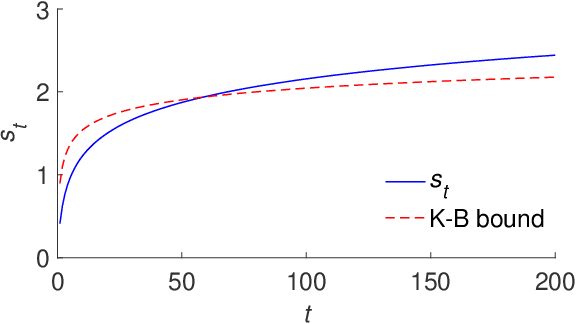
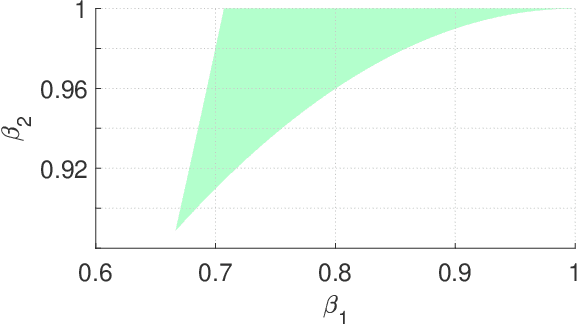
In 2014, Kingma and Ba published their Adam optimizer algorithm, together with a mathematical argument that was meant to help justify it. In 2018, Bock and colleagues reported that a key piece was missing from that argument $-$ an unproven lemma which we will call Bock's conjecture. Here we show that this conjecture is false, but a modified version of it does hold, and fills the gap in Bock's proof of convergence for Adam.
Optimizing Binary Symptom Checkers via Approximate Message Passing
Oct 30, 2021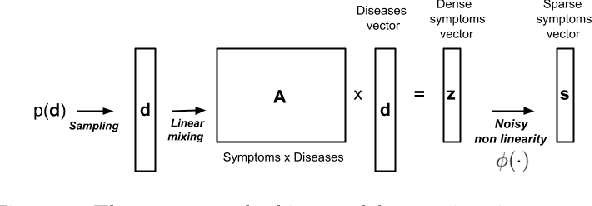
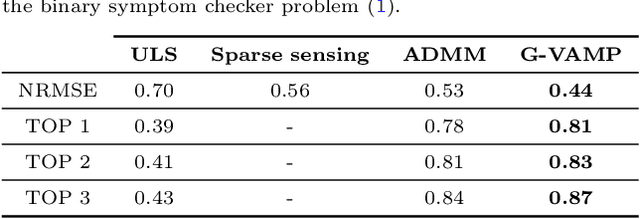
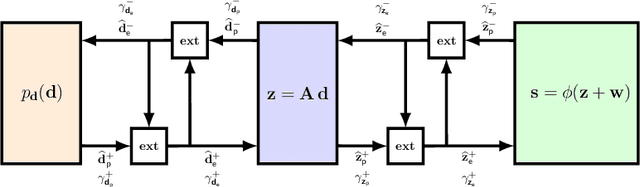
Symptom checkers have been widely adopted as an intelligent e-healthcare application during the ongoing pandemic crisis. Their performance have been limited by the fine-grained quality of the collected medical knowledge between symptom and diseases. While the binarization of the relationships between symptoms and diseases simplifies the data collection process, it also leads to non-convex optimization problems during the inference step. In this paper, we formulate the symptom checking problem as an underdertermined non-convex optimization problem, thereby justifying the use of the compressive sensing framework to solve it. We show that the generalized vector approximate message passing (G-VAMP) algorithm provides the best performance for binary symptom checkers.