 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCostate-focused models for reinforcement learning
Oct 03, 2018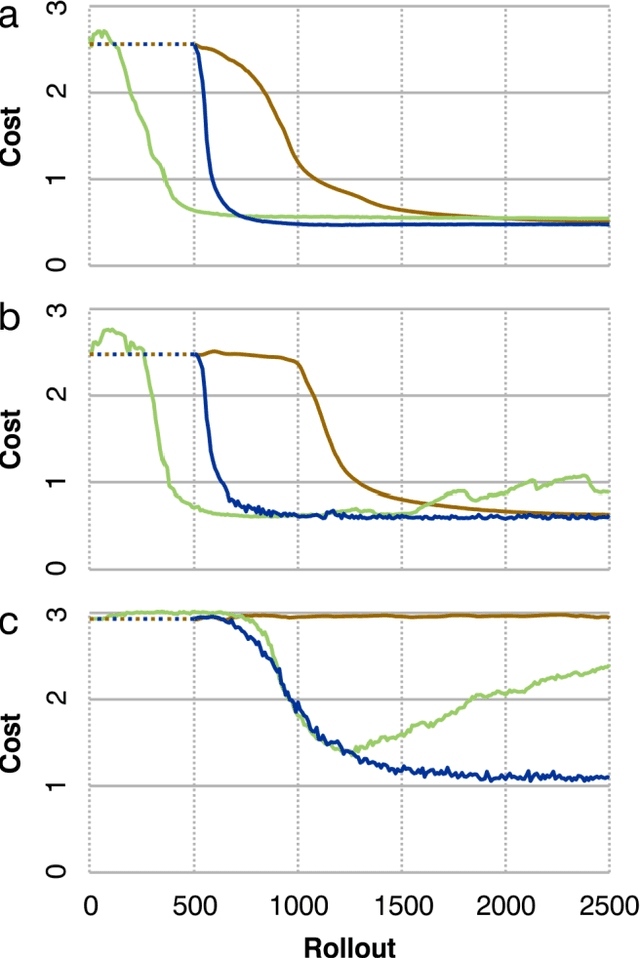
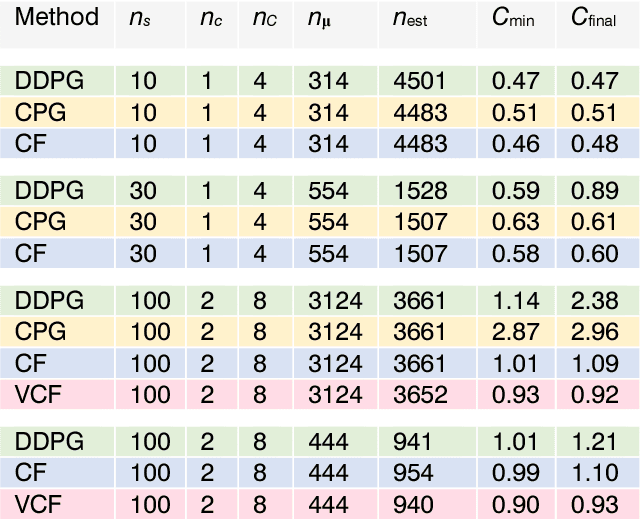
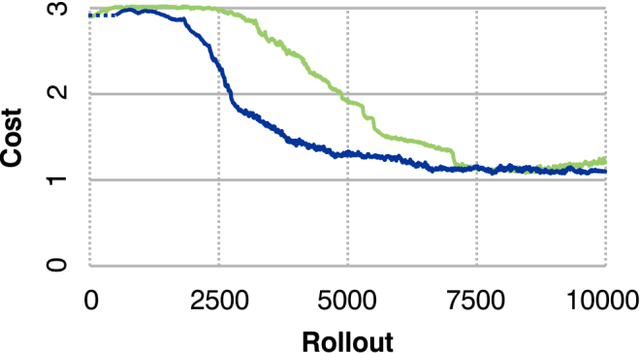
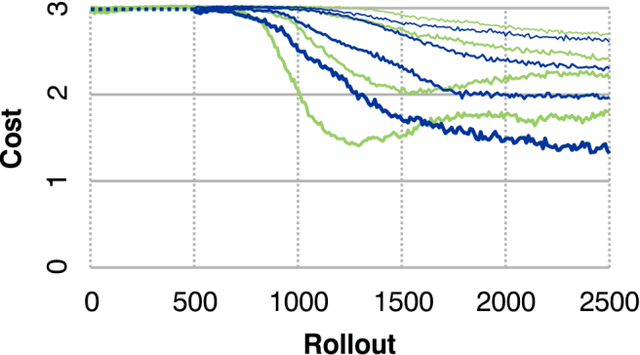
Many recent algorithms for reinforcement learning are model-free and founded on the Bellman equation. Here we present a method founded on the costate equation and models of the state dynamics. We use the costate -- the gradient of cost with respect to state -- to improve the policy and also to "focus" the model, training it to detect and mimic those features of the environment that are most relevant to its task. We show that this method can handle difficult time-optimal control problems, driving deterministic or stochastic mechanical systems quickly to a target. On these tasks it works well compared to deep deterministic policy gradient, a recent Bellman method. And because it creates a model, the costate method can also learn from mental practice.