 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Bock's Conjecture Regarding the Adam Optimizer
Nov 16, 2021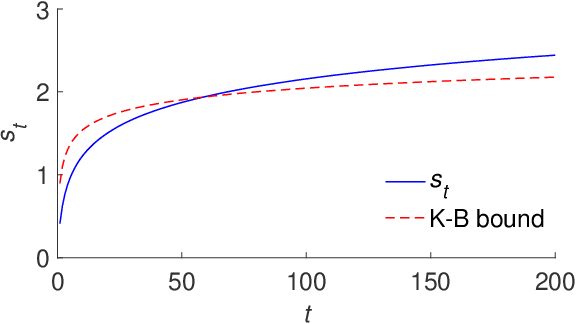
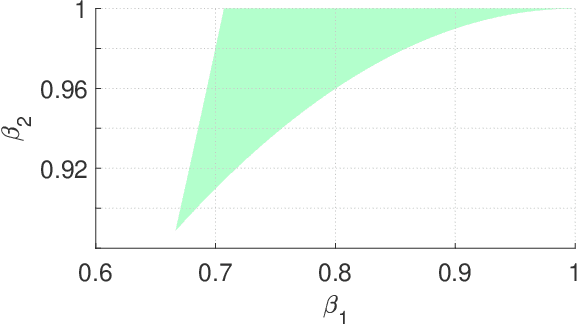
In 2014, Kingma and Ba published their Adam optimizer algorithm, together with a mathematical argument that was meant to help justify it. In 2018, Bock and colleagues reported that a key piece was missing from that argument $-$ an unproven lemma which we will call Bock's conjecture. Here we show that this conjecture is false, but a modified version of it does hold, and fills the gap in Bock's proof of convergence for Adam.
Deep Learning without Weight Transport
May 31, 2019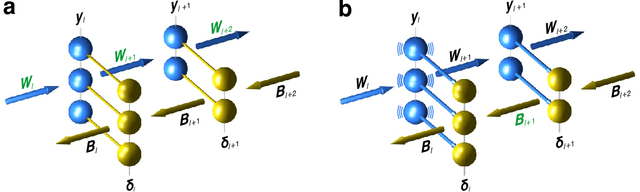
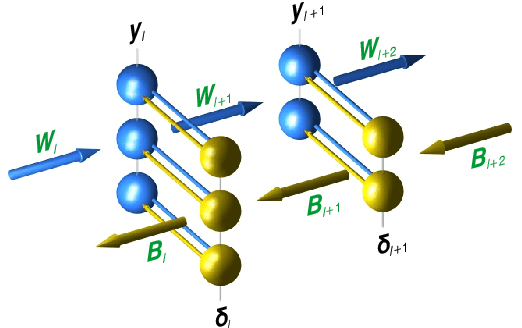
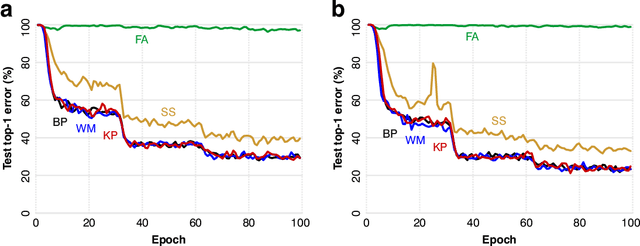
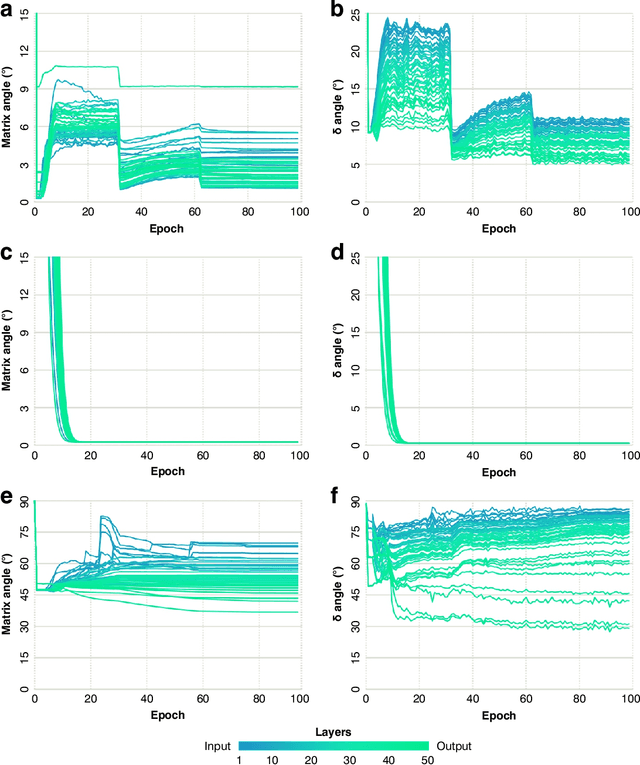
Current algorithms for deep learning probably cannot run in the brain because they rely on weight transport, where forward-path neurons transmit their synaptic weights to a feedback path, in a way that is likely impossible biologically. An algorithm called feedback alignment achieves deep learning without weight transport by using random feedback weights, but it performs poorly on hard visual-recognition tasks. Here we describe two mechanisms - a neural circuit called a weight mirror and a modification of an algorithm proposed by Kolen and Pollack in 1994 - both of which let the feedback path learn appropriate synaptic weights quickly and accurately even in large networks, without weight transport or complex wiring.Tested on the ImageNet visual-recognition task, these mechanisms outperform both feedback alignment and the newer sign-symmetry method, and nearly match backprop, the standard algorithm of deep learning, which uses weight transport.
Costate-focused models for reinforcement learning
Oct 03, 2018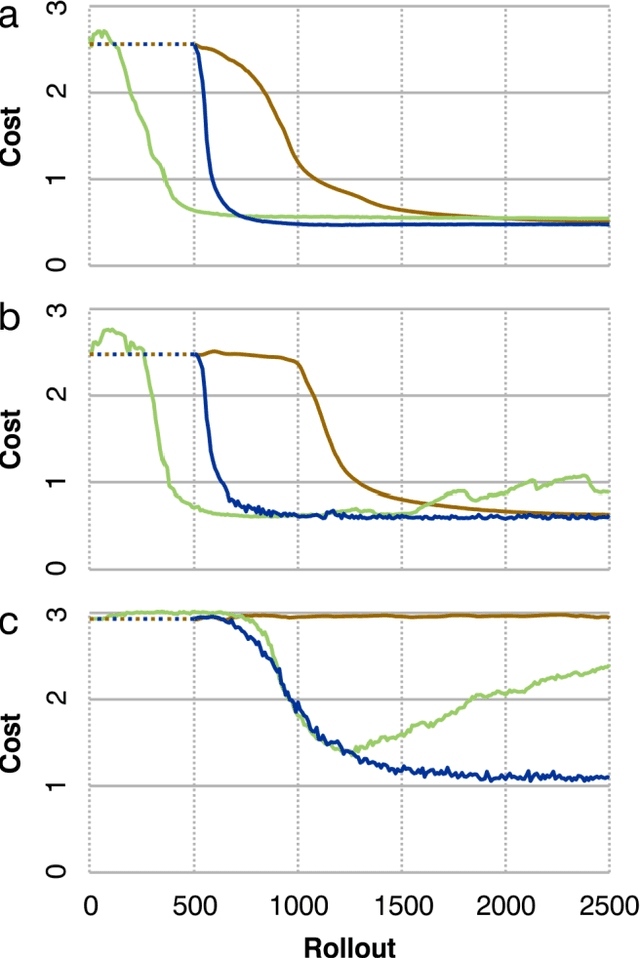
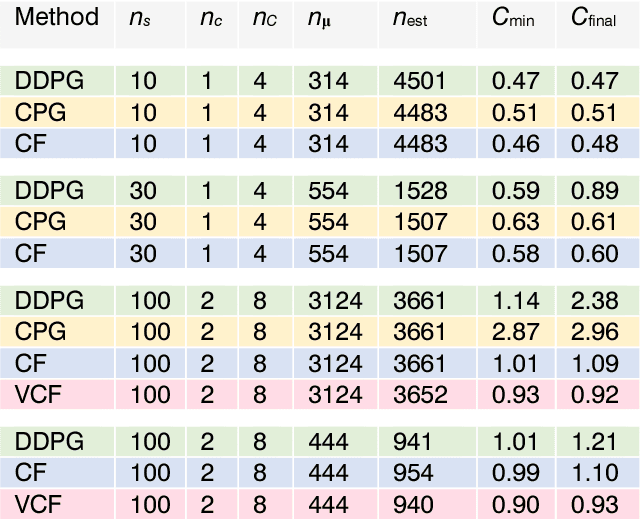
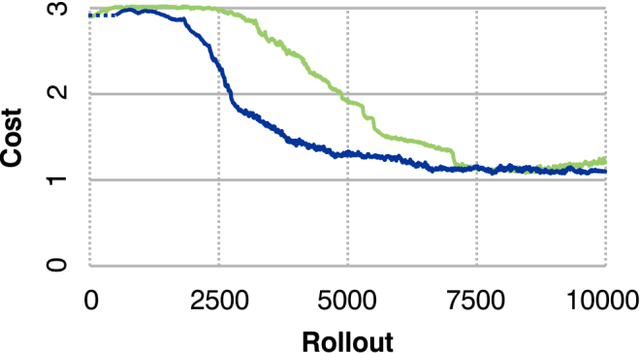
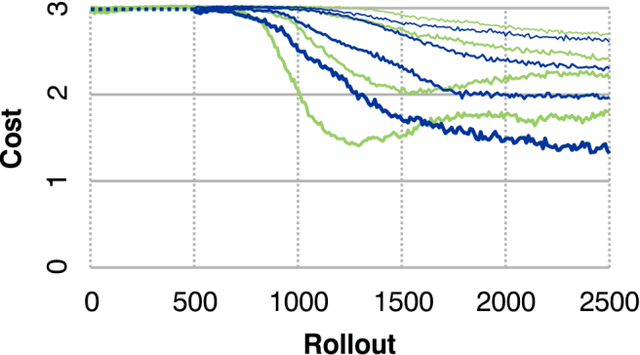
Many recent algorithms for reinforcement learning are model-free and founded on the Bellman equation. Here we present a method founded on the costate equation and models of the state dynamics. We use the costate -- the gradient of cost with respect to state -- to improve the policy and also to "focus" the model, training it to detect and mimic those features of the environment that are most relevant to its task. We show that this method can handle difficult time-optimal control problems, driving deterministic or stochastic mechanical systems quickly to a target. On these tasks it works well compared to deep deterministic policy gradient, a recent Bellman method. And because it creates a model, the costate method can also learn from mental practice.